Updated on 2023.12.26
This repository provides the official implementation of Text-guided Foundation Model Adaptation for Pathological Image Classification.
- Foundation model adaptation to medical imaging analysis
- Data-efficient and low-cost visual prompt tuning
- Injection of medical in-domain knowledge via text
- Compatibility with various foundation models
The recent surge of foundation models in computer vision and natural language processing opens up perspectives in utilizing multi-modal clinical data to train large models with strong generalizability. Yet pathological image datasets often lack biomedical text annotation and enrichment. Guiding data-efficient image diagnosis from the use of biomedical text knowledge becomes a substantial interest. In this paper, we propose to Connect Image and Text Embeddings (CITE) to enhance pathological image classification. CITE injects text insights gained from language models pre-trained with a broad range of biomedical texts, leading to adapt foundation models towards pathological image understanding. Through extensive experiments on the PatchGastric stomach tumor pathological image dataset, we demonstrate that CITE achieves leading performance compared with various baselines especially when training data is scarce. CITE offers insights into leveraging in-domain text knowledge to reinforce data-efficient pathological image classification.
An overview of CITE:
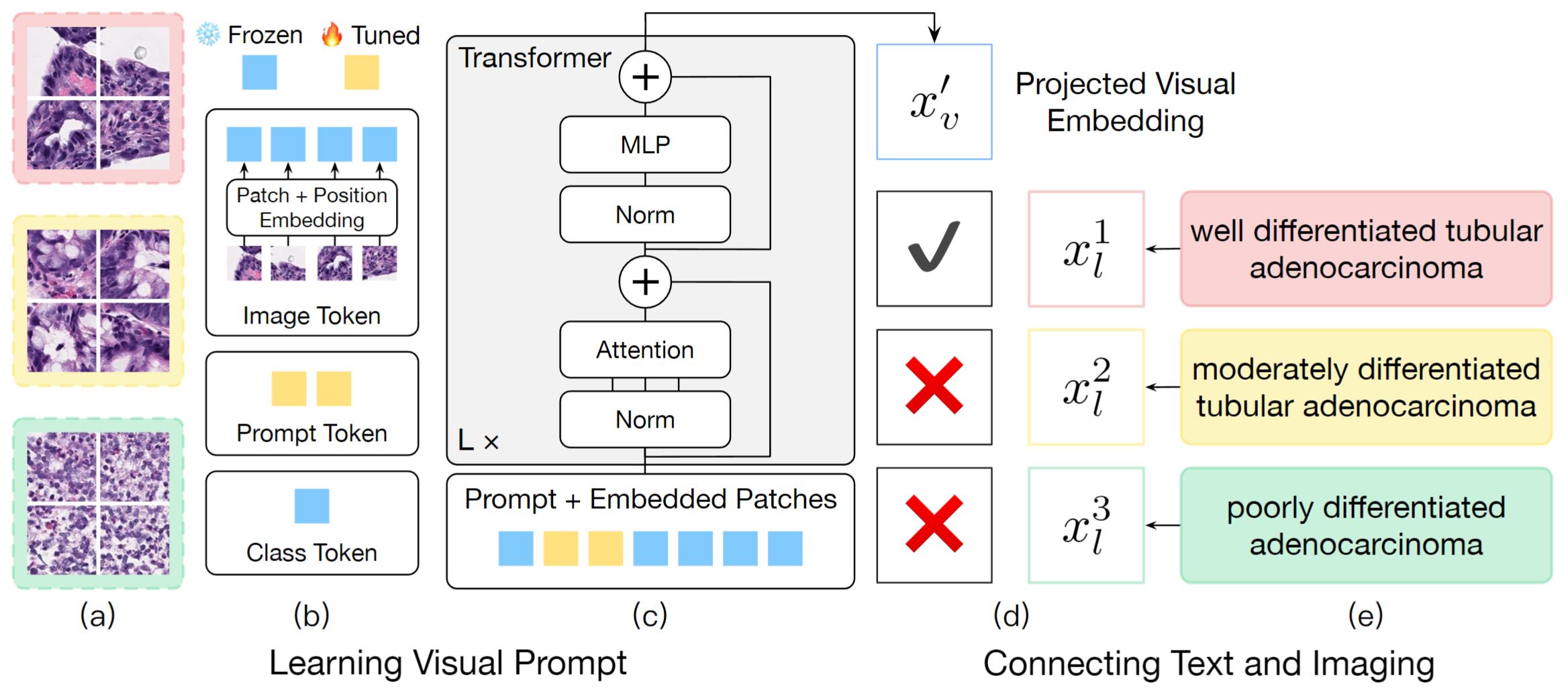
The PatchGastric dataset includes histopathological image patches extracted from H&E stained whole slide images (WSI) of stomach adenocarcinoma endoscopic biopsy specimens. The dataset contains 9 subtypes of gastric adenocarcinoma WSIs. We choose 3 major subtypes including “well differentiated tubular adenocarcinoma”, “moderately differentiated tubular adenocarcinoma”, and “poorly differentiated adenocarcinoma” to form a 3-class grading-like classification task with 179,285 patches of size 300x300 from 693 WSIs.
To prepare the PatchGastric dataset:
- Download
captions.csvandpatches_captions.zipfrom PatchGastricADC22. - Put them in
data/and unzip the file.
Main Requirements
torch==1.13.0
mmcls==0.25.0
transformers
clip
Installation
conda create -n CITE python=3.9
conda activate CITE
conda install pytorch==1.13.0 torchvision==0.14.0 torchaudio==0.13.0 pytorch-cuda=11.7 -c pytorch -c nvidia
pip install openmim
mim install mmcls==0.25.0
pip install -r requirements.txtPreprocess
To follow our split of the dataset, please generate the annotation files by running:
python tools/ann.pyOr you can generate your own split following mmcls format:
filename label
Training
The config files follow mmcls style.
PYTHONPATH=.:$PYTHONPATH mim train mmcls <config>Testing
PYTHONPATH=.:$PYTHONPATH mim test mmcls <config> --checkpoint <checkpoint> --metrics <metrics>@inproceedings{zhang2023text,
title={Text-guided Foundation Model Adaptation for Pathological Image Classification},
author={Zhang, Yunkun and Gao, Jin and Zhou, Mu and Wang, Xiaosong and Qiao, Yu and Zhang, Shaoting and Wang, Dequan},
booktitle={MICCAI},
year={2023}
}
We provide a comprehensive overview of current open-source medical language models, vision foundation models, and vision-language models, illustrating their applicability to our approach (CITE). For BERT-based language models, you may directly replace model->head->text_encoder->model and model->neck->out_features with your preferred Huggingface🤗 model in the config file to run CITE.
| Model | Subfield | Paper | Code | Base |
|---|---|---|---|---|
| REMEDIS | Radiology | Robust and Data-Efficient Generalization of Self-Supervised Machine Learning for Diagnostic Imaging | Github | SimCLR |
| RETFound | Retinopathy | A Foundation Model for Generalizable Disease Detection from Retinal Images | Github | MAE |
| CTransPath | Pathology | Transformer-Based Unsupervised Contrastive Learning for Histopathological Image Classification | Github | - |
| HIPT | Pathology | Scaling Vision Transformers to Gigapixel Images via Hierarchical Self-Supervised Learning | Github | DINO |
| INTERN-2.5 | General | InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions | Github | - |
| DINOv2 | General | DINOv2: Learning Robust Visual Features without Supervision | Github | - |
| MAE | General | Masked Autoencoders are Scalable Vision Learners | Github | - |
| ViT (ImageNet) | General | An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale | Huggingface | - |