This project is a comprehensive NFL Data Pipeline built to scrape, process, validate, store, and analyze NFL statistics and schedules, providing a dynamic dashboard for easy monitoring.
The NFL Data Pipeline project is designed to extract, transform, and load (ETL) NFL data from public sources into a Google Sheets dashboard. The pipeline is robust, featuring data validation, error handling, logging, email notifications, and a local HTML dashboard for tracking pipeline performance. It is intended as a modular, reusable framework that can be expanded with additional data sources or analytics steps.
The pipeline consists of the following main components:
-
Data Extraction:
- Scrapes NFL stats and schedules from multiple sources using
requestsandBeautifulSoup.
- Scrapes NFL stats and schedules from multiple sources using
-
Data Transformation:
- Cleans, validates, and formats data for consistency and accuracy.
- Joins relevant data to create a final, structured DataFrame for analysis.
-
Data Loading:
- Exports transformed data into an Excel file.
- Loads data to Google Sheets for dynamic dashboard visualization.

-
Data Backup:
- Archives backups of the data to a local folder.
-
Monitoring and Notifications:
- Logs key actions and errors to a local log file.
- Sends email notifications upon pipeline completion or error.
- Tracks pipeline status in a Google Sheets-based dashboard.
- Monitors HMTL Dashboard Locally for lightweight visualization of the pipeline status.

Here's a breakdown of the key files and directories:
.
├── backups/ # Folder to store backup files
│ ├── final_output/ # Final outputs backed up with timestamps
│ └── weekly_output/ # Weekly outputs backed up with timestamps
├── nfl_scrapper.py # Script for scraping NFL statistics
├── schedule_scrapper.py # Script for scraping NFL weekly schedule
├── matchup_stats.py # Processes and transforms scraped data
├── write_to_gsheets.py # Uploads processed data to Google Sheets
├── generate_html_dashboard.py # Generates an HTML dashboard from Google Sheets data
├── create_backups.py # Script to backup files in local folders
├── validation_functions.py # Validation functions for data integrity
├── run_all_scripts.py # Orchestrates the pipeline and schedules tasks
├── generate_html_dashboard.py # Generates HTML dashboard for monitoring
├── nfl_pipeline.log # Log file for pipeline actions and errors
├── requirements.txt # Python dependencies
└── README.md # Project documentation
The architecture follows an ETL (Extract, Transform, Load) workflow:
- Extract:
nfl_scrapper.pyandschedule_scrapper.pygather data from NFL sources. - Transform:
matchup_stats.pyprocesses and prepares data for analysis. - Load:
write_to_gsheets.pyuploads data to Google Sheets. - Monitor:
generate_html_dashboard.pygenerates an HTML dashboard from the run log on Google Sheets.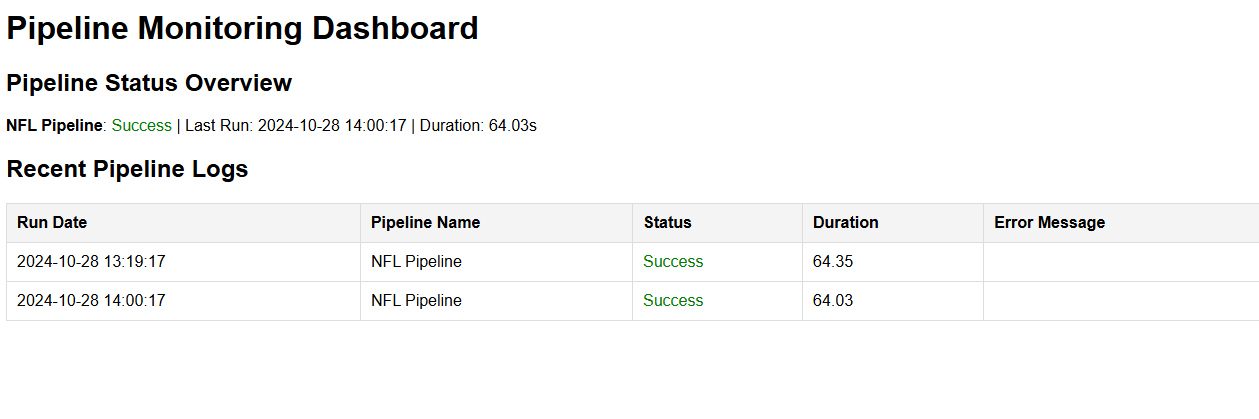

