This is my assignment of undergraduate education in China University of Petroleum (East China)
Because the dataset is too large, a total of about 40G, it is not convenient to upload, here the dataset generation code is uploaded to run the dataset/gen_printed_char.py file to generate the training set image, the specific operation is below:
python gen_printed_char.py --out_dir [out_put_dir] --font_dir [windows_font_dir] --width [img_width] --height [img_height] --margin 4 --rotate 30 --rotate_step 1The train directory is the training directory, After executing the train_adam.py, you can train the model, 'train_adam.py' is used for training with the 'adam' optimizer, if training uses this file
The 'test' directory is the directory of test images, Run /run.py to convert images to text
'run/run.py' specifies before running:
A directory of images to be recognized by OCR
The directory after the image is segmented
Catalog of trained models
The file corresponding to the kanji and 'id' ordinal number
You can then see the recognized text in the console
The res directory is the model training result directory, which contains the raw data of Loss image generation code, Accuracy image generation code, Loss image, Accuracy image, Loss, and Accuracy
As the information carrier for the development of Chinese civilization, Chinese characters have a history of thousands of years and are also the most used script in the world, which records the brilliant national culture and shows the unique thinking and cognitive methods of Eastern peoples. With the promotion and application of computer technology, especially the increasing popularity of the Internet, human beings are increasingly using computers to obtain various information, and a large number of information processing work has also been transferred to computers. In daily life and work, there are a large number of text information processing problems, so the requirement to quickly input text information into the computer has become very urgent. The amount of information in modern society is unprecedentedly rich, and most of the information is preserved and disseminated in the form of printed form, which makes the computer input device with keyboard input as the main means dwarfed, and the low input speed has become the main bottleneck of information entering the computer system, affecting the efficiency of the entire system.
On the one hand, the use of this technology can improve the efficiency of computer use and overcome the contradiction between man and machine. On the other hand, this technology can be applied to quickly identify ID cards, bank cards, driver`s licenses and other card information, and directly convert the text information of the certificate into editable text, which can greatly improve the work efficiency of relevant departments in Shandong Province, reduce labor costs, and verify the identity of relevant personnel in real time for the safety management of various departments in Shandong Province.
Using the font file library that comes with WINDOWS, drawing with Python`s PIL library, drawing a text on each picture, drawing a total of 3755 Chinese characters.
According to the Chinese character national standard library drawing, the same font generates 976 pictures as a training set, generates 244 pictures as a test set of accuracy in training, a total of 3755 Chinese characters, a training set (excluding verification set) a total of 3664880 files, each Chinese character has a corresponding 876 training set pictures and 244 verification set pictures, according to AlexNet requirements each picture size should be 227*227.
nn.Linear(in_features= 256*6*6, out_features= 4096),
nn.ReLU(inplace= True),
nn.Dropout(0.5),
nn.Linear(in_features= 4096, out_features= 4096),
nn.ReLU(inplace= True),
nn.Linear(in_features= 4096, out_features= class_num)
)
def forward(self, x):
x = self.featureExtraction(x)
x = x.view(x.size(0), 256*6*6)
x = self.fc(x)
return x
```
To run the model to achieve text recognition, the first step to consider is how to cut each character from the picture, and then it can be sent to our designed model for character recognition, and the cutting algorithm is summarized into the following two steps:
-
Horizontal projection of the picture, find the upper and lower limits of each row, and cut the rows;
-
For each line cut out, vertical projection is carried out, the left and right boundaries of each character are found, and a single character is cut.
-
For row cutting, that is, horizontal projection, is to count each row element of a picture, and then draw a statistical result map according to the statistical results, and then determine the start and end points of each row, the statistical pixel map is as follows:

Figure 7 Schematic diagram of horizontal row cutting
-
After cutting each line, we get a line of text, project this line of text vertically and cut a single character according to the boundary value of each character according to the vertical projection, and achieve the split point effect as follows:

Figure 8 Achieve split effect

-
loss
This experiment uses PyTorch's cross-entropy library function, which is used to determine how close the actual output is to the desired output. It mainly describes the distance between the actual output (probability) and the expected output (probability), the smaller the value of cross-entropy, the closer the probability distribution, the cross-entropy function calculation formula is as follows:
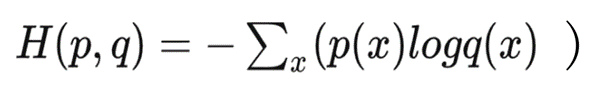
Figure 9 Cross-entropy function in pytorch
Obtain the cross-entropy object by statement loss = torch.nn.CrossEntropyLoss(), in the model training phase, 32 pictures per training, record the loss value (cross-entropy function value) every 300 training cycles, and plot the graph using matplotlib.
