final-project-twitterdemocraticpartydebates created by GitHub Classroom 591 Final Project Design
Project landing page: https://upenn-cit599.github.io/final-project-twitterdemocraticpartydebates/
Joanne Crean [ creanj@seas.upenn.edu ]
Juan Goleniowski [ juangole@seas.upenn.edu ]
Federica Pelzel [ fpelzel@seas.upenn.edu ]
Perform a sentiment analysis on tweets mentioning a user-specified keyword.
The user can decide what keyword they are interested in and the program will query Twitter to get relevant tweets, analyze these and then output the analysis results in the console and in a text file.
The analysis of tweets mentioning this keyword gives the average sentiment, most common positive and negative adjectives, and the states that have the lowest and highest average sentiment.
After some research, the Stanford CoreNLP toolkit was chosen for the sentiment analysis as it's freely available, could analyse short blocks of text, and uses a deep learning model that took whole sentences into account as opposed to assessing words individually. The sentiment score ranges from 0 - 4. Scores: 0 = very negative, 1= negative, 2 = neutral, 3 = positive, 4 = very positive.
A static analysis was also done to analyze tweets mentioning Democratic candidates around the 5th Democratic debate on November 20th 2019. This was to demonstrate the capacity of the program. A website was build to display the results: https://upenn-cit599.github.io/final-project-twitterdemocraticpartydebates/
- You will need a Maven plugin in your IDE to build the project.
- For Eclipse:
- Install the plugin: m2eclipse: https://www.vogella.com/tutorials/EclipseMaven/article.html#installation-and-configuration-of-maven-for-eclipse
- Build as Maven project: https://www.vogella.com/tutorials/EclipseMaven/article.html#execute-the-maven-build
- For Eclipse:
- The Runner class contains the main method for running the program in real-time.
- The DemDebate class was used to run the static analysis on previously collected tweets around the DemDebate on Nov 20th.
- Dependencies:
- Twitter4j library: You need to create a developer account and store a twitter4j.properties file in the main project folder.
 * Standford CoreNLP API: No credentials needed to use.
* Emoji Java library: No credentials needed to use
* These libraries will be automatically imported when the Maven project is built.
* Standford CoreNLP API: No credentials needed to use.
* Emoji Java library: No credentials needed to use
* These libraries will be automatically imported when the Maven project is built.

- Open the Runner class and run the main method.
- User input: (UserInteraction class)
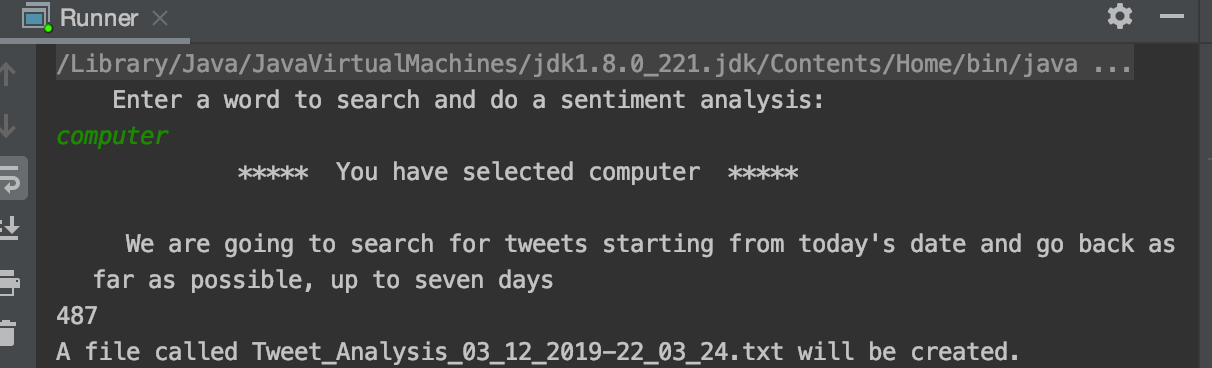
- User asked to enter keyword to search for.
- User told when the search begins.
- Query for keyword: (TwitterSearch class)
- Queries Twitter for Tweets mentioning the keyword, starting on today's date.
- Query limited to tweets in English.
- User will get up to 100 search results in every search. The number of searches that can be excuted is controlled by value in MAXSEARCHREQUESTS. Twitter allows up to 180 searches every 15 minutes.
- Analysis starts with today's tweets and then keeps scanning back over the last 7 days until it's reached the query limit.
