![]()
Colossal-AI: A Unified Deep Learning System for Big Model Era
Paper | Documentation | Examples | Forum | Blog
![]()

- Why Colossal-AI
- Features
- Parallel Training Demo
- Single GPU Training Demo
- Inference (Energon-AI) Demo
- Colossal-AI for Real World Applications
- Installation
- Use Docker
- Community
- Contributing
- Quick View
- Cite Us

Prof. James Demmel (UC Berkeley): Colossal-AI makes training AI models efficient, easy, and scalable.
Colossal-AI provides a collection of parallel components for you. We aim to support you to write your distributed deep learning models just like how you write your model on your laptop. We provide user-friendly tools to kickstart distributed training and inference in a few lines.
-
Parallelism strategies
- Data Parallelism
- Pipeline Parallelism
- 1D, 2D, 2.5D, 3D Tensor Parallelism
- Sequence Parallelism
- Zero Redundancy Optimizer (ZeRO)
-
Heterogeneous Memory Management
-
Friendly Usage
- Parallelism based on configuration file
-
Inference
-
Colossal-AI in the Real World
- Biomedicine: FastFold accelerates training and inference of AlphaFold protein structure
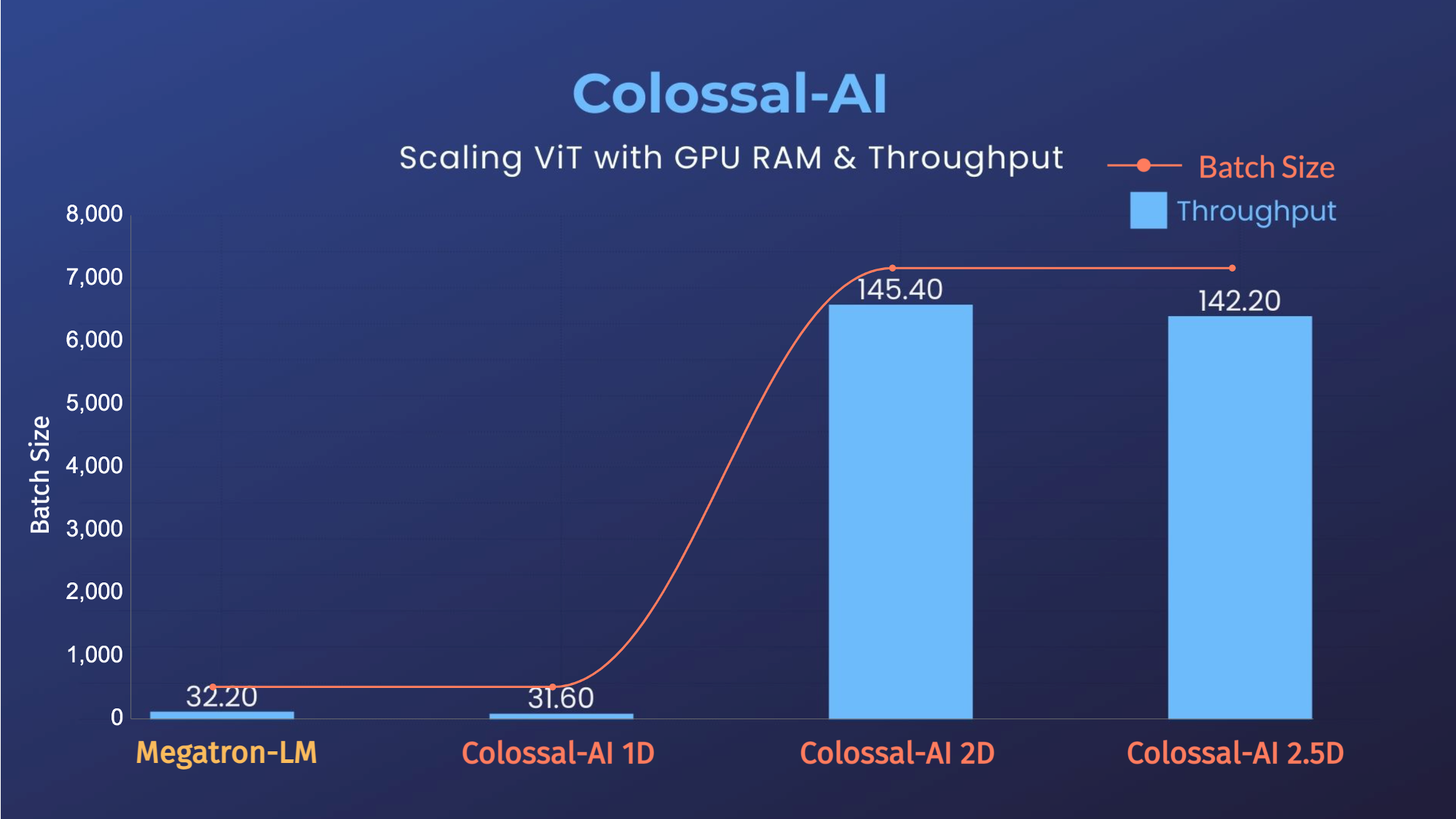
- 14x larger batch size, and 5x faster training for Tensor Parallelism = 64
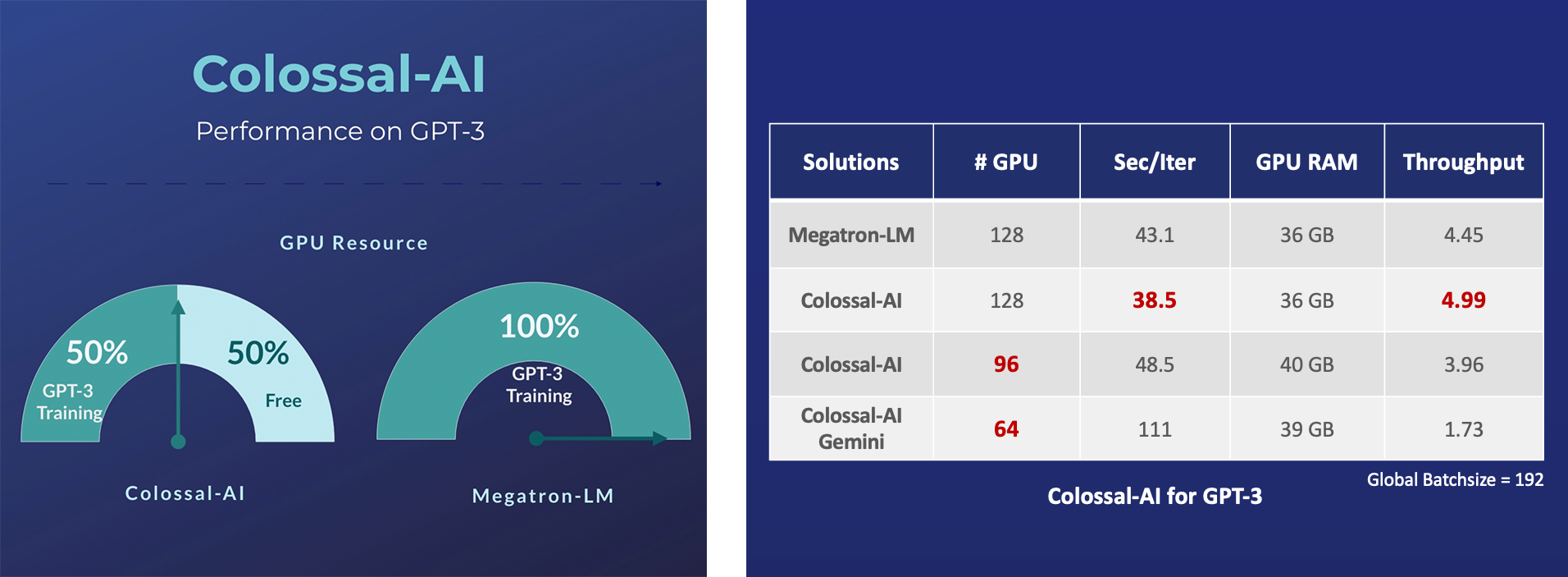