-
Accuracy
In the training stage of this experiment, the prediction set is predicted, and the prediction accuracy is compared with the real value according to the prediction results, the number of prediction accuracy is compared with the total calculated quantity, and the accuracy is calculated, this experiment trains 32 pictures each time, records the value Accuracy value (prediction set accuracy value) every 300 training times, and uses matplotlib to draw a curve.

-
loss value (cross-entropy function value)
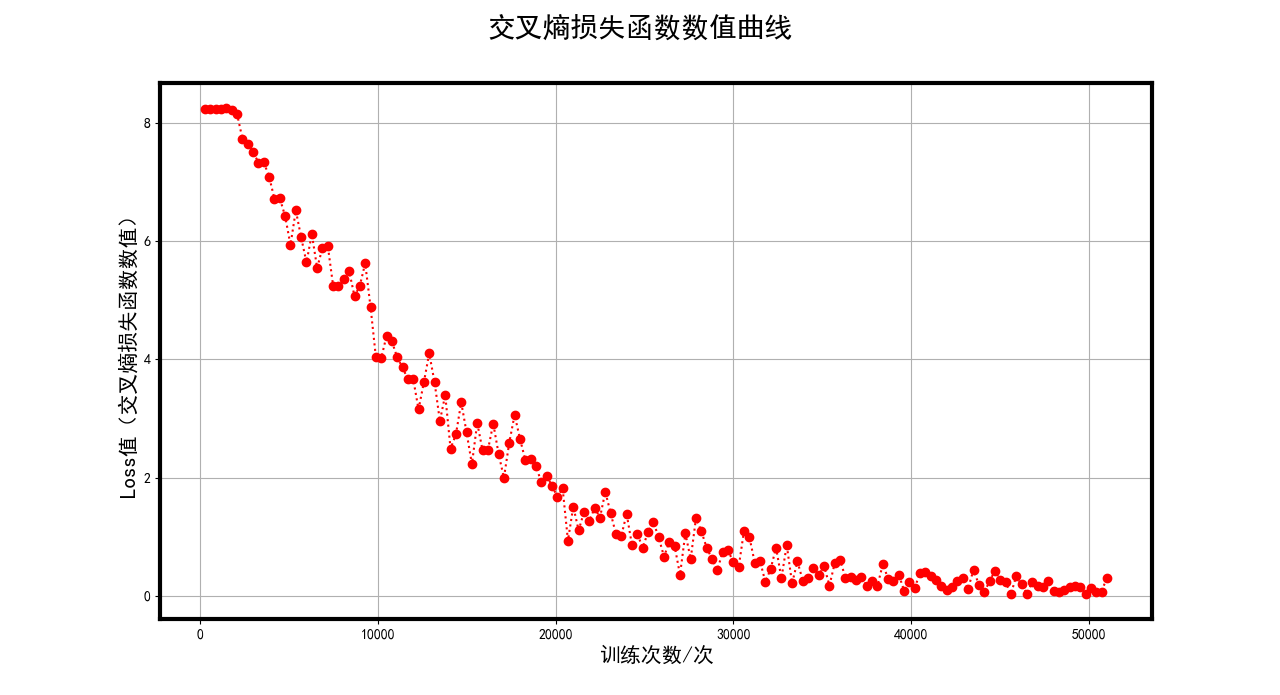
Figure 10 The loss value (cross-entropy loss function value) curve trained by the model
Observing the image, you can see that the loss value decreases with oscillations, but the overall decline posture, after 50,000 training results are better, the loss value is close to 0, but still not fully reached the 0 value, the reason for the shock may be that the learning rate is set to 0.00001 is higher, and then the learning rate is reduced to 0.000001, the loss value still maintains a small up and down vibration, but the overall trend does not change.