- Store Tweets to text file.(SaveTweets class). The search result is stored in a file with a time stamped file name: Tweet_Analysis_dd_MM_yyyy-HH_mm_ss.
- Additionally, it creates a Tweet object for each Tweet from the results(Tweet class, SaveTweets class); the following variables are stored:
- Tweet ID
- User who created the tweet
- Number of followers that the user has
- User location as entered by the user
- Tweet text
- Tweet creation date
- Keyword used in search
- A zero to be populated by the influence score later
- Retweet count
- If the tweet is a retweet
- Geolocation from gps if available
- Add tweets to an ArrayList.
- Influence score is calculated for each Tweet and added to the Tweet object.(InfluenceScore class)
- Calculation based on the num of followers and number of retweets that the tweet had.
- Pre-process each tweet's text for sentiment analysis: (TweetProcessor class)
- Remove urls, hashtags, user mentions, underscores, hyphens, quotation marks, non-ascii characters.
- Replace emojis with their text equivalent (Emoji Java library).
- Get sentiment for tweet using Stanford CoreNlP: (NLPAnalyser class)
- Prepare tweet for analysis:
- Tokenise: break down the tweet into words.
- Ssplit: divide into sentences.
- Point-of-speech tag: tag each type of word, e.g. verb, noun.
- Parse: figure out the grammatical structure of the sentence.
- Get sentiment score for prepared tweet.
- Add sentiment score to Tweet object.
- Prepare tweet for analysis:
- Get the adjectives in the tweet, alongside their sentiment score and store in a HashMap.(NLPAnalyser class)
- Add to the tweet object
- Tweet location is analyzed based on user location and stored into state ArrayLists.(TweetsByState class)