- Save 50% GPU resources, and 10.7% acceleration
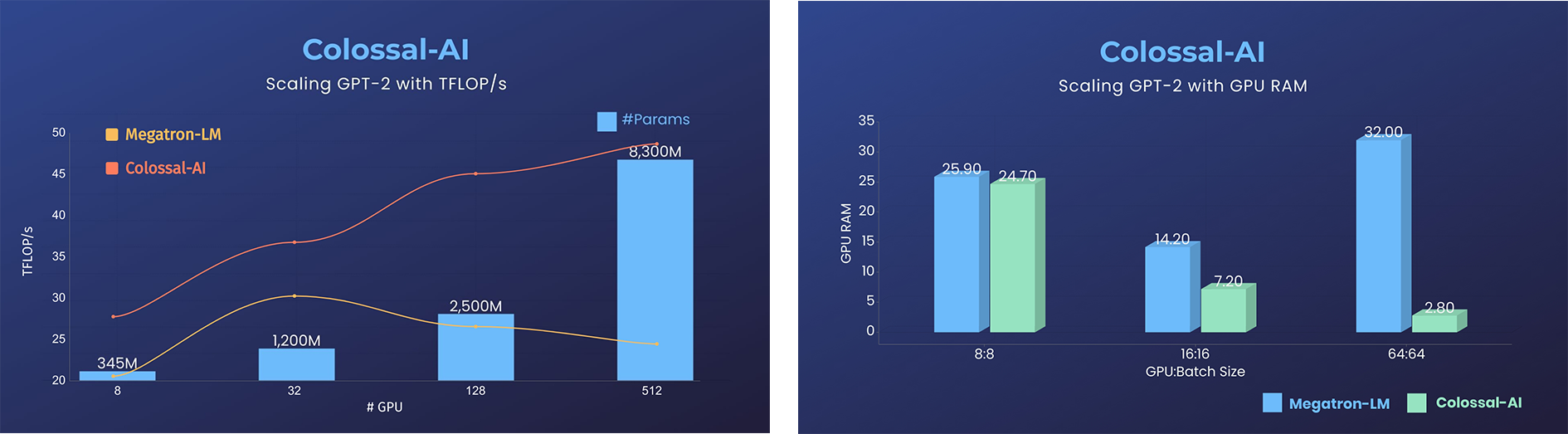
- 11x lower GPU memory consumption, and superlinear scaling efficiency with Tensor Parallelism
GPT-2.png)
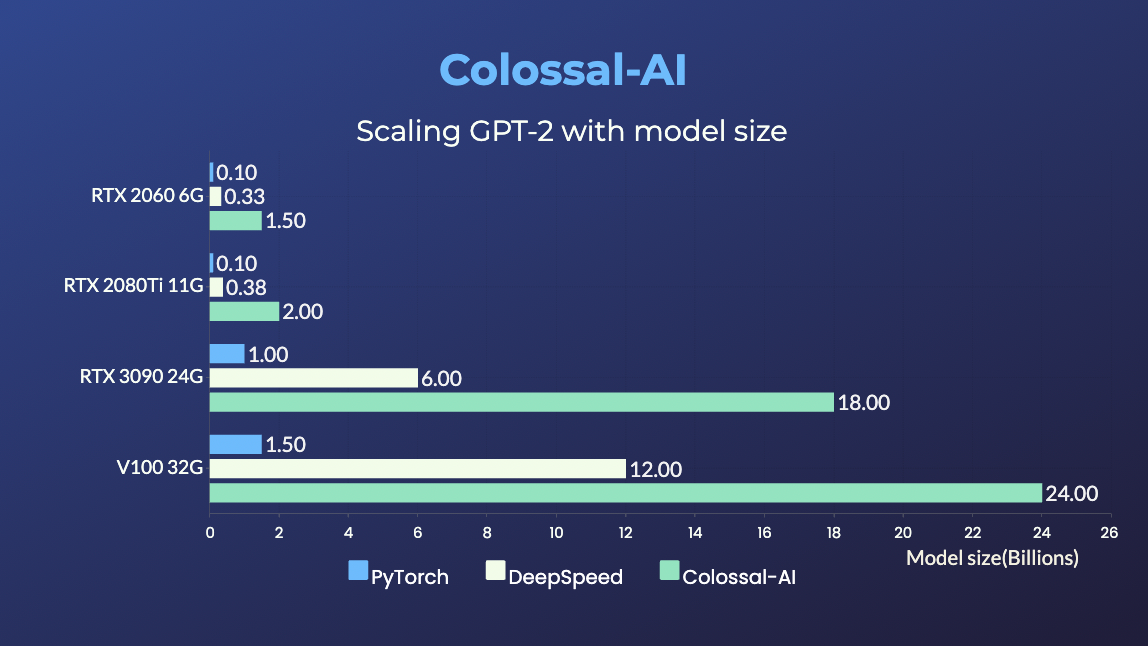
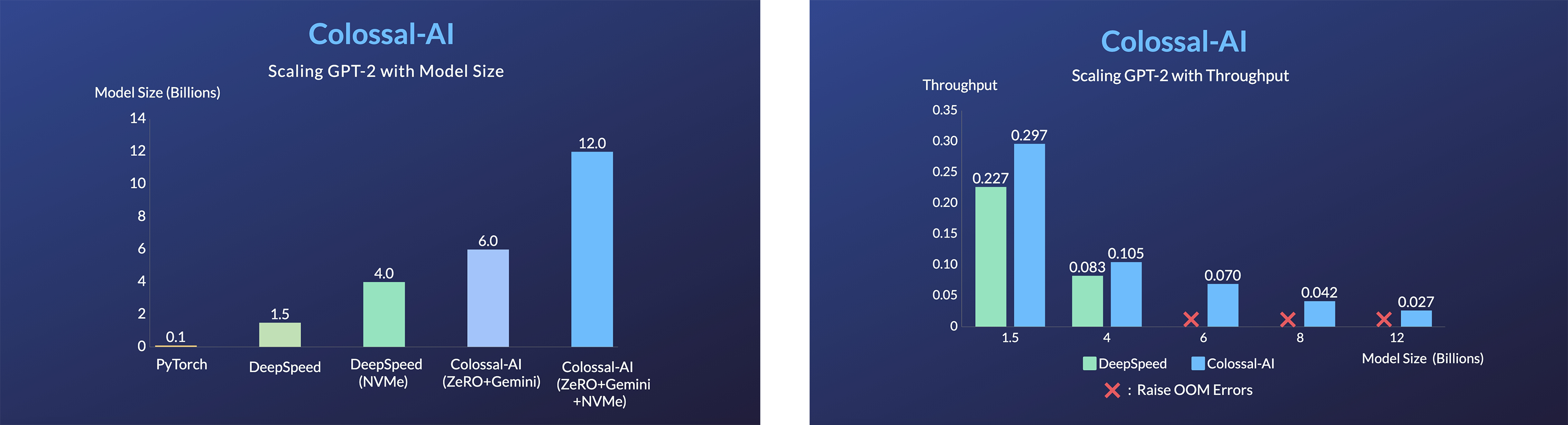
- 24x larger model size on the same hardware
- over 3x acceleration
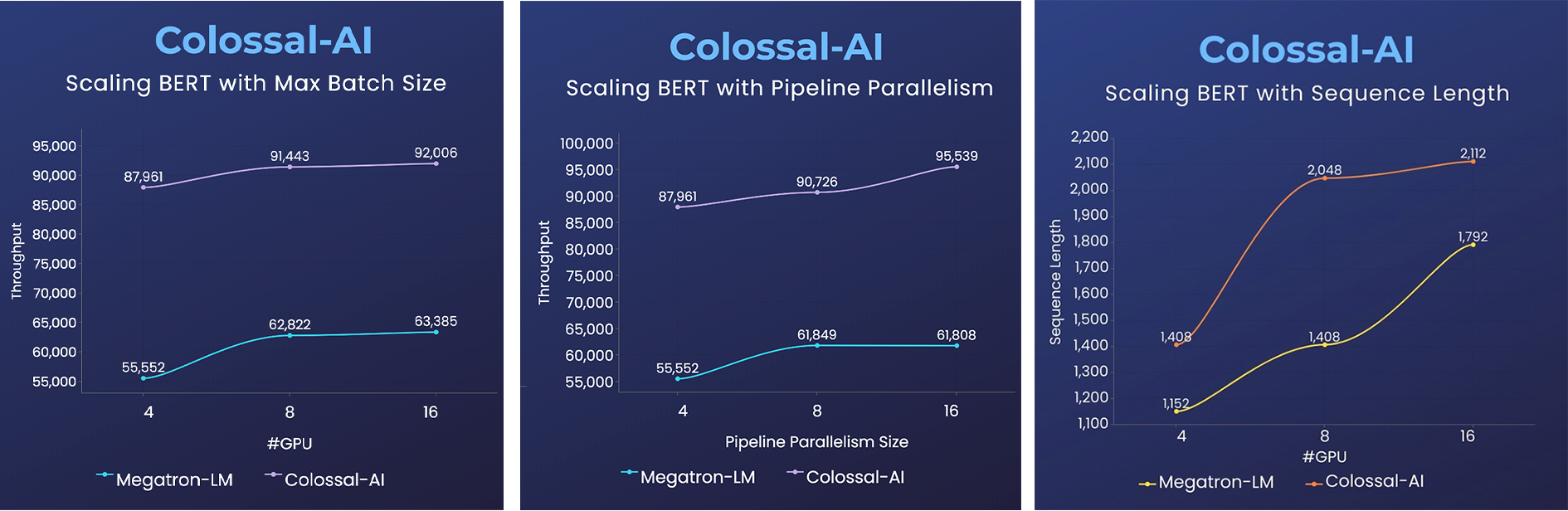
- 2x faster training, or 50% longer sequence length
