- 比赛介绍
- 数据集分析
- 模型介绍
- 模型训练
- 个人Trick
- 代码使用
- 总结
本人的专业为机械工程,研究方向为机械数据的异常检测,之前未曾参加过NLP方面的竞赛。可以说本人是这个方向的小白了,但是作为一个小白,通过1周左右的时间学习与训练BERT,1周时间学习开源代码与调参,很快在a榜取得并长期保持Top2的成绩,这一部分来自于本人较强的学习能力,另一部分则源于BERT这类模型强势。后面我将对这次比赛的细节进行详细的说明,希望能给大家带来一些启发。
文本匹配(text matching)技术广泛应用于信息检索、智能问答、对话等业务场景。尽管当前该技术已经相对有了长足的进步,但是随着领域的拓展,标注数据的缺乏,以及用户描述上的多样性,如何精准的匹配用户意图,变得越来越困难。随着5G时代的应用与发展,文本匹配技术应用越来越广泛,要求越来越高。
给定一定数量的标注语料和大量的未标注语料,要求选手设计算法和模型预测给定句对语义层面的关系,实现精准匹配: (1)相似(label=1); (2)不相似(label=0)。
所有文本数据都经过清洗与脱敏处理,被统一分词并编码成词表ID序列。 数据共包含3个txt文件,详细信息如下: (1)train.txt:训练集,每一行对应一条训练样本,约25万条。包含有三个字段,分别为text_a、text_b和label,字段之间由Tab键(\t)分隔; (2)test.txt:测试集,约1.2万条。数据格式同train.txt,但不包含label; (3)corpus.txt:无监督数据集,文件大小约2G,一行表示一篇文档的分词结果。由选手自行选择是否使用以及如何使用。 训练数据样例:2 5 10 5 200\t5 40 72 99 56\t0 (其中2 5 10 5 200为text_a,5 40 72 99 56为text_b,0为label) 无监督数据样例:2 5 10 5 300 7 30 5 400 5 60 8 300 5 60 5 700 9 30 5 500
不论是在这个比赛之前,还是这个比赛之后,国内外竞赛平台都有很多类似题目,比如:
- Kaggle Quora
- 天池 CIKM
- 蚂蚁金服
- 第三届魔镜杯
虽然部分比赛数据是未脱敏的,但我从开源代码中还是学到了很多
其中训练集25万条,正例(label=1)14万多条,负例(label=0)10万多条,样本还算均衡。测试集12500条。
本次比赛使用了脱敏数据,所有原始文本信息都被编码成数字序列。
初步对数据集进行分析,发现该数据集有三个特点:
- 正负样本相对均衡
- 句子较短,最长60多个字
- 存在较多重复样本和错标样本
无监督数据集中,共有83万条文档,根据词频统计,出现最多的3个数字为3,0,4。一般来说,在中文数据集中,句号的出现频率往往是第二,屈于逗号之下,因此此处假定3为逗号,0为句号。
但是,通过分析训练集与测试集,可以发现0多出现于句子倒数第二的位置或正数第二的位置,不符合句号出现的规律。对训练集与测试集进行词频统计,可以发现其中没有3,4出现。因此可以断定,3是逗号,4是句号。
判断出了句号为4,现在可以通过.split(" 4 ")将每篇文档分割为多个语句,组织为BERT预训练数据的样式了!最终的数据大概为1400万条语句。
由于目前BERT的火爆,所以本次比赛主要使用了BERT类模型。受限于硬件,我选择了ALBERT的small模型,如果你硬件条件较好或有充足时间,可以尝试BERT的small模型,应该可以取得更好的成绩
BERT在2018年提出,当时引起了爆炸式的反应,因为从效果上来讲刷新了非常多的记录,之后基本上开启了这个领域的飞速的发展。
BERT本质上是一个两段式的NLP模型。第一个阶段叫做:Pre-training,通过大规模无监督预料训练获得的模型,可以获取文本动态字符级语义embedding,简单地可以视为加强版的字符级word2vec。实际上由于bert预训练阶段在Masked LM之外的另一个pre-training任务就是Next Sentence Prediction,即成对句子构成的句子级问题,所以用BERT做文本匹配是有天然优势的。
第二个阶段叫做:Fine-tuning,利用预训练好的语言模型,完成具体的NLP下游任务,NLP下游任务下游任务多种多样,NLP在多种任务中当时都取得了SOTA的效果,其中之一就是文本匹配任务,只需要直接输入分割好的句子对就可以直接获取匹配结果。
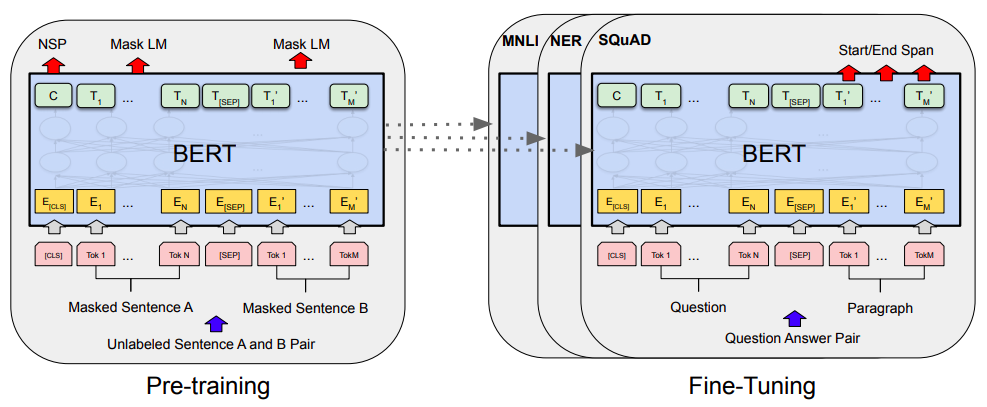
当然除了直接使用bert的句对匹配之外,理论上还可以只用bert来对每个句子求embedding,之后再通过向Siamese Network这样的经典模式去求相似度也可以。但从实操来说是不可取的,使用bert获取embedding后再去接复杂的交互计算,整个模型会非常大,训练时耗也会很长,不适于工业常见。
之前的BERT为什么效果好? 这绝对离不开模型本身的复杂度,一个模型拥有上百亿的参数,效果不好就太对不起我们的资源了。我们要知道训练一套这类模型需要花费甚至几百万美金的成本。
ALBERT就是试图解决上述的问题: **1. 让模型的参数更少 2. 使用更少的内存 3. 提升模型的效果。**最后一点其实并不一定能达到,此处不做深入讨论。
