Parallel WaveGAN (+ MelGAN & Multi-band MelGAN) implementation with Pytorch
![]()



Niels notes:
In order to edit the code using pipenv and pyenv-win, install both of them using py -m pip install pipenv and choco install pyenv-win
Ensure that $home/.pyenv/pyenv-win/bin and $home/.pyenv/pyenv-win/shims are on path.
Ensure that python 3.6.8 is installed by running pyenv install 3.6.8. And run pyenv local 3.6.8 and pipenv install to install the packages.
This repository provides UNOFFICIAL PWG, MelGAN, and MB-MelGAN implementations with Pytorch.
You can combine these state-of-the-art non-autoregressive models to build your own great vocoder!
Please check our samples in our demo HP.
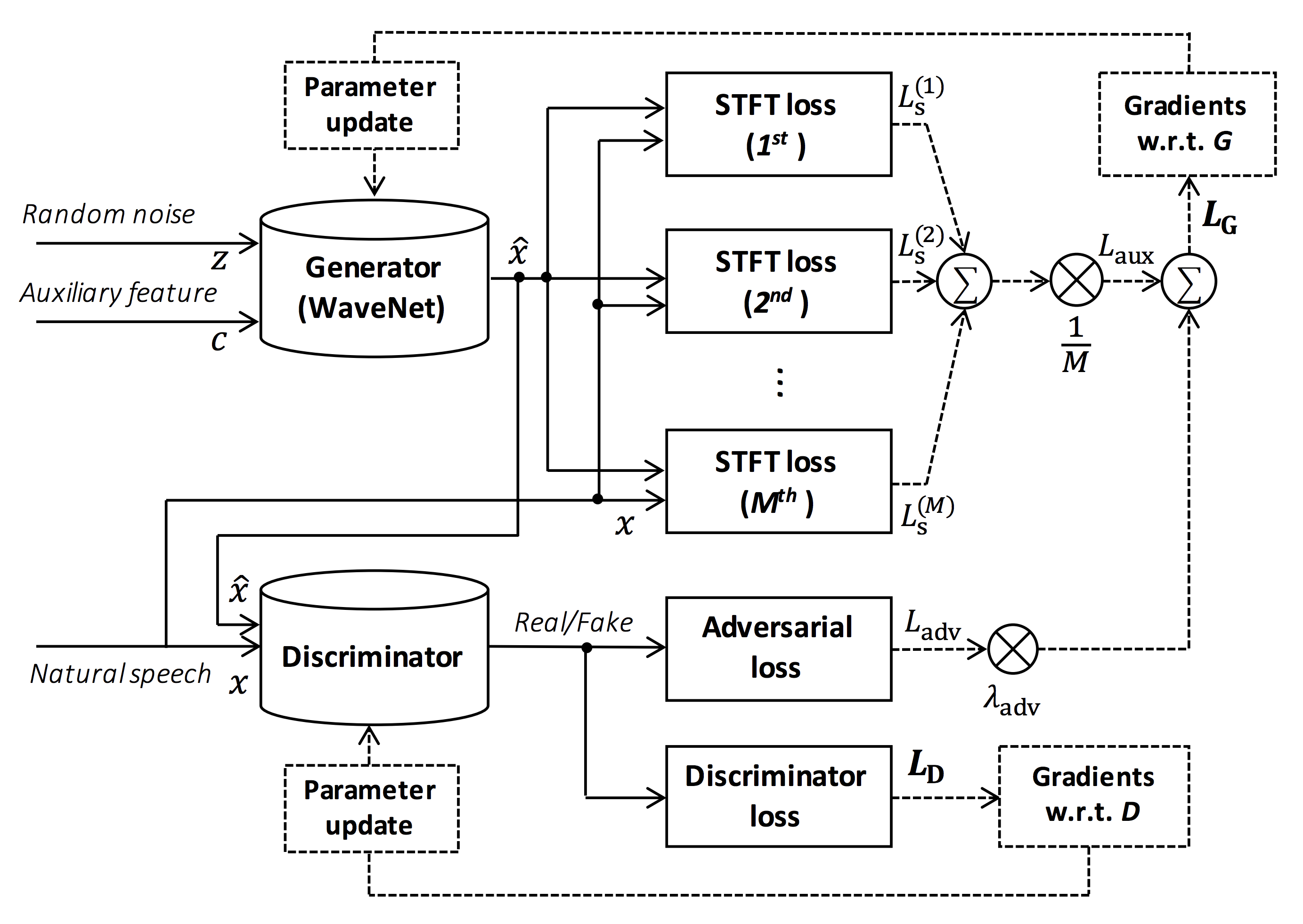
Source of the figure: https://arxiv.org/pdf/1910.11480.pdf
The goal of this repository is to provide real-time neural vocoder, which is compatible with ESPnet-TTS.
