

This project is crated only for those who is having interest in building Virtual Assistant. Generally it took lots of time to write code from scratch to build Virtual Assistant. So, I have built a Library called "JarvisAI", which gives you easy functionality to build your own Virtual Assistant.
- What is JarvisAI?
- Prerequisite
- Architecture
- Getting Started- How to use it?
- What it can do (Features it supports)
- Future / Request Features
- Contribute
- Contact me
- Donate
- Thank me on-
Jarvis AI is a Python Module which is able to perform task like Chatbot, Assistant etc. It provides base functionality for any assistant application. This JarvisAI is built using Tensorflow, Pytorch, Transformers and other opensource libraries and frameworks. Well, you can contribute on this project to make it more powerful.
-
Official Website: Click Here
-
Official Instagram Page: Click Here
-
Get your Free API key from http://jarvis-ai-api.herokuapp.com
-
To use it only Python (> 3.6) is required.
-
To contribute in project: Python is the only prerequisite for basic scripting, Machine Learning and Deep Learning knowledge will help this model to do task like AI-ML. Read How to contribute section of this page.
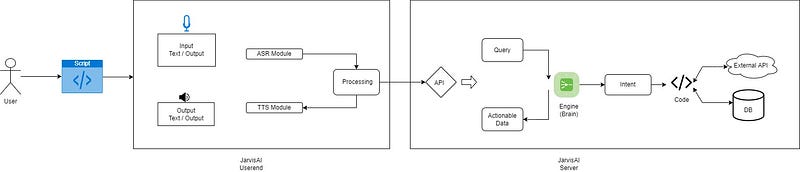
The JarvisAI’s architecture is divided into two parts.
-
User End- It is basically responsible for getting input from the user and after preprocessing input it sends input to JarvisAI’s server. And once the server sends its response back, it produces output on the user screen/system.
-
Server Side- The server is responsible to handle various kinds of AI-ML, and NLP tasks. It mainly identifies user intent by analyzing user input and interacting with other external APIs and handling user input.
NOTE: If you are using 'JarvisAI<4.0' the follow this link to get started: https://pypi.org/project/JarvisAI/3.9/ (Some features might not work in old version)
-
Install the latest version-
pip install JarvisAI
-
[Optional Step] If Pyaudio is not working or not installed you might need to install it seperately-
In the case of Mac OSX do:
brew install portaudio pip install pyaudio
In the case of Windows or Linux do:
-
Download pyaudio from: lfd.uci.edu/~gohlke/pythonlibs/#pyaudio
-
pip install PyAudio-0.2.11-cp310-cp310-win_amd64.whl
-
-
[Optional Step] If pycountry is not working or not installed then Install "python3-pycountry" Package on Ubuntu/Linux-
sudo apt-get update -y sudo apt-get install -y python3-pycountry -
[Optional Step] You might need to Install Microsoft Visual C++ Redistributable for Visual Studio 2022
You need only this piece of code-
import JarvisAI
# create your own function
# It must contain parameter 'feature_command' which is the command you want to execute
# Return is optional
# If you want to provide return value it should only return text (str)
# Your return value will be displayed or call out by the choice of OutputMethods of JarvisAI
def custom_function(feature_command="custom command"):
# write your code here to do something with the command
# perform some tasks # return is optional
return feature_command + ' Executed'
obj = JarvisAI.JarvisAI(input_method=InputsMethods.voice_input_google_api,
output_method=OutputMethods.voice_output,
backend_tts_api='pyttsx3',
api_key="5ba317a681c5d42361cda5b9f9ba7d0e",
detect_wake_word=False,
wake_word_detection_method=InputsMethods.voice_input_google_api,
bot_name="Jarvis",
display_intent=True,
google_speech_recognition_input_lang='en',
google_speech_recognition_key=None,
google_speech_recognition_duration_listening=5)
obj.register_feature(feature_obj=custom_function, feature_command='custom feature')
obj.start()
It will start your AI, it will ask you to give input and accordingly it will produce output.
You can configure input_mechanism and output_mechanism parameter for voice input/output or text input/output.