- DataAnalysis class pulls in ArrayList of tweets to answer questions:
- What is the average sentiment for the tweets mentioning the keyword?
- What is the mode sentiment for the tweets mentioning the keyword?
- What is the median sentiment for the tweets mentioning the keyword?
- What percentage of tweets were negative and what percentage were positive?
- What are the most used positive adjectives in tweets mentioning the keyword?
- What are the most used negative adjectives in tweets mentioning the keyword?
- Which are the 5 states with the highest sentiment score?
- Which are the 5 states with the lowest sentiment score?
- Total number of tweets mentioning the keyword
- As the program runs the sentiment analysis, a summary for each tweet containing its sentiment scores and adjectives are listed. This gives the user an insight into the analysis as it's happening.
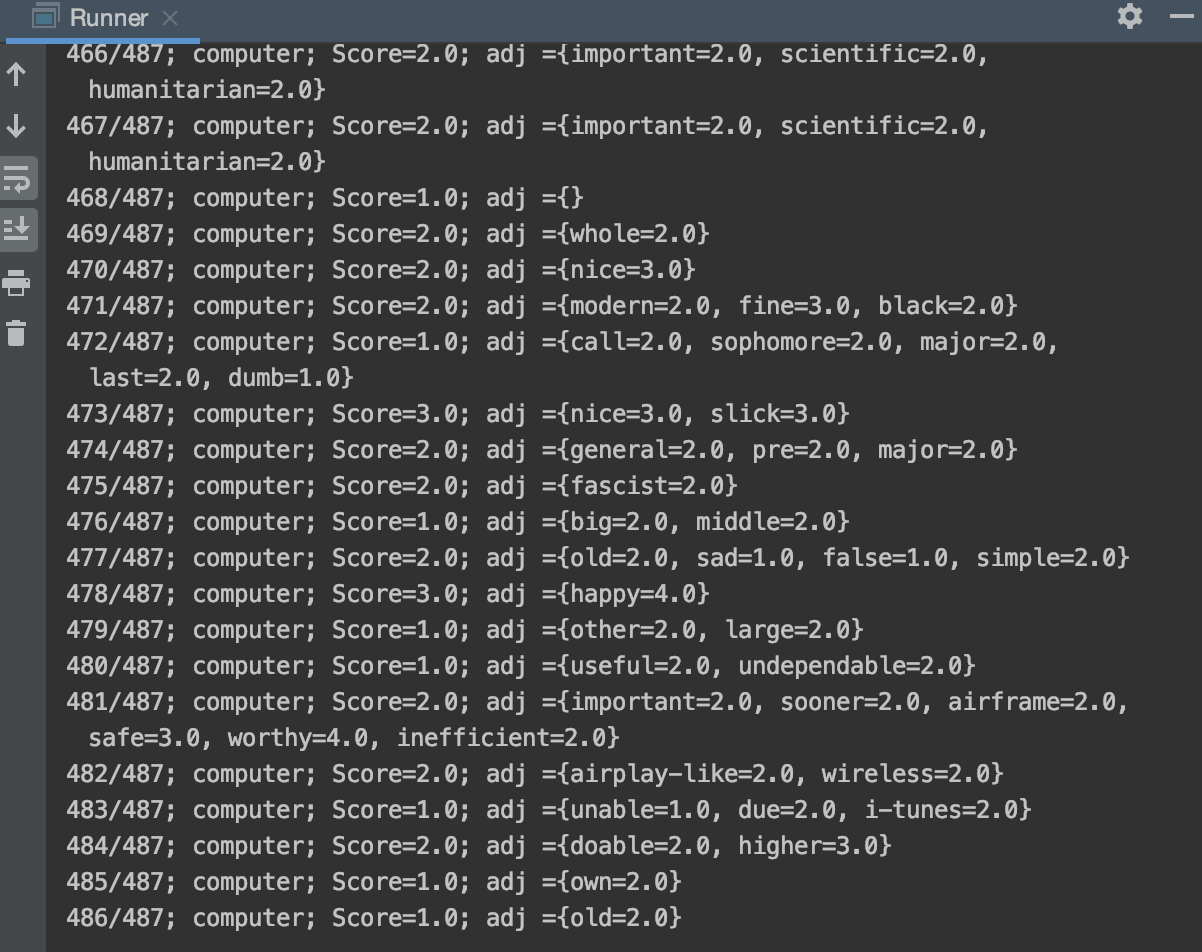
- Output results:(DataAnalysis class)
- Display in console
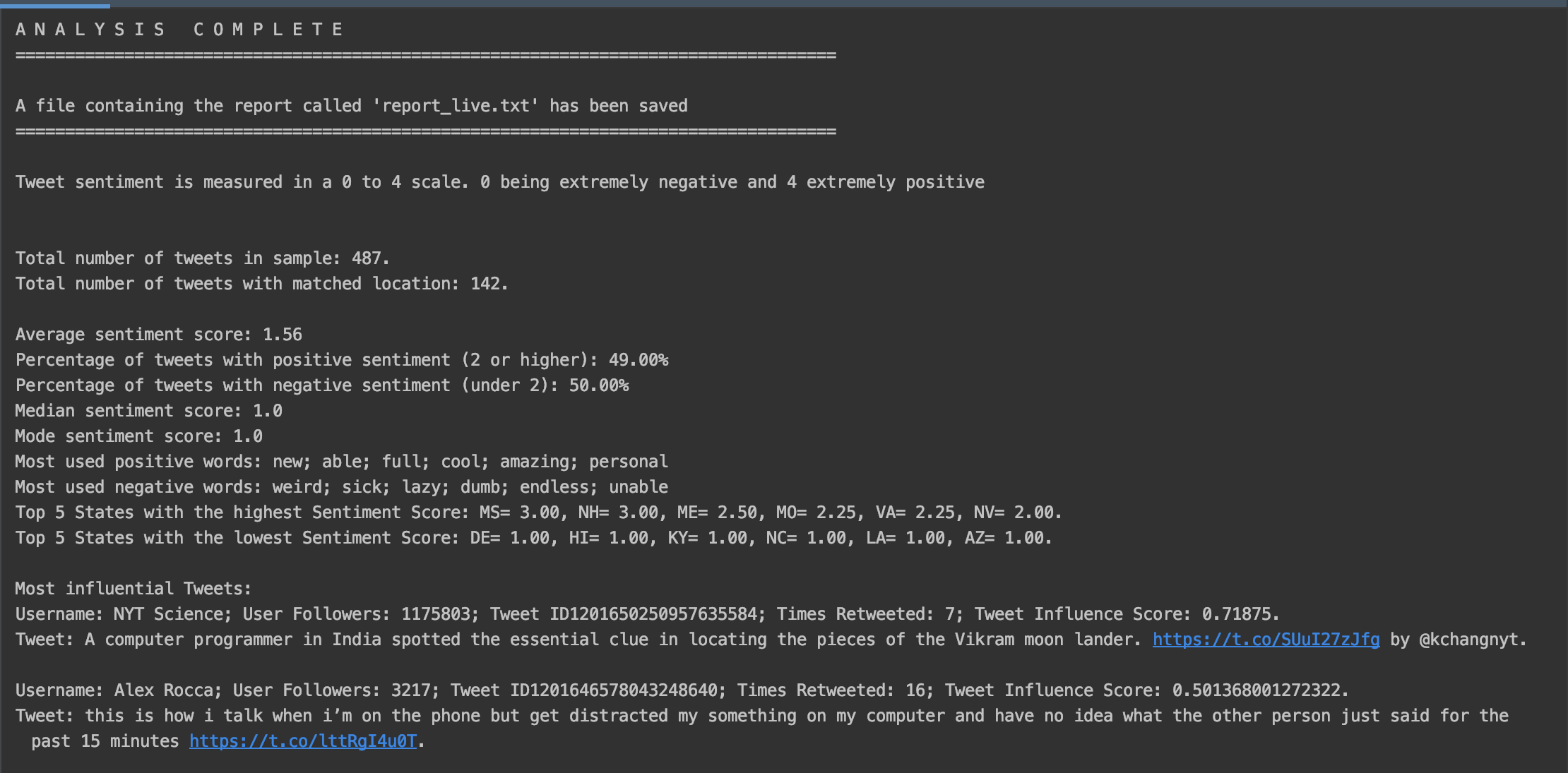
- Text file containing console report
- Text file containing the raw tweets that were retrieved.
- Display in console






- The static analysis was done on tweets gathered from Nov 13 - Nov 20th and Nov 22nd - 30th
- Batches of tweets were collected during this period and added to a TweetArchive.txt file.
- To test, run the DemDebate class and when prompted to type a filename type "TweetArchive_small.txt". This is a smaller file with a sample of around 500 tweets that allows for a reduced analysis.
- Batches of tweets were collected during this period and added to a TweetArchive.txt file.
- The DemDebate class takes in a text file of tweets and runs debate specific analysis from it.