文章"ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS"里提出一个有趣的现象:当我们让一个模型的参数变多的时候,一开始模型效果是提高的趋势,但一旦复杂到了一定的程度,接着再去增加参数反而会让效果降低,这个现象叫作“model degratation"。
基于上面所讲到的目的,ALBERT提出了三种优化策略,做到了比BERT模型小很多的模型,但效果反而超越了BERT。
-
Factorized Embedding Parameterization. 他们做的第一个改进是针对于Vocabulary Embedding。在BERT、XLNet中,词表的embedding size(E)和transformer层的hidden size(H)是等同的,所以E=H。但实际上词库的大小一般都很大,这就导致模型参数个数就会变得很大。为了解决这些问题他们提出了一个基于factorization的方法。
他们没有直接把one-hot映射到hidden layer, 而是先把one-hot映射到低维空间之后,再映射到hidden layer。这其实类似于做了矩阵的分解。
-
Cross-layer parameter sharing. Zhenzhong博士提出每一层的layer可以共享参数,这样一来参数的个数不会以层数的增加而增加。所以最后得出来的模型相比BERT-large小18倍以上。
-
Inter-sentence coherence loss. 在BERT的训练中提出了next sentence prediction loss(NSP), 也就是给定两个sentence segments, 然后让BERT去预测两个句子是否出自同一篇文章,但在ALBERT文章里认为NSP任务太过于简单,这种训练方式对于模型精度的提升并不大。 所以他们做出改进,使用的是setence-order prediction loss (SOP),其实是基于主题的关联去预测是否两个句子调换了顺序。
此外,ALBERT还去除了模型中的dropout
-
去掉了dropout,最大的模型,训练了1百万步后,还是没有过拟合训练数据。说明模型的容量还可以更大,就移除了dropout(dropout可以认为是随机的去掉网络中的一部分,同时使网络变小一些)
-
为加快训练速度,使用LAMB做为优化器。使用了大的batch_size来训练(4096)。 LAMB优化器使得我们可以训练,特别大的批次batch_size,如高达6万。
-
使用n-gram(uni-gram,bi-gram, tri-gram)来做遮蔽语言模型,即以不同的概率使用n-gram,uni-gram的概率最大,bi-gram其次,tri-gram概率最小。
 BERT简图 BERT简图 |
 ALBERT简图 ALBERT简图 |
考虑硬件、训练速度等方面的因素,本次比赛我选择了ALBERT-small。
- 预训练部分主要使用的是corpus.txt中的数据,在上述二、数据集分析中已经对corpus.txt进行了简要分析,利用4-逗号,将corpus.txt重新组织为每一行一句话,两篇文档之间用空行隔开的形式。
- 统计corpus.txt中的词频并排序,写入vocab.txt
- 在创建预训练数据文件时,max-seq-length选择了128,max-predictions-per-seq选择了20。
- 预训练参数中对train-steps与warmup-steps进行微调,选取合适的值,学习率采用官方祖传参数。
- 利用bert4keras载入预训练模型
- 对softmax分类层的dropout概率进行微调
- 修改随机种子,进行模型训练
详细可参见对抗训练浅谈:意义、方法和思考(附Keras实现)
最初我使用的是StratifiedKFold,考虑到测试集的分布可能与训练集不一致,我又改为了KFold,希望能增加部分鲁棒性。做完5Fold后,对预测结果取平均值。
在训练时,随机交换输入样本中句子a与句子b的位置。测试过程中,对测试集的每个样本,先预测一次。交换句子a与句子b的位置,再预测1次,取平均值。
ALBERT与BERT之间的一个显著区别就是ALBERT进行了参数共享,从而减小了参数量。但是对于tiny、small版模型来说,但这同时也造成了ALBERT的精度略低于BERT。
因为本次比赛中,我使用的是small模型,所以在finetune阶段,可以利用BERT的方式载入ALBERT,取消参数共享,以加快模型的收敛并提升效果。
Python>=3.6,Tensorflow>=1.13.1, keras>=2.3.1,bert4keras>=0.7.4
运行以下代码即可,也可以根据自己的环境手动安装
pip install -r requirements.txt因为上传空间有限,需要手动向data文件夹中放入train.txt, test.txt, corpus.txt 三个数据文件
然后命令行中运行以下代码:
python albert_main.pyalbert_main.py包含预训练数据生成、进行预训练两个方法即参数,如下所示:
def create_data():
"""
制作albert的训练集文件
"""
# os.system("wget https://static.nowcoder.com/activity/2020zte/4/corpus.txt -O ./data/corpus.txt")
for i in range(1, 10):