-
Accuracy value
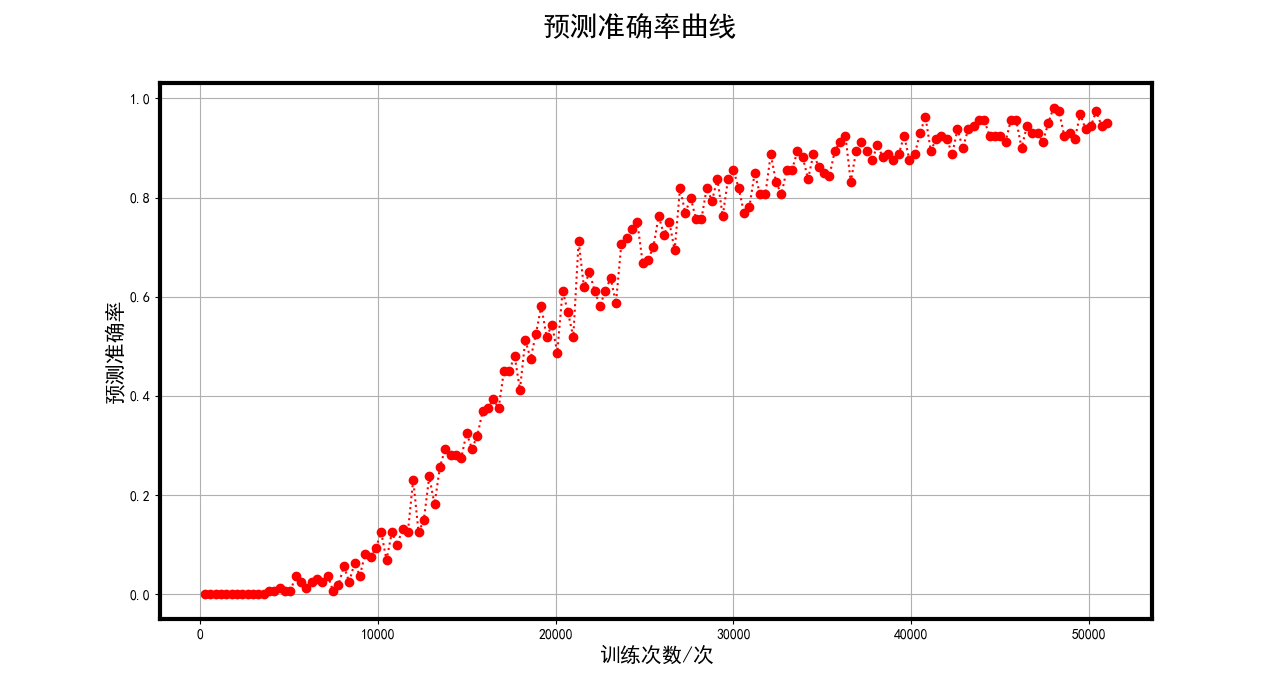
Figure 11 The Accuracy value curve of model training
Observing the image, you can see that the Accuracy value rises in oscillation, but the overall upward attitude, after 50,000 training results are better, the Accurarcy value is close to 1, but it has not fully reached the 1 value, the reason for the oscillation may be that the learning rate is set to 0.00001 is higher, and then the learning rate is reduced to 0.000001, the Accuracy value still maintains a small amplitude up and down vibration, but the overall trend does not change.


-
For a single file with a font of 48*48, the recognition result recognizes the character "馨" as "譬", and the rest are recognized correctly, as shown in the following figure:
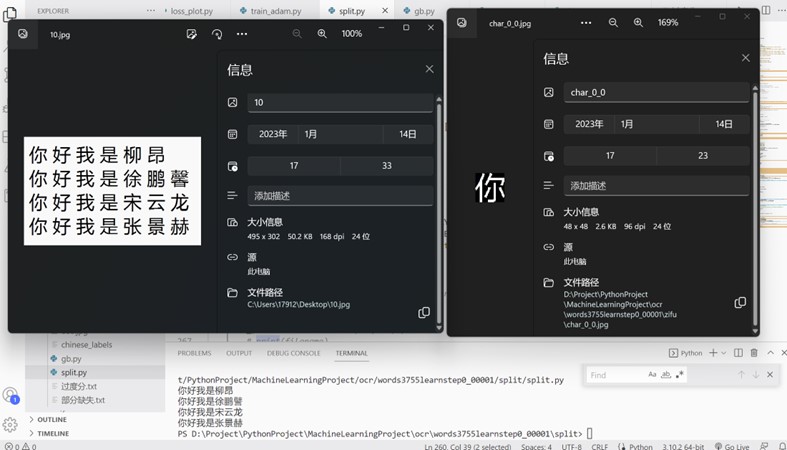
Figure 12 Unknown images are segmented to predict result
-
For a single file with a font of 48*49, the recognition results recognize the character "亶" as the character "膏" and the character "枝" as the character "栈", and the rest are recognized correctly and the accuracy rate is good.