- Takes in file and parses each row into a Tweet object.
- ArrayList of tweets is created for each candidate.
- Tweets are analysed for sentiment and given influence score, sentiment score and adjectives, as described under the real- time running section, steps 5-10.
- Tweet location is analyzed using natural language sorting and stored into state ArrayLists.(TweetsByState class)
- Analysis is run at the candidate level include state analysis.(DataAnalysis class)
- For the analysis of tweets around the debate, the following questions were answered for tweets mentioning each candidate:
- Total number of tweets
- Number of tweets with matched location
- What is the average sentiment of the tweets for this candidate?
- What is the median sentiment of the tweets for this candidate?
- What is the mode sentiment of the tweets for this candidate?
- What are the most used positive adjectives in tweets mentioning the candidate?
- What are the most used negative adjectives in tweets mentioning the candidates?
- Which are the 5 states with the highest sentiment score?
- Which are the 5 states with the lowest sentiment score?
- Output results:
- Output folder:
- DataByStates.csv
- DataByCandidate.csv
- report.txt (a txt report with the console output)
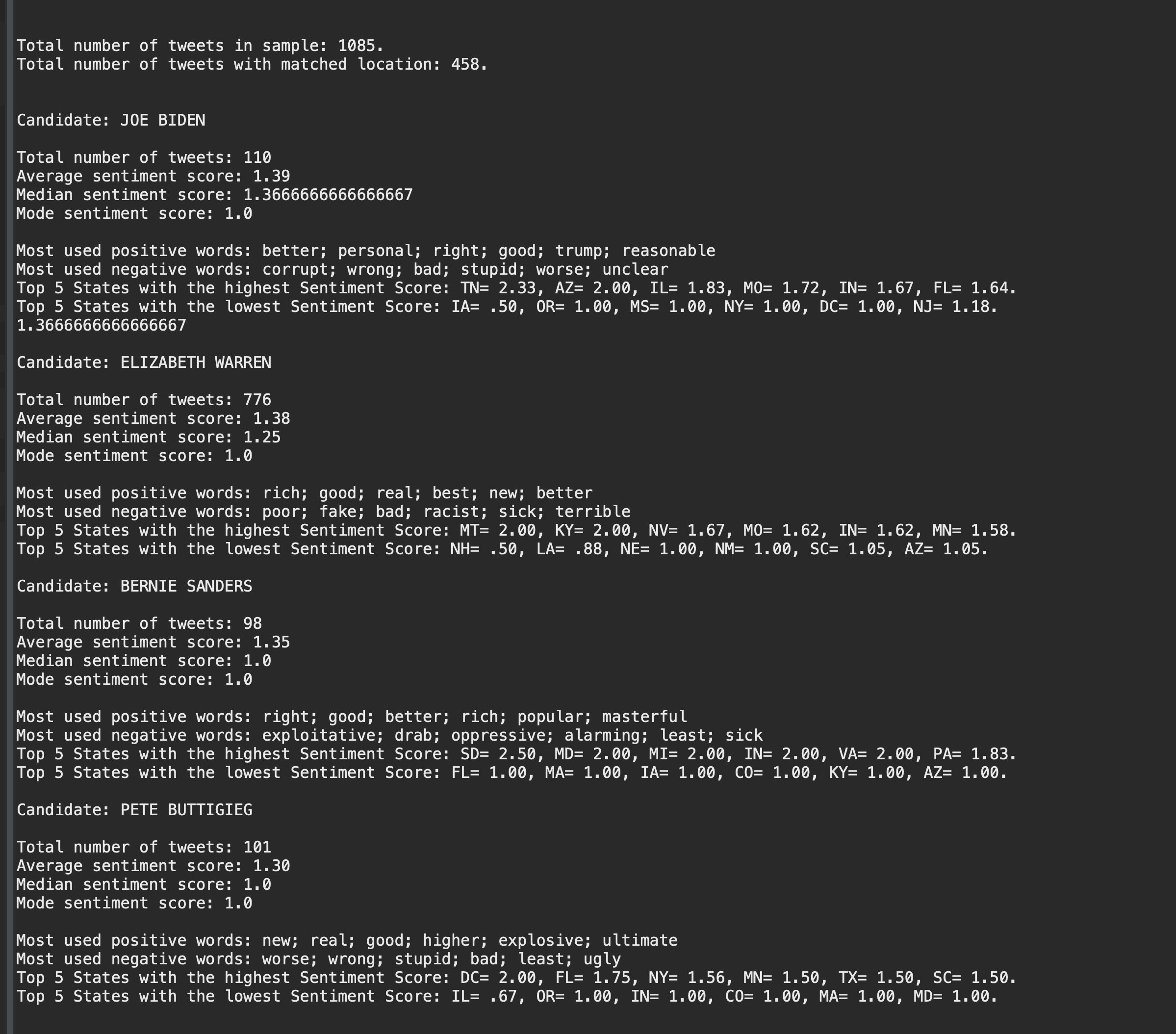
- Static analysis in console.
- Website: https://upenn-cit599.github.io/final-project-twitterdemocraticpartydebates/
- The website gives an overview of each candidate and some summary statistics.
- The interactive heatmap can be used to visualise the sentiment for candidates in certain states.
- The graphs on the right can be manipulated to filter what is visible on the heatmap.
