基金爬虫,爬取天天基金的基金信息、基金经理信息、公司列表
python3.8,三方库未进行版本的测试,应该默认即可。
pip install pandas
pip install sqlalchemy
pip install requests
首先天天基金robots.txt内容如下
User-agent: *
Disallow: /*spm=*
Disallow: /*aladin表示不限制爬虫方式,不能爬取根目录下包含字符串'spm='的文件和根目录下'aladin'结尾的文件
-
公司列表:包含公司名和公司代码
- 示例图

- URL:fund.eastmoney.com/js/jjjz_gs.js
- 示例图
-
基金列表:包含基金名和基金代码
-
基金信息1:包含基金的基本信息
- 示例图:

- URL:http://fund.eastmoney.com/pingzhongdata/'+code+'.js‘ 其中,code为6位整数,如000001的URL位=为http://fund.eastmoney.com/pingzhongdata/000001.js
- 示例图:
-
基金信息2:包含基金风险指标近几年的风险指标-标准差和夏普比率
- 示例图
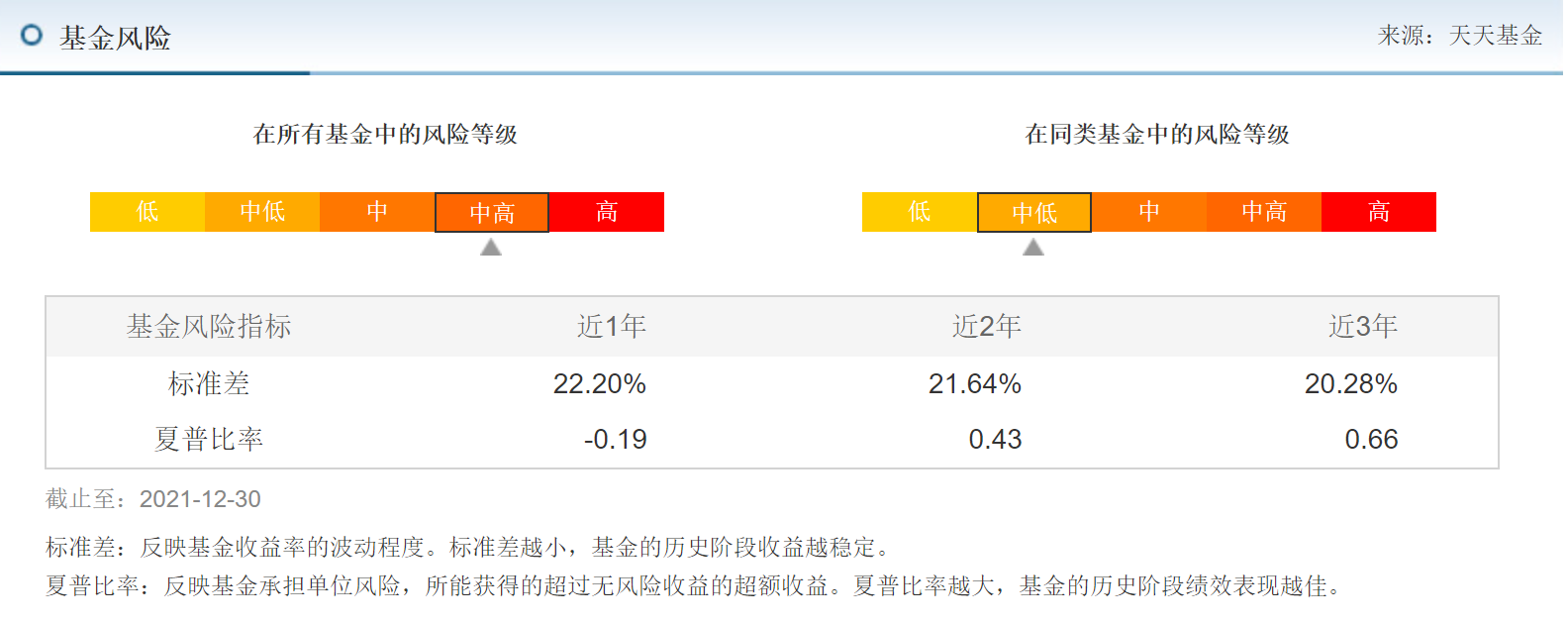
- URL规律:http://fundf10.eastmoney.com/tsdata_'+code+'.html',同上
- 注:天天基金这里进行过更新,老代码中的URL不适用了,现在已经更新
- 示例图

进入main.py执行即可
-
注:除了solve开头的函数依赖于之前函数的下载文件,其他函数之间相互独立无先后顺序可以分别执行
-
数据量太大只上传部分关键数据
-
爬取部分基金信息会提示Failed to get response to url! 大部分情况应该是网站上没有这个基金信息的网页,可以在fail.csv查看失败的基金代码,如果代码有问题欢迎反馈
经issue中用户anshe80的提示,adjusted_net_value.csv表格和/Data/fundInfo/目录都没有生成的方法,后续有时间会修复这个问题,现在可以通过手动创建文件/目录避免。模块之间比较独立, 这个问题不影响其他模块使用。