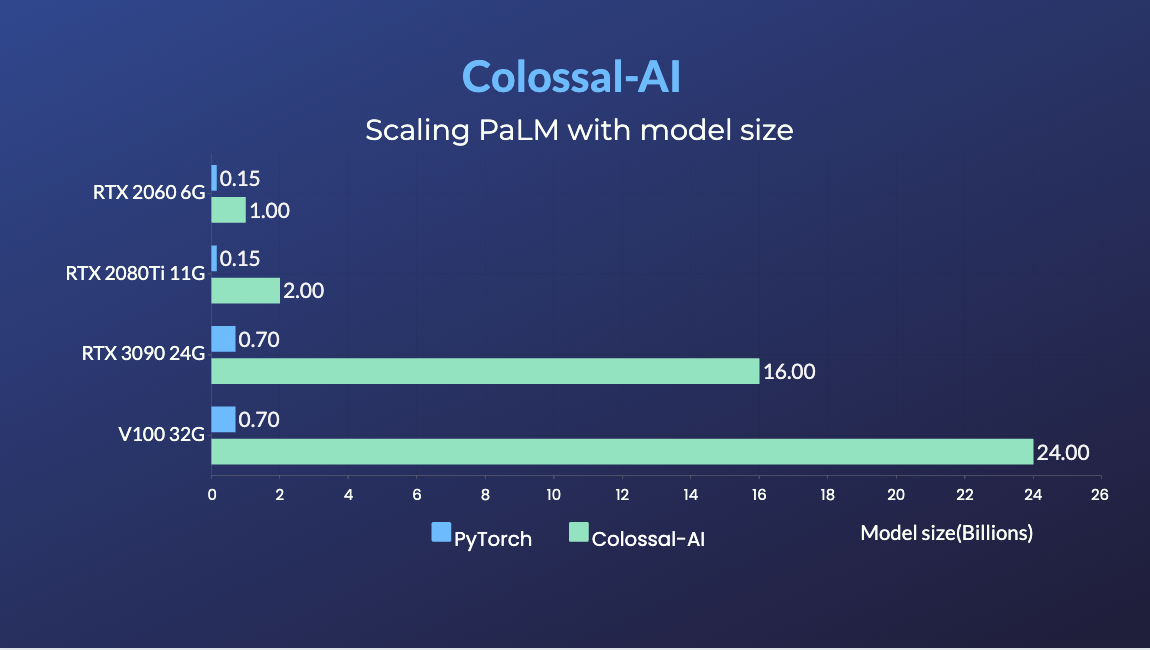
- PaLM-colossalai: Scalable implementation of Google's Pathways Language Model (PaLM).
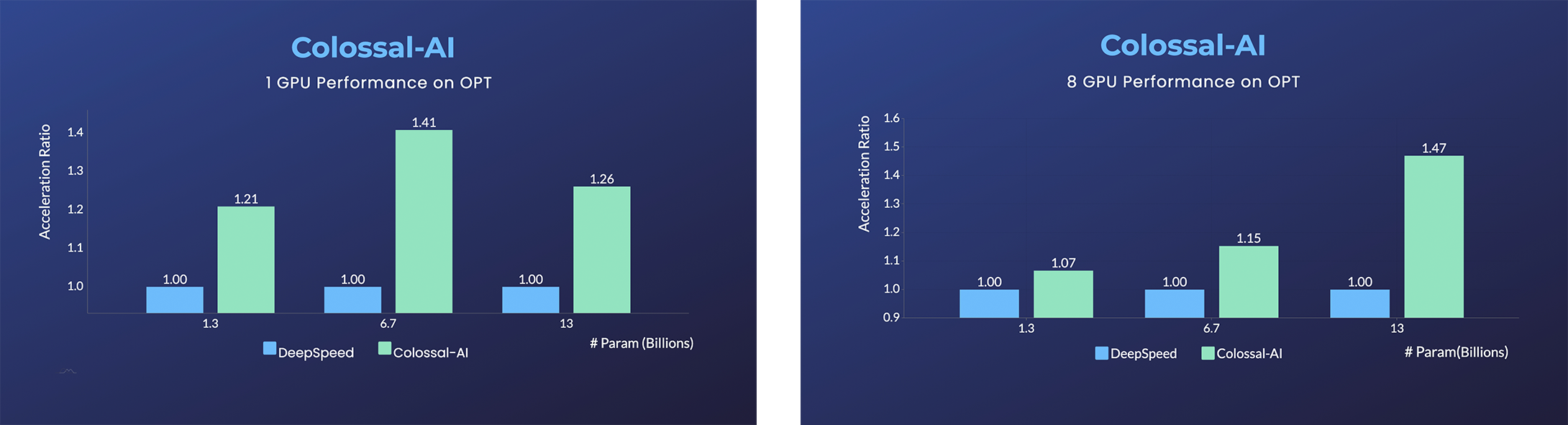
- Open Pretrained Transformer (OPT), a 175-Billion parameter AI language model released by Meta, which stimulates AI programmers to perform various downstream tasks and application deployments because public pretrained model weights.
