GAN的基本原理其实非常简单,这里以生成图片为例进行说明。假设我们有两个网络,G(Generator)和D(Discriminator)。正如它的名字所暗示的那样,它们的功能分别是: G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。 D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。 在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
- demo名称:利用生成式对抗网络生成动漫头像
- 环境:Windows10+Python3.7+Tensorflow2.0
- 主要是处理用来训练的动漫头像图片。
- 训练用的图片素材大小为[96, 96, 3]。这里是链接。图片素材是在网上找的,忘记是哪位老哥的了,侵删。
- 图片示例

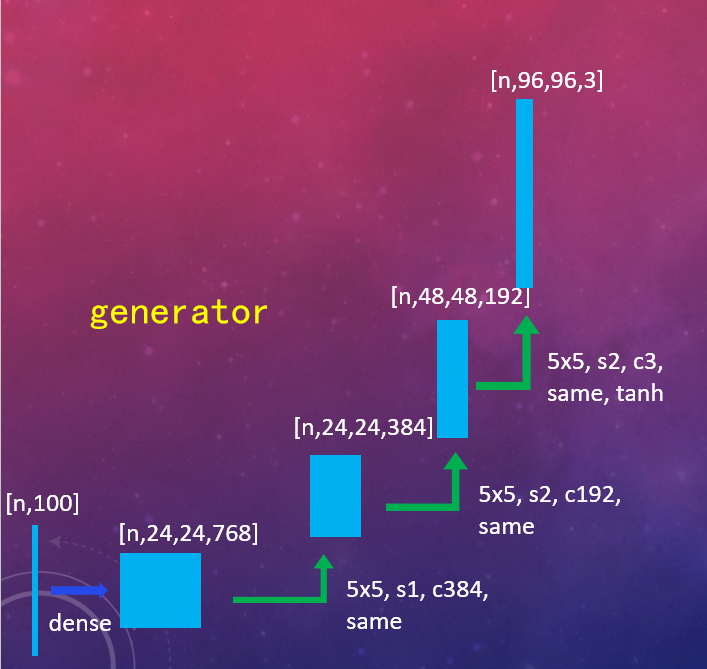
简单的生成器与判别器
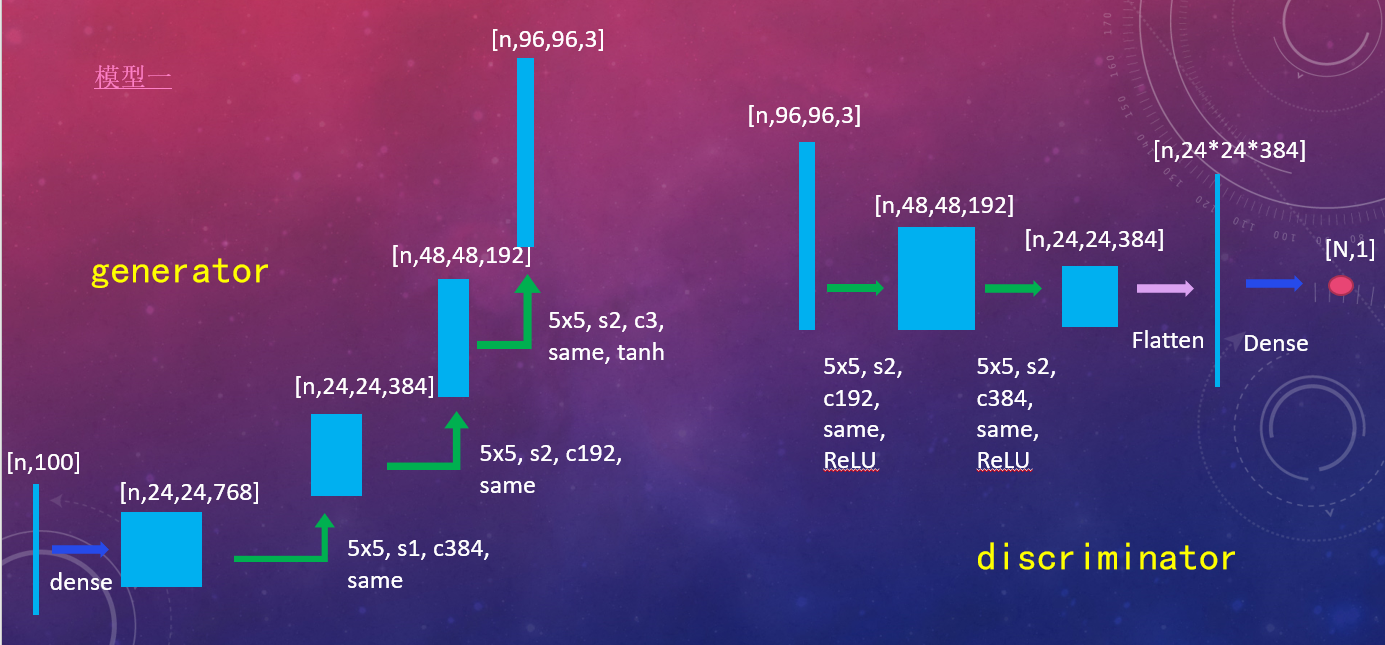
- 生成器:UNet256
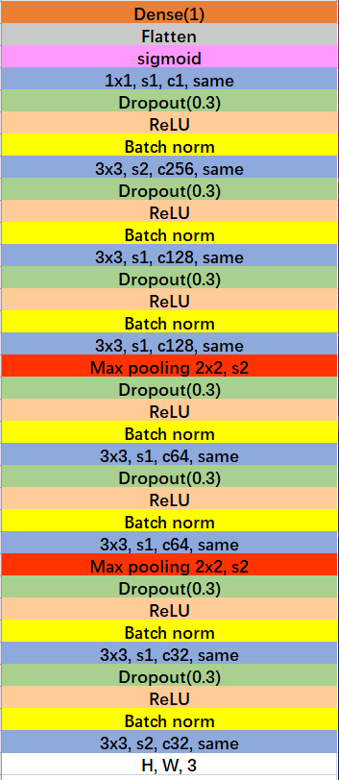
- 判别器:PatchGAN
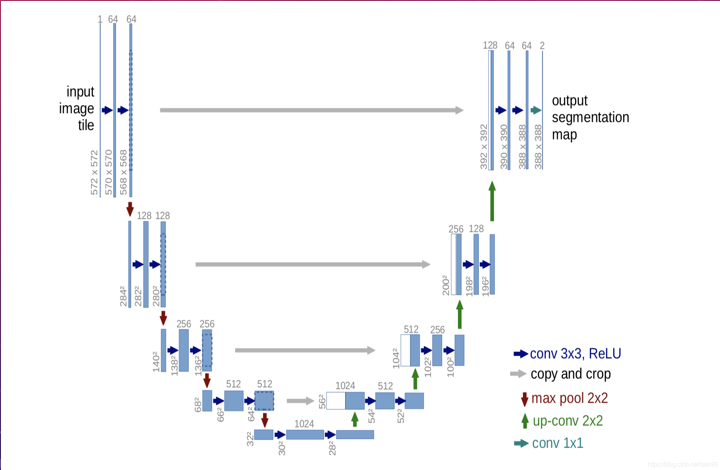

- 生成器:考虑到生成器是从生成一个噪点开始的,因此UNet256中向下采样的过程没什么必要,所以去掉了向下采样的过程
- 判别器:在PatchGAN基础上改造