The pipeline follows a typical ETL architecture. Below is a high-level overview:

This node-based diagram provides insight into the step-by-step structure of each script and function used in the pipeline:

Prerequisites Python 3.8+ Google Cloud Console for API credentials (ensure credentials.json is downloaded) Graphviz (if using Graphviz for visualizations) Google Sheets API enabled and credentials.json file in the project root.
Installation Steps
-
Clone the Repository:
git clone https://github.com/yourusername/nfl-data-pipeline.git
-
Setup the virtual environment:
python -m venv venv source venv/bin/activate # On Windows: venv\Scripts\activate
-
Install dependencies:
pip install -r requirements.txt
-
Add enviromental variables in
.env:EMAIL=<your-email> EMAIL_PASSWORD=<your-email-password> RECEIVER_EMAIL=<receiver-email> SPREADSHEET_ID_LOG=<Google-Sheet-ID-for-log> SPREADSHEET_ID=<Google-Sheet-ID-for-data>
-
Google API Setup:
- Set up a Google Cloud project and create a service account.
- Download the
credentials.jsonfile for your service account and place it in the project root.
- Running Individual Scripts: Each script performs a specific function in the pipeline. For example, to scrape data, run:
python nfl_scrapper.py
- Running the Full Pipeline: Use the main orchestration script to execute the full ETL pipeline:
python run_all_scripts.py
- Generating the Dashboard: Generate the HTML dashboard for monitoring pipeline status by running:
python generate_html_dashboard.py
The pipeline is set up to run automatically every Tuesday at 10:00 am.
-
Task Scheduler (Windows):
- Use Task Scheduler to schedule run_all_scripts.py.
- Set the trigger to run weekly on Tuesdays at 10:00 am.
-
Cron (Linux): Add a cron job to schedule the pipeline:
0 10 * * 2 /path/to/python /path/to/run_all_scripts.py
- Log File:
nfl_pipeline.loglogs all major actions, including errors. - Google Sheets Dashboard: Records pipeline run status, duration, and any error messages.
- Monitoring: The pipeline generates an HTML dashboard from Google Sheets, providing real-time insights into the pipeline's health.
- Email Notifications: Sends completion or error alerts to the configured email.
The pipeline uses a Google Sheets log to monitor each run’s status, duration, and errors. The generate_html_dashboard.py script converts this log into a visual HTML dashboard, enabling quick and easy monitoring of the pipeline.
Backup copies of data files are saved in the backups folder:
- weekly_output: Stores weekly outputs from the pipeline.
- final_output: Stores finalized data with a timestamp for historical tracking.
Contributions are welcome! If you'd like to contribute, please follow these steps:
- Fork the repository.
- Create a feature branch (
git checkout -b feature/AmazingFeature). - Commit your changes (
git commit -m 'Add some AmazingFeature'). - Push to the branch (
git push origin feature/AmazingFeature). - Open a pull request.
- Additional Pipelines: Integrate other data sources (e.g., weather, player stats) to enrich NFL analysis.
- Advanced Scheduling: Use Airflow for better task scheduling and dependency management.
- Data Storage Optimization: Transition to SQL or NoSQL databases for scalable, long-term data storage.
The pipeline uses the following main libraries:
requestsbeautifulsoup4pandasgspreadpython-dotenvsmtplibjinja2
This project is open-source and licensed under the MIT License.