(Py)TOD: Tensor-based Outlier Detection, A General GPU-Accelerated Framework
Deployment & Documentation & Stats & License
Background: Outlier detection (OD) is a key data mining task for identifying abnormal objects from general samples with numerous high-stake applications including fraud detection and intrusion detection.
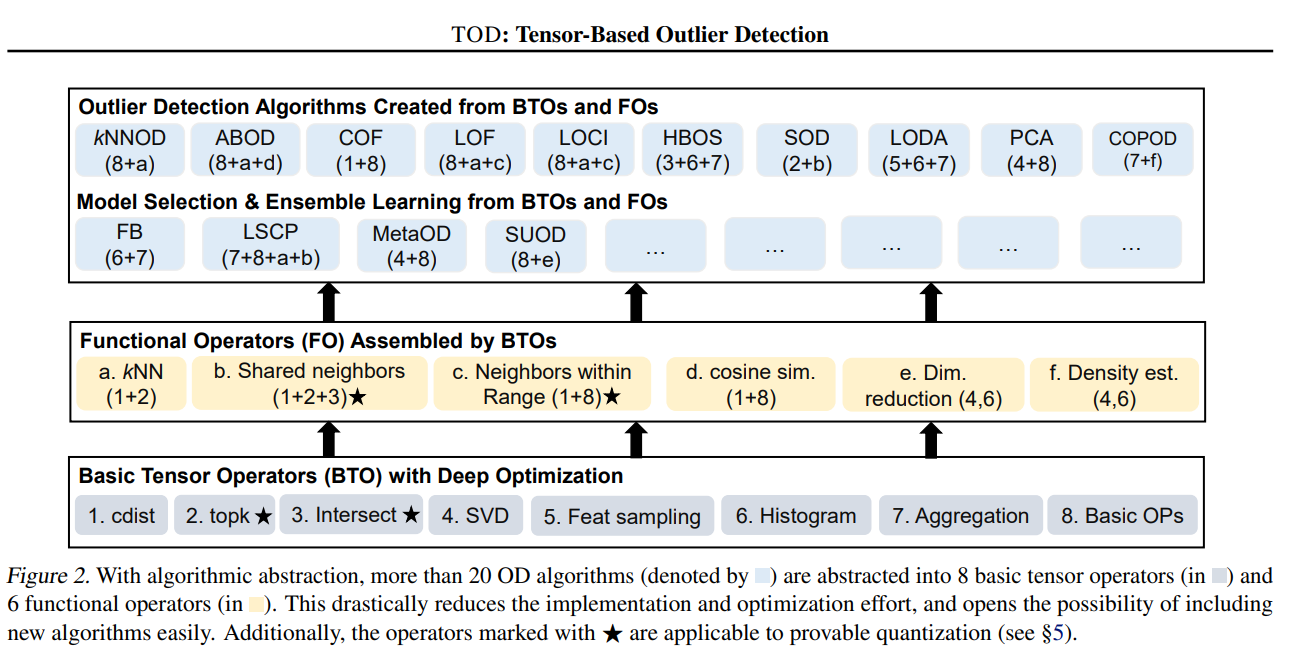
To scale outlier detection (OD) to large-scale, high-dimensional datasets, we propose TOD, a novel system that abstracts OD algorithms into basic tensor operations for efficient GPU acceleration.
Development team: TOD is developed by the same author(s) of PyOD. Specifically, Yue Zhao,
Prof. George Chen, and Prof. Zhihao Jia from CMU design, implement, and maintain TOD.
The code is being cleaned up and released. Please watch and star!
Citing TOD:
Check out the design paper.
If you use TOD in a scientific publication, we would appreciate
citations to the following paper:
@article{zhao2021tod,
title={TOD: Tensor-based Outlier Detection},
author={Zhao, Yue and Chen, George H and Jia, Zhihao},
journal={arXiv preprint arXiv:2110.14007},
year={2021}
}
If you need another reason: it can handle much larger datasets---more than a million sample OD within an hour!