- 45% speedup fine-tuning OPT at low cost in lines. [Example] [Online Serving]
Please visit our documentation and examples for more details.
- Cached Embedding, utilize software cache to train larger embedding tables with a smaller GPU memory budget.
- 20x larger model size on the same hardware
- 120x larger model size on the same hardware (RTX 3080)
- 34x larger model size on the same hardware
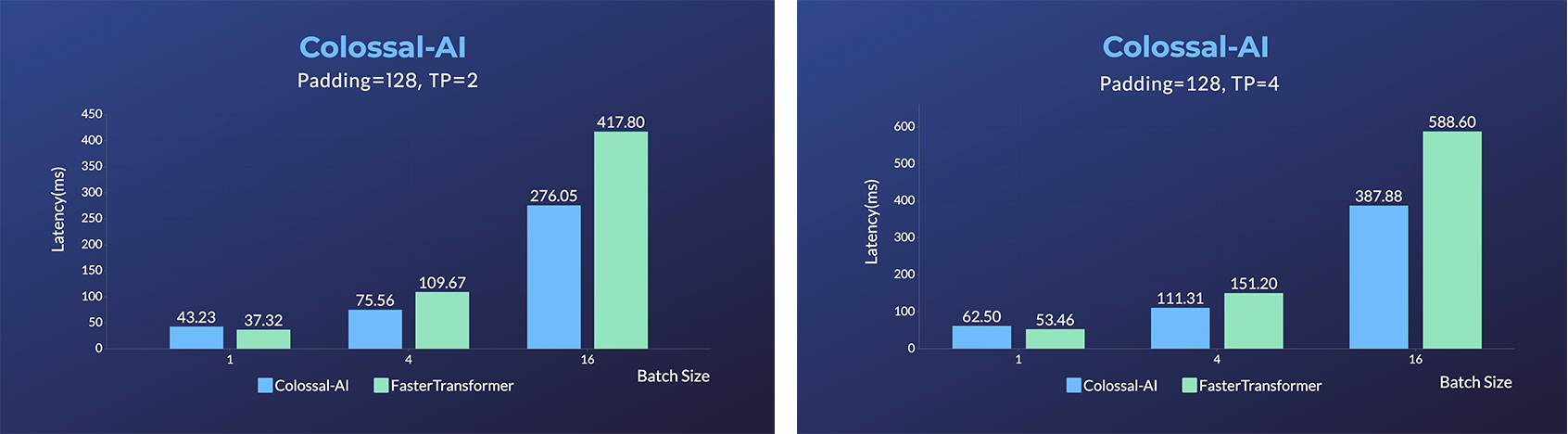
- Energon-AI: 50% inference acceleration on the same hardware

- OPT Serving: Try 175-billion-parameter OPT online services for free, without any registration whatsoever.
Acceleration of AlphaFold Protein Structure

- FastFold: accelerating training and inference on GPU Clusters, faster data processing, inference sequence containing more than 10000 residues.
