Reinforcing Your Learning of Reinforcement Learning.
这个是我在学习强化学习的过程中的一些记录,以及写的一些代码。建立这个Github项目主要是可以和大家一起相互学习和交流,也同时方便其他人寻找强化学习方面的资料。我为什么学习强化学习,主要是想把 AlphaZero 的那套方法(结合深度学习的蒙特卡洛树搜索)用在 RNA 分子结构预测上,目前已经做了一些尝试,比如寻找 RNA 分子的二级结构折叠路径。
首先看的书是 Richard S. Sutton 和 Andrew G. Barto 的 Reinforcement Learning: An Introduction (Second edition)。
看书的同时,也根据网上的一些文章写一些简单的代码,依次如下。
- Q-Learning
- Deep Q-Learning Network (DQN)
- Dueling Double DQN & Prioritized Experience Replay
- Policy Gradients (PG)
- Advantage Actor Critic (A2C)
- Asynchronous Advantage Actor Critic (A3C)
- Proximal Policy Optimization (PPO)
- Deep Deterministic Policy Gradient (DDPG)
- AlphaGoZero Introduction
- Monte Carlo Tree Search (MCTS)
- AlphaGomoku
- RNA Folding Path
- Atari Game Roms
Bellman equation:


基于 Q-Learning 玩 Frozen Lake 游戏:[code]







基于 Q-Learning 玩井字棋游戏:[code]
训练结果:
Q-Learning Player vs Q-Learning Player
====================
Train result - 100000 episodes
Q-Learning win rate: 0.45383
Q-Learning win rate: 0.3527
players draw rate: 0.19347
====================
Q-Learning Player vs Random Player
====================
Train result - 100000 episodes
Q-Learning win rate: 0.874
Random win rate: 0.03072
players draw rate: 0.09528
====================






基于 Q-Learning 玩 Taxi v2 游戏:[code]
[0]. Diving deeper into Reinforcement Learning with Q-Learning
[1]. Q* Learning with FrozenLake - Notebook
[2]. Q* Learning with OpenAI Taxi-v2 - Notebook


weights updation:


游戏环境这里使用的是 ViZDoom ,神经网络是三层的卷积网络。[code]

训练大约 1200 轮后结果如下:

Episode 0 Score: 61.0
Episode 1 Score: 68.0
Episode 2 Score: 51.0
Episode 3 Score: 62.0
Episode 4 Score: 56.0
Episode 5 Score: 33.0
Episode 6 Score: 86.0
Episode 7 Score: 57.0
Episode 8 Score: 88.0
Episode 9 Score: 61.0
[*] Average Score: 62.3

游戏环境使用的是 Gym Retro ,神经网络见下图。[code]

训练大约 25 局后结果如下:
[*] Episode: 11, total reward: 120.0, explore p: 0.7587, train loss: 0.0127
[*] Episode: 12, total reward: 80.0, explore p: 0.7495, train loss: 0.0194
[*] Episode: 13, total reward: 110.0, explore p: 0.7409, train loss: 0.0037
[*] Episode: 14, total reward: 410.0, explore p: 0.7233, train loss: 0.0004
[*] Episode: 15, total reward: 240.0, explore p: 0.7019, train loss: 0.0223
[*] Episode: 16, total reward: 230.0, explore p: 0.6813, train loss: 0.0535
[*] Episode: 17, total reward: 315.0, explore p: 0.6606, train loss: 9.7144
[*] Episode: 18, total reward: 140.0, explore p: 0.6455, train loss: 0.0022
[*] Episode: 19, total reward: 310.0, explore p: 0.6266, train loss: 1.5386
[*] Episode: 20, total reward: 200.0, explore p: 0.6114, train loss: 1.5545
[*] Episode: 21, total reward: 65.0, explore p: 0.6044, train loss: 0.0042
[*] Episode: 22, total reward: 210.0, explore p: 0.5895, train loss: 0.0161
[*] Episode: 23, total reward: 155.0, explore p: 0.5778, train loss: 0.0006
[*] Episode: 24, total reward: 105.0, explore p: 0.5665, train loss: 0.0016
[*] Episode: 25, total reward: 425.0, explore p: 0.5505, train loss: 0.0063
[0]. An introduction to Deep Q-Learning: let’s play Doom
[1]. Deep Q learning with Doom - Notebook
[2]. Deep Q Learning with Atari Space Invaders
[3]. Atari 2600 VCS ROM Collection
Four improvements in Deep Q Learning:
- Fixed Q-targets