- Output folder:




- Tweet: defines tweet object
- UserInteraction: takes user input during real-time running of the program
- TwitterSearch: queries Twitter for tweets
- SaveTweets: saves tweets into a text file and into an arraylist of tweet objects
- InfluenceScore: calculates influence score for a tweet based on followers and retweets
- TweetProcessor: prepares a tweet's text for sentiment analysis
- NLPAnalyser: runs a tweet through a natural linguistic processing pipeline and gets it's sentiment, get adjectives in tweet and their sentiment
- TweetsByState: divides tweets into arraylists based on the state that the sender was located
- DataAnalysis: methods to analyze tweets
- Runner: main method when the program is run in real-time
- DemDebate: main method for the static analysis around the DemDebate
- index.html: code for webpage
- We are using a free Twitter account so:
- The Twitter API will only give data for the last seven days.
- The Twitter API will only return 100 tweets for a search.
- The Twitter API will only allow 180 searches every 15 minutes.
- Stanford CoreNLP API was trained on movie reviews so may not be as accurate for tweets.
- Tweets often have slang and misspellings that cannot be reliably analyzed.
- Visual representation of results in real-time.
- Train our own NLP model on Tweets to get more accurate results.
- Use a paid Twitter account to get more data back for analysis.
- Expand the analysis.
- Stanford CoreNLP API: https://stanfordnlp.github.io/CoreNLP/index.html
- [https://towardsdatascience.com/sentiment-analysis-for-text-with-deep-learning-2f0a0c6472b5]
- Twitter4j API: http://twitter4j.org/en/
- Emoji java library :https://github.com/vdurmont/emoji-java