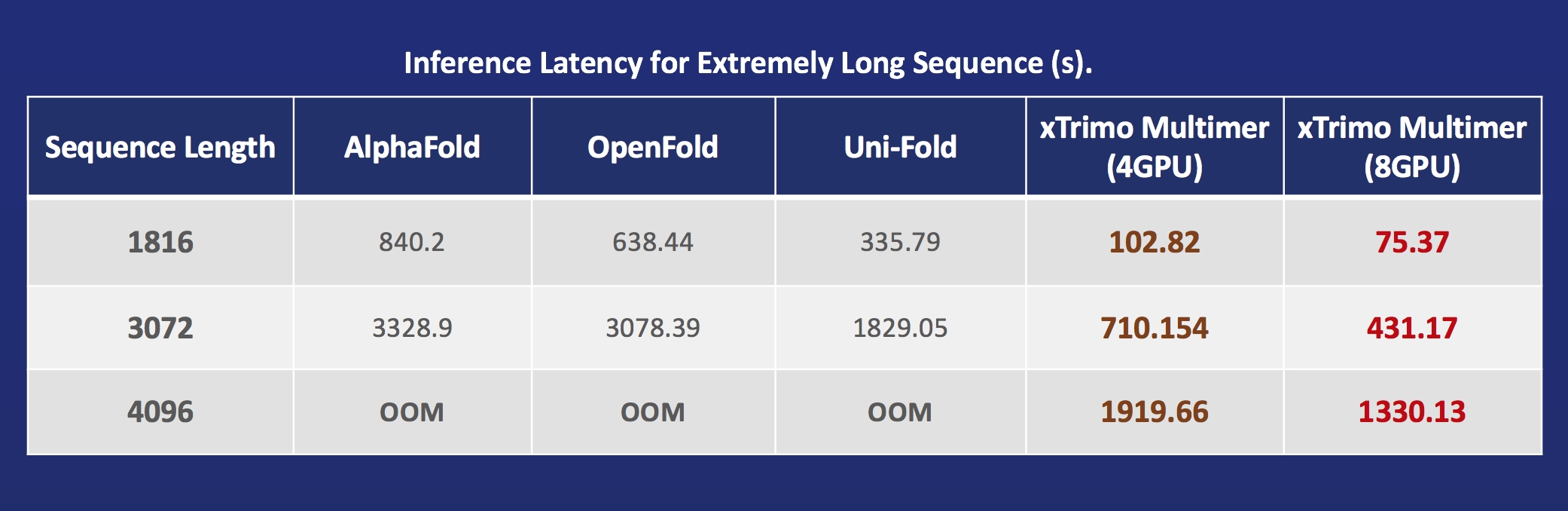
- xTrimoMultimer: accelerating structure prediction of protein monomers and multimer by 11x.
You can visit the Download page to download Colossal-AI with pre-built CUDA extensions.
The version of Colossal-AI will be in line with the main branch of the repository. Feel free to raise an issue if you encounter any problem. :)
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
# install dependency
pip install -r requirements/requirements.txt
# install colossalai
pip install .If you don't want to install and enable CUDA kernel fusion (compulsory installation when using fused optimizer):
NO_CUDA_EXT=1 pip install .You can directly pull the docker image from our DockerHub page. The image is automatically uploaded upon release.
Run the following command to build a docker image from Dockerfile provided.
Building Colossal-AI from scratch requires GPU support, you need to use Nvidia Docker Runtime as the default when doing
docker build. More details can be found here. We recommend you install Colossal-AI from our project page directly.
cd ColossalAI
docker build -t colossalai ./dockerRun the following command to start the docker container in interactive mode.
docker run -ti --gpus all --rm --ipc=host colossalai bashJoin the Colossal-AI community on Forum, Slack, and WeChat to share your suggestions, feedback, and questions with our engineering team.
If you wish to contribute to this project, please follow the guideline in Contributing.
Thanks so much to all of our amazing contributors!
![]()
The order of contributor avatars is randomly shuffled.
parallel = dict(
pipeline=2,
tensor=dict(mode='2.5d', depth = 1, size=4)
)zero = dict(
model_config=dict(
tensor_placement_policy='auto',
shard_strategy=TensorShardStrategy(),
reuse_fp16_shard=True
),
optimizer_config=dict(initial_scale=2**5, gpu_margin_mem_ratio=0.2)
)@article{bian2021colossal,
title={Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training},
author={Bian, Zhengda and Liu, Hongxin and Wang, Boxiang and Huang, Haichen and Li, Yongbin and Wang, Chuanrui and Cui, Fan and You, Yang},
journal={arXiv preprint arXiv:2110.14883},
year={2021}
}