- Double DQN

- Dueling DQN
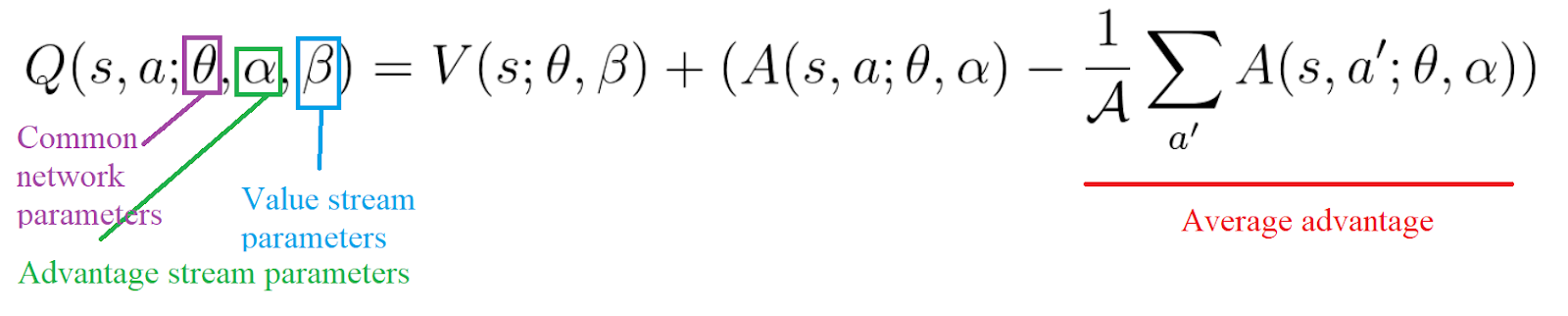
- Prioritized Experience Replay





其中,Dueling DQN 的神经网络如下图: [code]

Prioritized Experience Replay 采用 SumTree 的方法:

[0]. Improvements in Deep Q Learning: Dueling Double DQN, Prioritized Experience Replay, and fixed Q-targets
[1]. Let’s make a DQN: Double Learning and Prioritized Experience Replay
[2]. Double Dueling Deep Q Learning with Prioritized Experience Replay - Notebook



其中,Policy Gradient 神经网络如下图。

训练大约 950 轮后结果如下:


====================
Episode: 941
Reward: 39712.0
Mean Reward: 2246.384288747346
Max reward so far: 111837.0
====================
Episode: 942
Reward: 9417.0
Mean Reward: 2253.9883351007425
Max reward so far: 111837.0
====================
Episode: 943
Reward: 109958.0
Mean Reward: 2368.08156779661
Max reward so far: 111837.0
====================
Episode: 944
Reward: 73285.0
Mean Reward: 2443.125925925926
Max reward so far: 111837.0
====================
Episode: 945
Reward: 40370.0
Mean Reward: 2483.217758985201
Max reward so far: 111837.0
[*] Model Saved: ./model/model.ckpt
具体代码请参见:[tensorflow] [pytorch]


神经网络如上,具体代码请参见:[code]
[0]. An introduction to Policy Gradients with Cartpole and Doom
[1]. Cartpole: REINFORCE Monte Carlo Policy Gradients - Notebook
[2]. Doom-Deathmatch: REINFORCE Monte Carlo Policy gradients - Notebook
[3]. Deep Reinforcement Learning: Pong from Pixels
[to be done]
[to be done]