:param input_method: (object) method to get input from user <allowed values: [InputsMethods.text_input, InputsMethods.voice_input_google_api, InputsMethods.voice_input_deepspeech_streaming]>
:param output_method: (object) method to give output to user <allowed values: [OutputMethods.text_output, OutputMethods.voice_output]
:param backend_tts_api: (str) [Default 'pyttsx3'] backend tts api to use <allowed values: ['pyttsx3', 'gtts']>
:param api_key: (str) [Default ''] api key to use JarvisAI get it from http://jarvis-ai-api.herokuapp.com
:param detect_wake_word: (bool) [Default True] detect wake word or not <allowed values: [True, False]>
:param wake_word_detection_method: (object) [Default None] method to detect wake word <allowed values: [InputsMethods.voice_input_google_api, InputsMethods.voice_input_deepspeech_streaming]
:param bot_name: (str) [Default 'Jarvis'] name of the bot
:param display_intent: (bool) [Default True] display intent or not <allowed values: [True, False]>
:param google_speech_recognition_input_lang: (str) [Default 'en'] language of the input Check supported languages here: https://cloud.google.com/speech-to-text/docs/languages
:param google_speech_recognition_key: (str) [Default None] api key to use Google Speech API
:param google_speech_recognition_duration_listening: (int) [Default 5] duration of the listening
READ MORE: Google Speech API (Pricing and Key) at: https://cloud.google.com/speech-to-text- Currently, it supports only english language
- Supports voice and text input/output.
- Supports AI based voice input and by using google api voice input.
- All intellectual task is process in JarvisAI server so there is no load on your system.
- Lightweight and able to understand natural language (commands)
- Ability to add your own custom functions.
- you can ask the date: Say- “what is the date today”
- you can ask the time: Say- “what is the time now”
- you can ask joke: Say- “tell me a joke”
- you can ask for news: Say- “tell me the news”
- you can ask weather: Say- “what is the weather”, “tell me the weather”, “tell me about the weather”, “tell me about the weather in < city>”
- you can ask about: Say- “tell me about < topic>”
- you can open website: Say- “open website < website name>”, “open website < website name><.extension>”, “open website techport.in”
- you can play on youtube: Say- “play on youtube < video name>”, “play < video name> on youtube”
- you can send a WhatsApp message: Say- “send WhatsApp message’’
- you can send an email: Say- “send email”
- greet: Say- “greet”, “hello”, “hey”, “hi”, “good morning”, “good afternoon”, “good evening”
- goodbye: Say- “goodbye”, “bye”, “see you later”
- conversation: Say- “conversation”, “chat”, “talk”, “talk with chatbot”
- you can take a screenshot of the current screen: Say- “take screenshot”
- you can click a photo: Say- “click photo”
- you can check internet speed: Say- “check internet speed”
- you can download a youtube video: Say- “download youtube video”
- you can check covid cases: Say- “covid cases in < country>”, “covid cases < country>”
- you can ask to play games: Say- “play games”
- you can ask places near me: Say- "cafe near me"
- you can say : Say- "i am bored"
- you can control volume: Say- "open volume controller"
-
For text input-'
text_inputJust ask input from command line -
For voice input-
voice_input_google_apiIt use google free API. After using few minutes GoogleAPI might restrict you to use it. It's a limitation from GoogleAPI. But it's fast, very accurate and consume very less memory.or
voice_input_deepspeech_streamingJarvisAI's own Machine Learning model to process voice input and convert into text for further processing. Little slow as compared to GoogleAPI, consume more memory, less accurate. But it's free to use and no restriction. -
For text output-
text_outputJust print output in command line -
For voice output-
voice_outputIt use 'gtts' or 'pyttsx3' backend to produce voice output. You can set backend_tts_api.
WIP
You tell me
Instructions Coming Soon
Donate and Contribute to run me this project, and buy a domain
Feel free to use my code, don't forget to mention credit. All the contributors will get credits in this repo.
Mention below line for credits-
Credits-
-
Follow me on Instagram: https://www.instagram.com/dipesh_pal17
-
Subscribe me on YouTube: https://www.youtube.com/dipeshpal17