The project was done in 2016.
Toolstack: Hadoop, MongoDB, Apache Spark, Scala, Java, Eclipse, Maven.
Done in collaboration with Kai Robin Sachse and Evgeni Nikolaev. I am the primary contributor.
- Recommend the best business to a user (restaurant, health accommodation or shopping location).
- Use Latent Dirichlet Allocation (LDA) to assign businesses, based on reviews, to a specific topic/category (e.g. Sea Food)
- Use our proposed metric for finding the best business based on a distance d in km, stars s given by users and the probability f that a business belongs to a category a user is interested in:
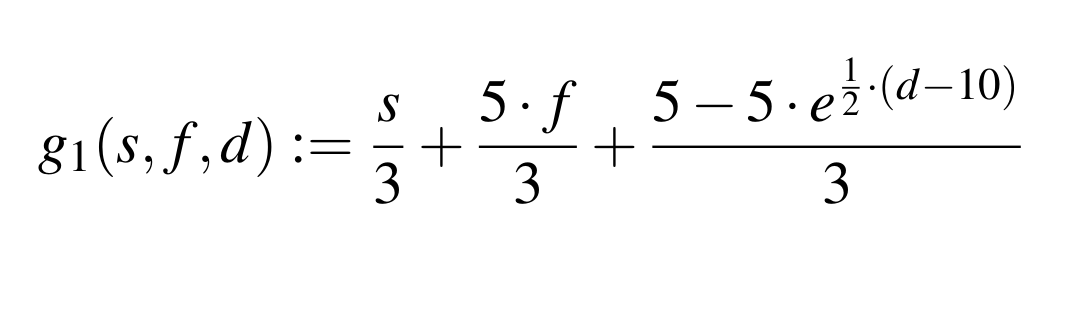
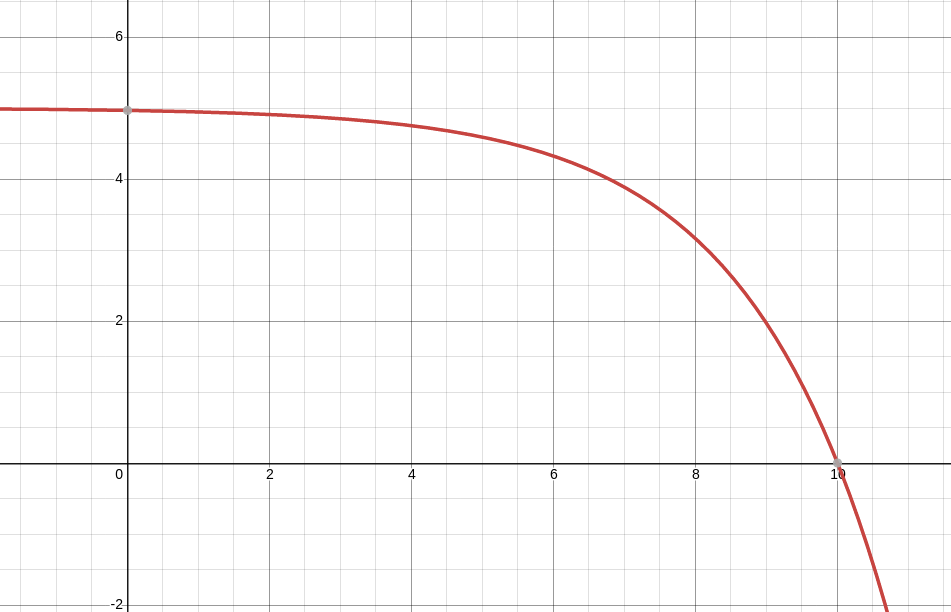
- Distrance function (the rightmost term in the upper equation) has the following behaviour:


- The Yelp dataset (https://www.yelp.com/dataset/documentation/main) contains information about businesses and reviews. The json files "business.json" and "review.json" whould be placed into the folder "data_yelp"
- The file "Analysis.scala" runs LDA and saves the information about bsiness and their probability of belongign to a specific category/topic. These data should be placed into the folder "analyzed_data"
- The folder "stopwords" contains the stopwords
- Follow the following instructions on how to run the recommendation system from scratch. All commands are for a Linux system.
0.1. Download data (https://www.yelp.com/dataset/documentation/main) and put it into the folder data_yelp
1.1. Install docker: https://www.docker.com/
1.2. Command: docker pull cloudera/quickstart:latest
1.3. Command: docker images #note the hash of the image and substitute it in 1.4.
1.4. Command: docker run --privileged=true --hostname=quickstart.cloudera -t -i -p 8888:8888 -p 80:80 cloudera/quickstart /usr/bin/docker-quickstart #if defaults are accepted.
1.5. Browse hue at localhost:8888. Of course, in your browser.
1.5.1. Open File Browser.
1.5.2. Upload file review.json into the directory "cloudera".
1.5.3. Upload file business.json into the directory "cloudera".
1.5.4. Upload files located in the folder stopwords, the DVD, into the directory "cloudera".
2.1. Run the command: spark-shell (e.g., ./spark-shell --driver-memory 1536m --executor-memory 1536m)
2.2. Copy and paste commands from the file Analysis.scala one by one if necessary
0.1. Install MongoDB.
0.2. Create directory, command: sudo mkdir -p /var/lib/mongodb/data/db
0.2. Run MongoDB server, commad: sudo mongod --dbpath /var/lib/mongodb/data/db
0.3. Install Java 8.
0.4. Install Eclipse with Maven support.
1.1. Command: mongoimport --db yelp --collection restaurants --drop --file "/pathToFile/restaurant.json". The analysed file from the stage 1.
1.1. Command: mongoimport --db yelp --collection shopping --drop --file "/pathToFile/shopping.json". The analysed file from the stage 1.
1.1. Command: mongoimport --db yelp --collection health --drop --file "/pathToFile/health.json". The analysed file from the stage 1.
2.1. Extract "Anwendung.zip".
2.2. Run as Java application.
2.3. Follow the instructions.