Also, this repository can be combined with NVIDIA/tacotron2-based implementation (See this comment).
You can try the real-time end-to-end text-to-speech demonstration in Google Colab!
- Real-time demonstration with ESPnet2
- Real-time demonstration with ESPnet1
What's new
- 2020/10/07 (New!) JSSS recipe is available!
- 2020/08/19 Real-time demo with ESPnet2 is available!
- 2020/05/29 VCTK, JSUT, and CSMSC multi-band MelGAN pretrained model is available!
- 2020/05/27 New LJSpeech multi-band MelGAN pretrained model is available!
- 2020/05/24 LJSpeech full-band MelGAN pretrained model is available!
- 2020/05/22 LJSpeech multi-band MelGAN pretrained model is available!
- 2020/05/16 Multi-band MelGAN is available!
- 2020/03/25 LibriTTS pretrained models are available!
- 2020/03/17 Tensorflow conversion example notebook is available (Thanks, @dathudeptrai)!
- 2020/03/16 LibriTTS recipe is available!
- 2020/03/12 PWG G + MelGAN D + STFT-loss samples are available!
- 2020/03/12 Multi-speaker English recipe egs/vctk/voc1 is available!
- 2020/02/22 MelGAN G + MelGAN D + STFT-loss samples are available!
- 2020/02/12 Support MelGAN's discriminator!
- 2020/02/08 Support MelGAN's generator!
Requirements
This repository is tested on Ubuntu 16.04 with a GPU Titan V.
- Python 3.6+
- Cuda 10.0+
- CuDNN 7+
- NCCL 2+ (for distributed multi-gpu training)
- libsndfile (you can install via
sudo apt install libsndfile-devin ubuntu) - jq (you can install via
sudo apt install jqin ubuntu) - sox (you can install via
sudo apt install soxin ubuntu)
Different cuda version should be working but not explicitly tested.
All of the codes are tested on Pytorch 1.0.1, 1.1, 1.2, 1.3.1, 1.4, 1.5.1, and 1.7.
Pytorch 1.6 works but there are some issues in cpu mode (See #198).
Setup
You can select the installation method from two alternatives.
A. Use pip
$ git clone https://github.com/kan-bayashi/ParallelWaveGAN.git
$ cd ParallelWaveGAN
$ pip install -e .
# If you want to use distributed training, please install
# apex manually by following https://github.com/NVIDIA/apex
$ ...Note that your cuda version must be exactly matched with the version used for the pytorch binary to install apex.
To install pytorch compiled with different cuda version, see tools/Makefile.
B. Make virtualenv
$ git clone https://github.com/kan-bayashi/ParallelWaveGAN.git
$ cd ParallelWaveGAN/tools
$ make
# If you want to use distributed training, please run following
# command to install apex.
$ make apexNote that we specify cuda version used to compile pytorch wheel.
If you want to use different cuda version, please check tools/Makefile to change the pytorch wheel to be installed.
Recipe
This repository provides Kaldi-style recipes, as the same as ESPnet.
Currently, the following recipes are supported.
- LJSpeech: English female speaker
- JSUT: Japanese female speaker
- JSSS: Japanese female speaker
- CSMSC: Mandarin female speaker
- CMU Arctic: English speakers
- JNAS: Japanese multi-speaker
- VCTK: English multi-speaker
- LibriTTS: English multi-speaker
- YesNo: English speaker (For debugging)
To run the recipe, please follow the below instruction.
# Let us move on the recipe directory
$ cd egs/ljspeech/voc1
# Run the recipe from scratch
$ ./run.sh
# You can change config via command line
$ ./run.sh --conf <your_customized_yaml_config>
# You can select the stage to start and stop
$ ./run.sh --stage 2 --stop_stage 2
# If you want to specify the gpu
$ CUDA_VISIBLE_DEVICES=1 ./run.sh --stage 2
# If you want to resume training from 10000 steps checkpoint
$ ./run.sh --stage 2 --resume <path>/<to>/checkpoint-10000steps.pklSee more info about the recipes in this README.