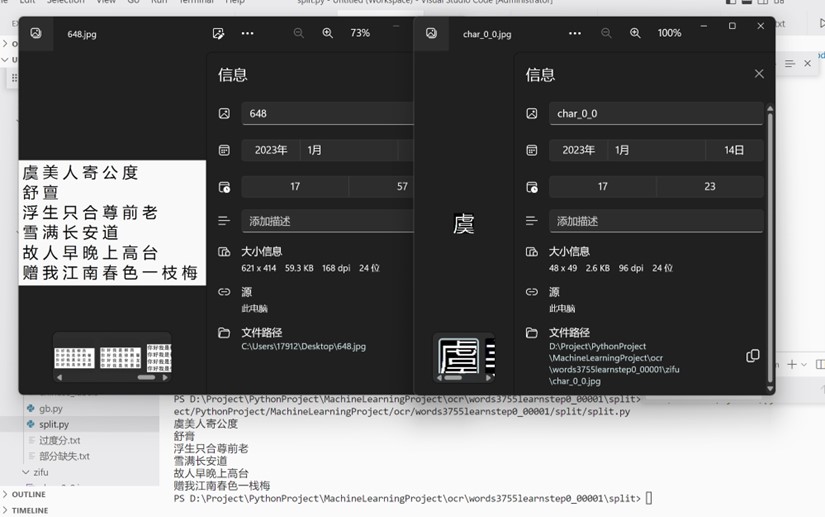
Figure 13 Unknown images are segmented to predict result
-
The results are analyzed, because AlexNet's requirement for the read picture is 227*227, the 227*227 picture directly generated by the training dataset is directly generated, but as shown above, the pictures input during the model test of unknown images are almost small after cutting, blurry after enlargement, and the size of the training picture is quite different, which may lead to the problem that the prediction accuracy rate cannot reach the prediction accuracy rate during training, which is mainly reflected in the recognition of similar words and the recognition of complex words.


-
After this experiment, we have a preliminary understanding of the use of neural networks, and we have experience in using the pytorch framework, which has benefited a lot.
-
In the early stage of model training, due to the large data set, about 3664880 227*227 pictures need to consume large computing power whether it is image generation or model training, so the first 30 fonts are taken for model training, and after about 3 hours of training, the model loss value converges significantly.
After that, try to use GPU acceleration to train 3755 words, download NVIDIA's CUDA module, and install the CUDA version of PyTorch, train 3755 pictures, due to more images, set the batchsize to 512, but the training results are not ideal, loss and accuracy remain almost unchanged and the performance is poor, and then consult the relevant information to set the batchsize to 128, 64, 32, and the learning rate is constantly reduced, but the effect is still poor.
Considering that training can be achieved on a small sample, considering the reason why the sample is too large, it is planned to split the 3755 into multiple groups for training, and when training on 1000 words of data, it is found that it still cannot converge, so continue to reduce the data set to 500, 100, and the accuracy value of the loss value and prediction set can be successfully converged when training 100 words, at this time, the data was found to have a better optimizer adam, and after consulting the data, it was found that the performance of gradient descent SGD was significantly inferior to adam. Adam optimization method gradient decline is fast, so set the optimizer to adam, train 100 words, find that the model convergence speed is much faster than the previous training, almost several times the previous one, after rejoicing, the Adam optimizer is used for 1000 words training, and it is found that the loss value of the model is still convergent, so the ADAM optimizer is used for the overall training set of 3755 words. When the learning rate is set to 0.00001, it is found that it can converge, and when the batchsize is set to 32, the loss value is reduced to a low level and remains unchanged overall, and the accuracy value is also the same, and then the learning rate is further reduced, but the loss value and accuracy value still maintain a certain overall level and do not change much, so the training is ended.
-
When performing image prediction, it is realized that the model training uses a larger image of 227*227 because considering AlexNet's requirements for images, and the image to be predicted is generally smaller due to the generally small segmentation, so there may be a difference between the prediction accuracy rate and the accuracy value during training.
-
The division of labor in this experiment is clear, and the PIL library that comes with python for image generation is drawn according to the national standard text library, which is responsible for Song Yunlong; The model training adopts the pytorch framework to implement AlexNet, and the model is trained on the GPU and the relevant values are recorded, which is responsible for Zhang Jinghe. After training the model, when using the model to identify unknown pictures, it is necessary to segment the pictures to capture a single word picture, which is responsible for Liu Ang. The specific prediction of unknown images is the responsibility of Zhang Jinghe; The document writing part was handled by Zhang Jinghe and Xu Pengxin.