print(os.listdir("./data"))
os.system(f"python3 ./create_pretraining_data_sp.py --do_whole_word_mask=True --input_file=./data/corpus.txt \
--output_file=./data/zte_textsim_{i}.tfrecord --vocab_file=./vocab.txt --do_lower_case=False \
--max_seq_length=128 --max_predictions_per_seq=20 --masked_lm_prob=0.15 --non_chinese=True \
--dupe_factor=1 --random_seed={i}")
print(os.listdir("./data"))
# return the score for hyperparameter tuning
return 0
def pretrain():
"""
训练集文件生成结束后,进行预训练
"""
print(os.getcwd())
opt_path = "./model/albert"
print("save_path:", opt_path)
########### google albert ############# GPU(Google版本, small模型):
os.system("python ./run_pretraining_google.py --input_file=./data/zte_textsim*.tfrecord \
--output_dir=%s --do_train=True --do_eval=True --albert_config_file=./albert_config_small_google.json \
--train_batch_size=256 --max_seq_length=128 --max_predictions_per_seq=20 \
--num_train_steps=250000 --num_warmup_steps=3125 --learning_rate=0.00176 \
--save_checkpoints_steps=2000 --export_dir=%s/export "%(opt_path, opt_path))
return 0
if __name__ == "__main__":
create_data()
pretrain()create_data()方法中,循环十次等同于dupe_factor=10,其他参数如max_seq_length、max_predictions_per_seq与masked_lm_prob,可根据自己的需要进行调节。
pretrain()中调用run_pretraining_google.py文件进行预训练,如果显存不够,可以将train_batch_size调小一些,如果想要更换模型只需改变albert_config_file路径参数
号外:
我在./model/albert中放置了我训练好的albert模型model.ckpt-250000,大小约为80Mb,如果不想自己再训练一遍,可以直接使用该模型。
命令行中运行以下代码即可:
python fine_tune_debug.py --maxlen=128 --epochs=1 --batch_size=64 --config_path='./albert_config_small_google.json' \
--checkpoint_path='./model/albert/model.ckpt-250000' --vocab_path='./vocab.txt' --learning_rate=2e-5 --kfold=5 --adver=True \
--threshold=0.5 --rank_predict=False
# 如果想要跑出A榜89.3的成绩,需要将上述参数中--rank_predict修改为True:
python fine_tune_debug.py --maxlen=128 --epochs=1 --batch_size=64 --config_path='./albert_config_small_google.json' \
--checkpoint_path='./model/albert/model.ckpt-250000' --vocab_path='./vocab.txt' --learning_rate=2e-5 --kfold=5 --adver=True \
--threshold=0.5 --rank_predict=True具体参数含义可以运行以下代码,或直接在代码中查看:
python fine_tune.py --help
输出:
usage: fine_tune_debug.py [-h] [-ml MAXLEN] [-e EPOCHS] [-b BATCH_SIZE]
[-cgp CONFIG_PATH] [-ckp CHECKPOINT_PATH]
[-vp VOCAB_PATH] [-lr LEARNING_RATE] [-k KFOLD]
[-adver ADVER] [-threshold THRESHOLD]
[-rp RANK_PREDICT]
Hi guys!