Speed
The decoding speed is RTF = 0.016 with TITAN V, much faster than the real-time.
[decode]: 100%|██████████| 250/250 [00:30<00:00, 8.31it/s, RTF=0.0156]
2019-11-03 09:07:40,480 (decode:127) INFO: finished generation of 250 utterances (RTF = 0.016).Even on the CPU (Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz 16 threads), it can generate less than the real-time.
[decode]: 100%|██████████| 250/250 [22:16<00:00, 5.35s/it, RTF=0.841]
2019-11-06 09:04:56,697 (decode:129) INFO: finished generation of 250 utterances (RTF = 0.734).If you use MelGAN's generator, the decoding speed will be further faster.
# On CPU (Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz 16 threads)
[decode]: 100%|██████████| 250/250 [04:00<00:00, 1.04it/s, RTF=0.0882]
2020-02-08 10:45:14,111 (decode:142) INFO: Finished generation of 250 utterances (RTF = 0.137).
# On GPU (TITAN V)
[decode]: 100%|██████████| 250/250 [00:06<00:00, 36.38it/s, RTF=0.00189]
2020-02-08 05:44:42,231 (decode:142) INFO: Finished generation of 250 utterances (RTF = 0.002).If you use Multi-band MelGAN's generator, the decoding speed will be much further faster.
# On CPU (Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz 16 threads)
[decode]: 100%|██████████| 250/250 [01:47<00:00, 2.95it/s, RTF=0.048]
2020-05-22 15:37:19,771 (decode:151) INFO: Finished generation of 250 utterances (RTF = 0.059).
# On GPU (TITAN V)
[decode]: 100%|██████████| 250/250 [00:05<00:00, 43.67it/s, RTF=0.000928]
2020-05-22 15:35:13,302 (decode:151) INFO: Finished generation of 250 utterances (RTF = 0.001).If you want to accelerate the inference more, it is worthwhile to try the conversion from pytorch to tensorflow.
The example of the conversion is available in the notebook (Provided by @dathudeptrai).
Results
Here the results are summarized in the table.
You can listen to the samples and download pretrained models from the link to our google drive.
| Model | Conf | Lang | Fs [Hz] | Mel range [Hz] | FFT / Hop / Win [pt] | # iters |
|---|---|---|---|---|---|---|
| ljspeech_parallel_wavegan.v1 | link | EN | 22.05k | 80-7600 | 1024 / 256 / None | 400k |
| ljspeech_parallel_wavegan.v1.long | link | EN | 22.05k | 80-7600 | 1024 / 256 / None | 1000k |
| ljspeech_parallel_wavegan.v1.no_limit | link | EN | 22.05k | None | 1024 / 256 / None | 400k |
| ljspeech_parallel_wavegan.v3 | link | EN | 22.05k | 80-7600 | 1024 / 256 / None | 3000k |
| ljspeech_melgan.v1 | link | EN | 22.05k | 80-7600 | 1024 / 256 / None | 400k |
| ljspeech_melgan.v1.long | link | EN | 22.05k | 80-7600 | 1024 / 256 / None | 1000k |
| ljspeech_melgan_large.v1 | link | EN | 22.05k | 80-7600 | 1024 / 256 / None | 400k |
| ljspeech_melgan_large.v1.long | link | EN | 22.05k | 80-7600 | 1024 / 256 / None | 1000k |
| ljspeech_melgan.v3 | link | EN | 22.05k | 80-7600 | 1024 / 256 / None | 2000k |
| ljspeech_melgan.v3.long | link | EN | 22.05k | 80-7600 | 1024 / 256 / None | 4000k |
| ljspeech_full_band_melgan.v1 | link | EN | 22.05k | 80-7600 | 1024 / 256 / None | 1000k |
| ljspeech_full_band_melgan.v2 | link | EN | 22.05k | 80-7600 | 1024 / 256 / None | 1000k |
| ljspeech_multi_band_melgan.v1 | link | EN | 22.05k | 80-7600 | 1024 / 256 / None | 1000k |
| ljspeech_multi_band_melgan.v2 | link | EN | 22.05k | 80-7600 | 1024 / 256 / None | 1000k |
| jsut_parallel_wavegan.v1 | link | JP | 24k | 80-7600 | 2048 / 300 / 1200 | 400k |
| jsut_multi_band_melgan.v2 | link | JP | 24k | 80-7600 | 2048 / 300 / 1200 | 1000k |
| csmsc_parallel_wavegan.v1 | link | ZH | 24k | 80-7600 | 2048 / 300 / 1200 | 400k |
| csmsc_multi_band_melgan.v2 | link | ZH | 24k | 80-7600 | 2048 / 300 / 1200 | 1000k |
| arctic_slt_parallel_wavegan.v1 | link | EN | 16k | 80-7600 | 1024 / 256 / None | 400k |
| jnas_parallel_wavegan.v1 | link | JP | 16k | 80-7600 | 1024 / 256 / None | 400k |
| vctk_parallel_wavegan.v1 | link | EN | 24k | 80-7600 | 2048 / 300 / 1200 | 400k |
| vctk_parallel_wavegan.v1.long | link | EN | 24k | 80-7600 | 2048 / 300 / 1200 | 1000k |
| vctk_multi_band_melgan.v2 | link | EN | 24k | 80-7600 | 2048 / 300 / 1200 | 1000k |
| libritts_parallel_wavegan.v1 | link | EN | 24k | 80-7600 | 2048 / 300 / 1200 | 400k |
| libritts_parallel_wavegan.v1.long | link | EN | 24k | 80-7600 | 2048 / 300 / 1200 | 1000k |
Please access at our google drive to check more results.