GPU-accelerated Outlier Detection with 5 Lines of Code:
# train the COPOD detectorfrompytod.models.knnimportKNNclf=KNN() # default GPU device is usedclf.fit(X_train)
# get outlier scoresy_train_scores=clf.decision_scores_# raw outlier scores on the train datay_test_scores=clf.decision_function(X_test) # predict raw outlier scores on test
TOD is featured for:
Unified APIs, detailed documentation, and examples for the easy use (under construction)
More than 10 different OD algorithms and more are being added
The support of multi-GPU acceleration
Advanced techniques including provable quantization and automatic batching
# if GPU is not available, use CPU insteadclf=KNN(device='cpu')
clf.fit(X_train)
Get the prediction results
# get the prediction label and outlier scores of the training datay_train_pred=clf.labels_# binary labels (0: inliers, 1: outliers)y_train_scores=clf.decision_scores_# raw outlier scores
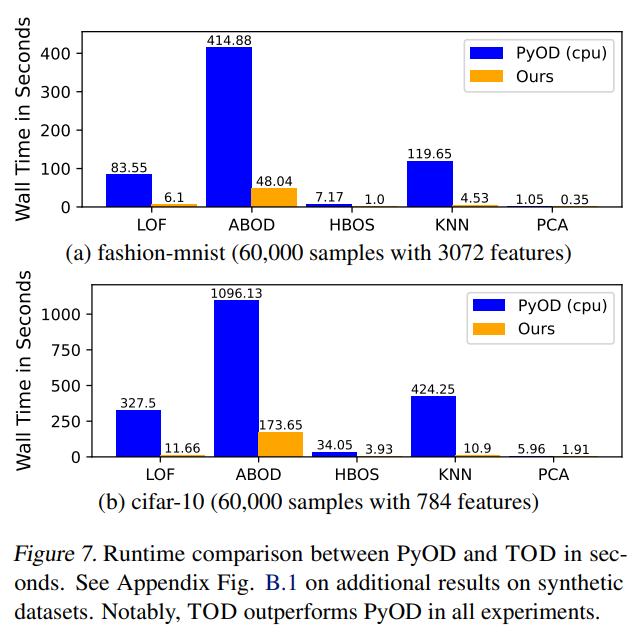
On a simple laptop, let us see how fast it is in comparison to PyOD for 30,000 samples with 20 features
It is easy to see, PyTOD shows both better efficiency than PyOD.
Programming Model Interface
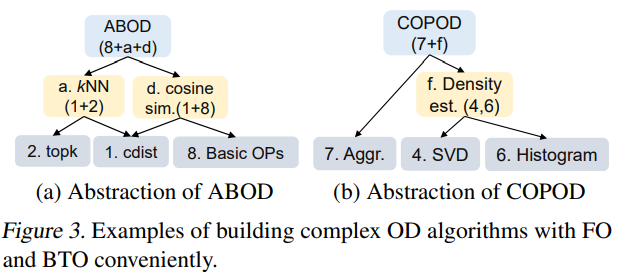
Complex OD algorithms can be abstracted into common tensor operators.
For instance, ABOD and COPOD can be assembled by the basic tensor operators.
End-to-end Performance Comparison with PyOD
Overall, it is much (on avg. 11 times) faster than PyOD takes way less run time.
Reference
[1]
Aggarwal, C.C., 2015. Outlier analysis. In Data mining (pp. 237-263). Springer, Cham.
[2]
Aggarwal, C.C. and Sathe, S., 2015. Theoretical foundations and algorithms for outlier ensembles.ACM SIGKDD Explorations Newsletter, 17(1), pp.24-47.
[3]
Aggarwal, C.C. and Sathe, S., 2017. Outlier ensembles: An introduction. Springer.
[4]
Almardeny, Y., Boujnah, N. and Cleary, F., 2020. A Novel Outlier Detection Method for Multivariate Data. IEEE Transactions on Knowledge and Data Engineering.
[5]
(1, 2) Angiulli, F. and Pizzuti, C., 2002, August. Fast outlier detection in high dimensional spaces. In European Conference on Principles of Data Mining and Knowledge Discovery pp. 15-27.
[6]
Arning, A., Agrawal, R. and Raghavan, P., 1996, August. A Linear Method for Deviation Detection in Large Databases. In KDD (Vol. 1141, No. 50, pp. 972-981).
Goldstein, M. and Dengel, A., 2012. Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm. In KI-2012: Poster and Demo Track, pp.59-63.
[10]
Gopalan, P., Sharan, V. and Wieder, U., 2019. PIDForest: Anomaly Detection via Partial Identification. In Advances in Neural Information Processing Systems, pp. 15783-15793.
[11]
Hardin, J. and Rocke, D.M., 2004. Outlier detection in the multiple cluster setting using the minimum covariance determinant estimator. Computational Statistics & Data Analysis, 44(4), pp.625-638.
[12]
He, Z., Xu, X. and Deng, S., 2003. Discovering cluster-based local outliers. Pattern Recognition Letters, 24(9-10), pp.1641-1650.
[13]
Iglewicz, B. and Hoaglin, D.C., 1993. How to detect and handle outliers (Vol. 16). Asq Press.