optional arguments:
-h, --help show this help message and exit
-ml MAXLEN, --maxlen MAXLEN
序列最大长度,默认为128
-e EPOCHS, --epochs EPOCHS
迭代次数,默认为30; Earlystopping
默认开启,patience为3,如欲修改,需要手动修改py文件。
-b BATCH_SIZE, --batch_size BATCH_SIZE
训练批次大小,默认为64
-cgp CONFIG_PATH, --config_path CONFIG_PATH
预训练模型配置文件路径,默认为./albert_config_small_google.json
-ckp CHECKPOINT_PATH, --checkpoint_path CHECKPOINT_PATH
预训练模型路径,默认为./model/albert/model.ckpt-250000
-vp VOCAB_PATH, --vocab_path VOCAB_PATH
vocab文件路径,默认为./vocab.txt
-lr LEARNING_RATE, --learning_rate LEARNING_RATE
学习率,默认为2e-5
-k KFOLD, --kfold KFOLD
k折交叉验证,默认为5
-adver ADVER, --adver ADVER
是否启用对抗学习,默认为True
-threshold THRESHOLD, --threshold THRESHOLD
是否启用对抗学习,默认为0.5
-rp RANK_PREDICT, --rank_predict RANK_PREDICT
预测输出中是否令1与0的数量相等,注意,当该参数为True时,
threshold参数会无效化.默认为True我的成绩当然还有进一步提高的空间,比如:
-
没有构造传统特征,训练传统模型并与ALBERT进行融合
-
受限于计算资源,没有尝试太多其他模型,只是对ALBERT-small做了多种微调
-
没有利用训练集相似关系的传递性做数据增强
-
没有把测试集和训练集拼接在一起做图特征,因为没有实际业务意义
-
没有使用伪标签等把测试集加入训练的技术,因为没有实际业务意义
-
利用训练集相似关系的传递性进行后处理:
即使只传递一次,还是处理一个错一个,A榜不停的掉分。。。个人认为,后处理修改的数据中90%以上应该都是标错的数据,但由于时间缘故,未对其进行进一步的处理
-
预训练模型中我只使用了corpus.txt中的数据:
我根据预测结果,提取了train中的数据与test中置信度高的数据,并筛选出label=1的数据,根据相似性传递原理进行聚类,同一类的为一篇文档,最终增加了5w篇文档。
预训练过程中,可以看到模型的mask_lm_loss有明显下降,且mask_lm_accuracy与sentence_order_accuracy有6个百分点的提升,但是在微调时分类精度反而下降1个百分点左右
个人认为可能是由于新增的数据中,文档类句子的前后关系不够明确,导致sentence_order_loss的拟合方向出了差错,并影响了整体的训练效果。
最后,非常感谢中兴可以提供这次算法比赛的机会,让我能够学习和接触到NLP这个领域;同时也要感谢华为云naie提供的云服务器,让我薅了这么久羊毛😂;当然还要感谢网上许多大佬的开源,没有他们的热心开源,就没有我的进步!
如果在运行代码时碰到问题,欢迎邮件联系
Email: 592959130@qq.com
[1] 从bert, xlnet, roberta到albert - 李文哲的文章 - 知乎 https://zhuanlan.zhihu.com/p/84559048
[2] 苏剑林. (2020, Jan 29). 《抛开约束,增强模型:一行代码提升albert表现 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/7187
[3] 苏剑林. (2019, Jun 18). 《当Bert遇上Keras:这可能是Bert最简单的打开姿势 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/6736
[4] 苏剑林. (2020, Mar 01). 《对抗训练浅谈:意义、方法和思考(附Keras实现) 》[Blog post]. Retrieved from https://kexue.fm/archives/7234
[5] 【竞赛】天池-新冠疫情相似句对判定大赛top6方案及源码 - 糖葫芦喵喵的文章 - 知乎 https://zhuanlan.zhihu.com/p/130990722
[6] Top9竞赛总结-NLP语义相似度 第三届拍拍贷“魔镜杯”大赛 - CSDN https://blog.csdn.net/u012891055/article/details/86624033
[7] Bright Liang Xu, albert_zh, (2019), GitHub repository, https://github.com/brightmart/albert_zh