How-to-use pretrained models
Analysis-synthesis
Here the minimal code is shown to perform analysis-synthesis using the pretrained model.
# Please make sure you installed `parallel_wavegan`
# If not, please install via pip
$ pip install parallel_wavegan
# You can download the pretrained model from terminal
$ python << EOF
from parallel_wavegan.utils import download_pretrained_model
download_pretrained_model("<pretrained_model_tag>", "pretrained_model")
EOF
# You can get all of available pretrained models as follows:
$ python << EOF
from parallel_wavegan.utils import PRETRAINED_MODEL_LIST
print(PRETRAINED_MODEL_LIST.keys())
EOF
# Now you can find downloaded pretrained model in `pretrained_model/<pretrain_model_tag>/`
$ ls pretrain_model/<pretrain_model_tag>
checkpoint-400000steps.pkl config.yml stats.h5
# These files can also be downloaded manually from the above results
# Please put an audio file in `sample` directory to perform analysis-synthesis
$ ls sample/
sample.wav
# Then perform feature extraction -> feature normalization -> sysnthesis
$ parallel-wavegan-preprocess \
--config pretrain_model/<pretrain_model_tag>/config.yml \
--rootdir sample \
--dumpdir dump/sample/raw
100%|████████████████████████████████████████| 1/1 [00:00<00:00, 914.19it/s]
$ parallel-wavegan-normalize \
--config pretrain_model/<pretrain_model_tag>/config.yml \
--rootdir dump/sample/raw \
--dumpdir dump/sample/norm \
--stats pretrain_model/<pretrain_model_tag>/stats.h5
2019-11-13 13:44:29,574 (normalize:87) INFO: the number of files = 1.
100%|████████████████████████████████████████| 1/1 [00:00<00:00, 513.13it/s]
$ parallel-wavegan-decode \
--checkpoint pretrain_model/<pretrain_model_tag>/checkpoint-400000steps.pkl \
--dumpdir dump/sample/norm \
--outdir sample
2019-11-13 13:44:31,229 (decode:91) INFO: the number of features to be decoded = 1.
[decode]: 100%|███████████████████| 1/1 [00:00<00:00, 18.33it/s, RTF=0.0146]
2019-11-13 13:44:37,132 (decode:129) INFO: finished generation of 1 utterances (RTF = 0.015).
# you can find the generated speech in `sample` directory
$ ls sample
sample.wav sample_gen.wavDecoding with ESPnet-TTS model's features
Here, I show the procedure to generate waveforms with features generated by ESPnet-TTS models.