[14]
Janssens, J.H.M., Huszár, F., Postma, E.O. and van den Herik, H.J., 2012. Stochastic outlier selection. Technical report TiCC TR 2012-001, Tilburg University, Tilburg Center for Cognition and Communication, Tilburg, The Netherlands.
[15]
Kingma, D.P. and Welling, M., 2013. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
[16]
(1, 2) Kriegel, H.P. and Zimek, A., 2008, August. Angle-based outlier detection in high-dimensional data. In KDD '08, pp. 444-452. ACM.
[17]
Kriegel, H.P., Kröger, P., Schubert, E. and Zimek, A., 2009, April. Outlier detection in axis-parallel subspaces of high dimensional data. In Pacific-Asia Conference on Knowledge Discovery and Data Mining, pp. 831-838. Springer, Berlin, Heidelberg.
[18]
Lazarevic, A. and Kumar, V., 2005, August. Feature bagging for outlier detection. In KDD '05. 2005.
[19]
Li, D., Chen, D., Jin, B., Shi, L., Goh, J. and Ng, S.K., 2019, September. MAD-GAN: Multivariate anomaly detection for time series data with generative adversarial networks. In International Conference on Artificial Neural Networks (pp. 703-716). Springer, Cham.
Li, Z., Zhao, Y., Botta, N., Ionescu, C. and Hu, X. COPOD: Copula-Based Outlier Detection. IEEE International Conference on Data Mining (ICDM), 2020.
[21]
Liu, F.T., Ting, K.M. and Zhou, Z.H., 2008, December. Isolation forest. In International Conference on Data Mining, pp. 413-422. IEEE.
[22]
Liu, Y., Li, Z., Zhou, C., Jiang, Y., Sun, J., Wang, M. and He, X., 2019. Generative adversarial active learning for unsupervised outlier detection. IEEE Transactions on Knowledge and Data Engineering.
[23]
Papadimitriou, S., Kitagawa, H., Gibbons, P.B. and Faloutsos, C., 2003, March. LOCI: Fast outlier detection using the local correlation integral. In ICDE '03, pp. 315-326. IEEE.
Ramaswamy, S., Rastogi, R. and Shim, K., 2000, May. Efficient algorithms for mining outliers from large data sets. ACM Sigmod Record, 29(2), pp. 427-438.
[26]
Rousseeuw, P.J. and Driessen, K.V., 1999. A fast algorithm for the minimum covariance determinant estimator. Technometrics, 41(3), pp.212-223.
[27]
Ruff, L., Vandermeulen, R., Goernitz, N., Deecke, L., Siddiqui, S.A., Binder, A., Müller, E. and Kloft, M., 2018, July. Deep one-class classification. In International conference on machine learning (pp. 4393-4402). PMLR.
[28]
Scholkopf, B., Platt, J.C., Shawe-Taylor, J., Smola, A.J. and Williamson, R.C., 2001. Estimating the support of a high-dimensional distribution. Neural Computation, 13(7), pp.1443-1471.
Shyu, M.L., Chen, S.C., Sarinnapakorn, K. and Chang, L., 2003. A novel anomaly detection scheme based on principal component classifier. MIAMI UNIV CORAL GABLES FL DEPT OF ELECTRICAL AND COMPUTER ENGINEERING.
Tang, J., Chen, Z., Fu, A.W.C. and Cheung, D.W., 2002, May. Enhancing effectiveness of outlier detections for low density patterns. In Pacific-Asia Conference on Knowledge Discovery and Data Mining, pp. 535-548. Springer, Berlin, Heidelberg.
[31]
Wang, X., Du, Y., Lin, S., Cui, P., Shen, Y. and Yang, Y., 2019. adVAE: A self-adversarial variational autoencoder with Gaussian anomaly prior knowledge for anomaly detection. Knowledge-Based Systems.
[32]
Zhao, Y. and Hryniewicki, M.K. XGBOD: Improving Supervised Outlier Detection with Unsupervised Representation Learning. IEEE International Joint Conference on Neural Networks, 2018.
[33]
Zhao, Y., Nasrullah, Z., Hryniewicki, M.K. and Li, Z., 2019, May. LSCP: Locally selective combination in parallel outlier ensembles. In Proceedings of the 2019 SIAM International Conference on Data Mining (SDM), pp. 585-593. Society for Industrial and Applied Mathematics.
[34]
Zhao, Y., Hu, X., Cheng, C., Wang, C., Wan, C., Wang, W., Yang, J., Bai, H., Li, Z., Xiao, C., Wang, Y., Qiao, Z., Sun, J. and Akoglu, L. (2021). SUOD: Accelerating Large-scale Unsupervised Heterogeneous Outlier Detection. Conference on Machine Learning and Systems (MLSys).