训练 500 epoch 后:
----------------------------------------
Epoch: 499
TotalEnvInteracts: 2000000
EpRet: 585.4069 470.6009(min) 644.4069(max) 67.6205(std)
EpLen: 1000.0000
VVals: 46.3796 23.6165(min) 50.2677(max) 2.5903(std)
LossPi: -0.0172
LossV: 506.2033
DeltaLossPi: -0.0172
DeltaLossV: -32.9680
Entropy: 5.5010
KL: 0.0188
ClipFrac: 0.1937
StopIter: 6.0000
Time: 27175.5427s
----------------------------------------
具体代码请参见:[code]
[0]. OpenAI Spinning Up - Proximal Policy Optimization


由于训练不稳定,在第 225 epoch 取得最大平均 reward:
----------------------------------------
Epoch: 225
TotalEnvInteracts: 1130000
EpRet: 1358.9755 920.2474(min) 1608.4678(max) 238.5494(std)
EpLen: 992.0000
TestEpRet: 1101.4177 479.9980(min) 1520.0907(max) 415.7242(std)
TestEpLen: 873.2000
QVals: 136.3016 -112.4969(min) 572.5870(max) 36.0409(std)
LossPi: -138.1635
LossQ: 7.0895
Time: 28183.4149s
----------------------------------------
随着时间的增长,平均 reward 波动较大,此起彼伏,训练 365 epoch 后:
----------------------------------------
Epoch: 365
TotalEnvInteracts: 1830000
EpRet: -1250.8838 -2355.5800(min) -10.4664(max) 810.3868(std)
EpLen: 723.5714
TestEpRet: -1241.4192 -2211.0383(min) -884.2655(max) 342.6774(std)
TestEpLen: 1000.0000
QVals: 407.9140 -116.6802(min) 684.3555(max) 76.7627(std)
LossPi: -413.1655
LossQ: 61.5379
Time: 50710.5035s
----------------------------------------
具体代码请参见:[code]
[0]. OpenAI Spinning Up - Deep Deterministic Policy Gradient
这个是我通过阅读 AlphaGo Zero 的文献,以及结合网路上相关的一些文章,将这些内容通过自己的理解整合到这一个PPT中,用来在组会上简单的介绍 AlphaGo Zero 背后的方法和原理给同学和老师,同时也思考如何将其结合到其他领域。当然,其中也不仅仅包括 AlphaGo Zero 的内容,也有我最近看的另外一篇文章,他们的研究团队运用类似的方法来解魔方。[pdf]


[0]. AlphaGo Zero - How and Why it Works
[1]. Alpha Go Zero Cheat Sheet
[2]. Mastering the game of Go with deep neural networks and tree search
[3]. Mastering the game of Go without Human Knowledge

MCTS vs Random Player [code]. Another MCTS on Tic Tac Toe [code].
[0]. mcts.ai
[1]. Introduction to Monte Carlo Tree Search
使用AlphaGo Zero的方法实现的一个五子棋AI。
下图是自我博弈训练 3000 局棋后,与人类选手对局的结果,已经很难下赢了。

策略估值网络提供了两个模型,分别是:
################
# Residual_CNN #
################
Network Diagram:
|-----------------------| /---C---B---R---F---D---R---D---T [value head]
I---C---B---R---o---C---B---R---C---B---M---R--- ..... ---|
\_______/ \_______________________/ \---C---B---R---F---D---S [polich head]
[Conv layer] [Residual layer]
I - input
B - BatchNormalization
R - Rectifier non-linearity, LeakyReLU
T - tanh
C - Conv2D
F - Flatten
D - Dense
M - merge, add
S - Softmax
O - output
##############
# Simple_CNN #
##############
Network Diagram:
2(1x1) 64 1
32(3x3) 64(3x3) 128(3x3) /-----C-----F-----D-----D-----T [value head]
I-----C-----R-----C-----R-----C-----R-----|
\_____________________________/ \-----C-----F-----D-----S [polich head]
[Convolutional layer] 4(1x1) w^2
I - input
B - BatchNormalization
R - ReLU
T - tanh
C - Conv2D
F - Flatten
D - Dense
S - Softmax
8x8 大小棋盘自我博弈训练 3000 局的结果如下:

[*] Episode: 2991, length: 42, start: O, winner: X, data: 336, time: 85s, win ratio: X 48.1%, O 48.5%, - 3.4%
Epoch 1/1
512/512 [==============================] - 1s 2ms/step - loss: 1.7491 - value_head_loss: 0.4658 - policy_head_loss: 1.0655
[*] Episode: 2992, length: 19, start: O, winner: O, data: 152, time: 40s, win ratio: X 48.1%, O 48.5%, - 3.4%
Epoch 1/1
512/512 [==============================] - 1s 2ms/step - loss: 1.6507 - value_head_loss: 0.4631 - policy_head_loss: 0.9698
[*] Episode: 2993, length: 23, start: X, winner: X, data: 184, time: 47s, win ratio: X 48.1%, O 48.5%, - 3.4%
Epoch 1/1
512/512 [==============================] - 1s 2ms/step - loss: 1.6409 - value_head_loss: 0.4322 - policy_head_loss: 0.9908
[*] Episode: 2994, length: 35, start: X, winner: X, data: 280, time: 71s, win ratio: X 48.1%, O 48.5%, - 3.4%
Epoch 1/1
512/512 [==============================] - 1s 2ms/step - loss: 1.6128 - value_head_loss: 0.4528 - policy_head_loss: 0.9421
[*] Episode: 2995, length: 16, start: X, winner: O, data: 128, time: 35s, win ratio: X 48.1%, O 48.5%, - 3.4%
Epoch 1/1
512/512 [==============================] - 1s 2ms/step - loss: 1.7529 - value_head_loss: 0.4884 - policy_head_loss: 1.0466
[*] Episode: 2996, length: 22, start: O, winner: X, data: 176, time: 46s, win ratio: X 48.1%, O 48.5%, - 3.4%
Epoch 1/1
512/512 [==============================] - 1s 2ms/step - loss: 1.6800 - value_head_loss: 0.4583 - policy_head_loss: 1.0038
[*] Episode: 2997, length: 16, start: X, winner: O, data: 128, time: 35s, win ratio: X 48.1%, O 48.5%, - 3.4%
Epoch 1/1
512/512 [==============================] - 1s 2ms/step - loss: 1.6877 - value_head_loss: 0.4973 - policy_head_loss: 0.9725
[*] Episode: 2998, length: 22, start: X, winner: O, data: 176, time: 48s, win ratio: X 48.1%, O 48.5%, - 3.4%
Epoch 1/1
512/512 [==============================] - 1s 2ms/step - loss: 1.6530 - value_head_loss: 0.4887 - policy_head_loss: 0.9464
[*] Episode: 2999, length: 16, start: X, winner: O, data: 128, time: 33s, win ratio: X 48.1%, O 48.5%, - 3.4%
Epoch 1/1
512/512 [==============================] - 1s 2ms/step - loss: 1.6951 - value_head_loss: 0.4582 - policy_head_loss: 1.0189
[*] Episode: 3000, length: 9, start: X, winner: X, data: 72, time: 18s, win ratio: X 48.1%, O 48.5%, - 3.4%
Epoch 1/1
512/512 [==============================] - 1s 2ms/step - loss: 1.6760 - value_head_loss: 0.4743 - policy_head_loss: 0.9838
具体代码及训练好的模型参数请参考这里:[code]
[0]. How to build your own AlphaZero AI using Python and Keras
[1]. Github: AppliedDataSciencePartners/DeepReinforcementLearning
[2]. Github: Rochester-NRT/RocAlphaGo
[3]. 28 天自制你的 AlphaGo (6) : 蒙特卡洛树搜索(MCTS)基础
[4]. AlphaZero实战:从零学下五子棋(附代码)
[5]. Github: junxiaosong/AlphaZero_Gomoku
使用深度强化学习来学习 RNA 分子的二级结构折叠路径。具体说明这里就不再重复了,请参见这里:[link]
这里有一些 Atari 游戏的 Rom,可以导入到 retro 环境中,方便进行游戏。[link]