# Make sure you already finished running the recipe of ESPnet-TTS.
# You must use the same feature settings for both Text2Mel and Mel2Wav models.
# Let us move on "ESPnet" recipe directory
$ cd /path/to/espnet/egs/<recipe_name>/tts1
$ pwd
/path/to/espnet/egs/<recipe_name>/tts1
# If you use ESPnet2, move on `egs2/`
$ cd /path/to/espnet/egs2/<recipe_name>/tts1
$ pwd
/path/to/espnet/egs2/<recipe_name>/tts1
# Please install this repository in ESPnet conda (or virtualenv) environment
$ . ./path.sh && pip install -U parallel_wavegan
# You can download the pretrained model from terminal
$ python << EOF
from parallel_wavegan.utils import download_pretrained_model
download_pretrained_model("<pretrained_model_tag>", "pretrained_model")
EOF
# You can get all of available pretrained models as follows:
$ python << EOF
from parallel_wavegan.utils import PRETRAINED_MODEL_LIST
print(PRETRAINED_MODEL_LIST.keys())
EOF
# You can find downloaded pretrained model in `pretrained_model/<pretrain_model_tag>/`
$ ls pretrain_model/<pretrain_model_tag>
checkpoint-400000steps.pkl config.yml stats.h5
# These files can also be downloaded manually from the above resultsCase 1: If you use the same dataset for both Text2Mel and Mel2Wav
# In this case, you can directly use generated features for decoding.
# Please specify `feats.scp` path for `--feats-scp`, which is located in
# exp/<your_model_dir>/outputs_*_decode/<set_name>/feats.scp.
# Note that do not use outputs_*decode_denorm/<set_name>/feats.scp since
# it is de-normalized features (the input for PWG is normalized features).
$ parallel-wavegan-decode \
--checkpoint pretrain_model/<pretrain_model_tag>/checkpoint-400000steps.pkl \
--feats-scp exp/<your_model_dir>/outputs_*_decode/<set_name>/feats.scp \
--outdir <path_to_outdir>
# In the case of ESPnet2, the generated feature can be found in
# exp/<your_model_dir>/decode_*/<set_name>/norm/feats.scp.
$ parallel-wavegan-decode \
--checkpoint pretrain_model/<pretrain_model_tag>/checkpoint-400000steps.pkl \
--feats-scp exp/<your_model_dir>/decode_*/<set_name>/norm/feats.scp \
--outdir <path_to_outdir>
# You can find the generated waveforms in <path_to_outdir>/.
$ ls <path_to_outdir>
utt_id_1_gen.wav utt_id_2_gen.wav ... utt_id_N_gen.wavCase 2: If you use different datasets for Text2Mel and Mel2Wav models
# In this case, you must perform normlization at first.
# Please specify `feats.scp` path for `--feats-scp`, which is located in
# exp/<your_model_dir>/outputs_*_decode_denorm/<set_name>/feats.scp.
$ parallel-wavegan-normalize \
--skip-wav-copy \
--config pretrain_model/<pretrain_model_tag>/config.yml \
--stats pretrain_model/<pretrain_model_tag>/stats.h5 \
--feats-scp exp/<your_model_dir>/outputs_*_decode_denorm/<set_name>/feats.scp \
--dumpdir <path_to_dumpdir>
# In the case of ESPnet2, the denormalized generated feature can be found in
# exp/<your_model_dir>/decode_*/<set_name>/denorm/feats.scp.
$ parallel-wavegan-normalize \
--skip-wav-copy \
--config pretrain_model/<pretrain_model_tag>/config.yml \
--stats pretrain_model/<pretrain_model_tag>/stats.h5 \
--feats-scp exp/<your_model_dir>/decode_*/<set_name>/denorm/feats.scp \
--dumpdir <path_to_dumpdir>
# Normalized features dumped in <path_to_dumpdir>/.
$ ls <path_to_dumpdir>
utt_id_1.h5 utt_id_2.h5 ... utt_id_N.h5
# Then, decode normalzied features with the pretrained model.
$ parallel-wavegan-decode \
--checkpoint pretrain_model/<pretrain_model_tag>/checkpoint-400000steps.pkl \
--dumpdir <path_to_dumpdir> \
--outdir <path_to_outdir>
# You can find the generated waveforms in <path_to_outdir>/.
$ ls <path_to_outdir>
utt_id_1_gen.wav utt_id_2_gen.wav ... utt_id_N_gen.wavIf you want to combine these models in python, you can try the real-time demonstration in Google Colab!
- Real-time demonstration with ESPnet2
- Real-time demonstration with ESPnet1
References
- Parallel WaveGAN
- r9y9/wavenet_vocoder
- LiyuanLucasLiu/RAdam
- MelGAN
- descriptinc/melgan-neurips
- Multi-band MelGAN
Acknowledgement
The author would like to thank Ryuichi Yamamoto (@r9y9) for his great repository, paper, and valuable discussions.
Author
Tomoki Hayashi (@kan-bayashi)
E-mail: hayashi.tomoki<at>g.sp.m.is.nagoya-u.ac.jp