In this project, I analyzed the data provided by Figure Eight containing the messages in three different categories. Goal of the project is to build a model for an API that classifies disaster messages across 36 different categories.
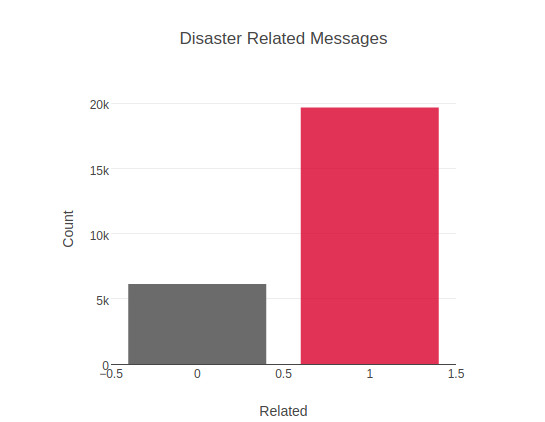
- Messages are either related to a distaster or not.Out of 25825 messages, 19688 of messages are related to disaster and 6137 of messages are not.
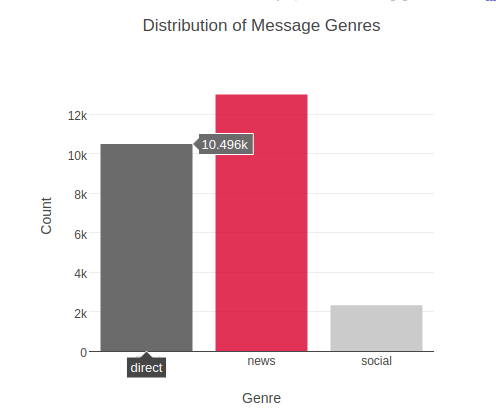
- Each message belong to one of the three genres(Direct, Social, News).
- There are 36 target features. By analyzing the dataset it can be seen that if a message is related to a disaster,only then the other 35 features might have a value 1, otherwise 0. Distribution of the target variables is shown below.




Preprocessing is done in data/process_data.py file containing an ETL pipeline.
- Data is read from the csv files
data/disaster_messages.csvanddata/disaster_categories.csv. - Both the messages and the categories datasets are merged.
- Merged data is cleaned.
- Duplicated mesages are removed.
- Non-English messages are removed.
- Cleaned data is stored in
data/DisasterResponse.db.
ML pipeline is implemented in models/train_classifier.py.
- It loads the data from
data/DisasterResponse.db. - Data is split into trainging and testing sets.
- A function
tokenize()is implemented to clean the messages data and tokenize it for tf-idfcalculations. - Pipelines are implemented for text and machine learning processing.
- Parameter selection is based on GridSearchCV.
- Trained classifier is stored in
models/classifier.p.
Flask app is implemented in the app folder.
- Main page gives an overview of the dat as shown in the images above.
- Main page allows the user to write a message and choose a genre of the message.

- Output for the given message is shown below. It categorizes the message into related categories.



[Optional] 1. Run the following commands in the project's root directory to set up your database and model.
- To run ETL pipeline that cleans data and stores in database
`python data/process_data.py data/disaster_messages.csv data/disaster_categories.csv data/DisasterResponse.db`
- To run ML pipeline that trains classifier and saves
`python models/train_classifier.py data/DisasterResponse.db models/classifier.p`
-
Run the following command in the app's directory to run your web app.
python app/run.py -
Go to http://0.0.0.0:3001/