






English | 中文
Make stream processing easier
A magical framework that make stream processing easier!
Apache Flink and Apache Spark are widely used as the next generation of big data streaming computing engines. Based on a bench of excellent experiences combined with best practices, we extracted the task deployment and runtime parameters into the configuration files. In this way, an easy-to-use RuntimeContext with out-of-the-box connectors would bring easier and more efficient task development experience. It reduces the learning cost and development barriers, hence developers can focus on the business logic. On the other hand, It can be challenge for enterprises to use Flink & Spark if there is no professional management platform for Flink & Spark tasks during the deployment phase. StreamX provides such a professional task management platform, including task development, scheduling, interactive query, deployment, operation, maintenance, etc.

- Apache Flink & Spark application development scaffolding
- Out-of-the-box connectors
- Support maven compilation
- Support multiple versions of Flink & Spark
- Scala 2.11 / 2.12 support
- One-stop stream processing operation platform
- Support catalog、olap、streaming-warehouse etc.
- ...

Streamx consists of three parts,streamx-core,streamx-pump and streamx-console
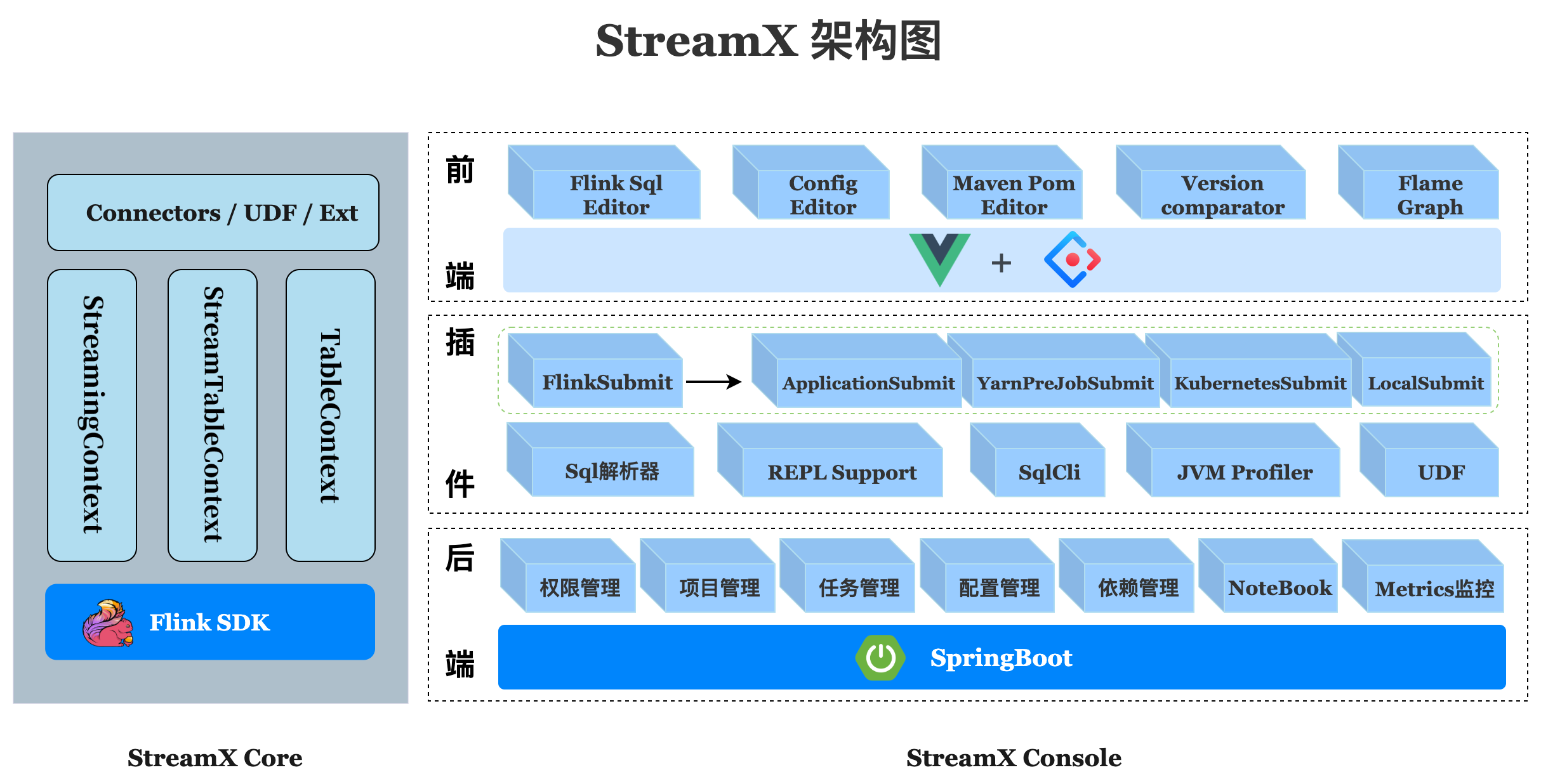
streamx-core is a framework that focuses on coding, standardizes configuration, and develops in a way that is better than configuration by
convention. Also it provides a development-time RunTime Content and a series of Connector out of the box. make application development easier
developer focus on the business itself, and improve development efficiency and development experience.
streamx-pump is a planned data extraction component. Based on the various connector provided in streamx-core, the
purpose is to create a convenient, fast, out-of-the-box real-time data extraction and migration component for big data, and it will be
integrated into the streamx-console.
streamx-console is a stream processing and Low Code platform, capable of managing Flink & Spark tasks, integrating project compilation,
deploy, configuration, startup, savepoint, flame graph, monitoring and many other features. Simplify the daily operation
and maintenance of the Flink & Spark task.
Our ultimate goal is to build a one-stop big data solution integrating stream processing, batch processing, data warehouse.
- Apache Flink
- Apache Spark
- Apache YARN
- Spring Boot
- Mybatis
- Mybatis-Plus
- Flame Graph
- JVM-Profiler
- Vue
- VuePress
- Ant Design of Vue
- ANTD PRO VUE
- xterm.js
- Monaco Editor
- ...
Thanks for the respect given by the above excellent open source projects and many unmentioned excellent open source projects
click Document for more information
Various companies and organizations use StreamX for research, production and commercial products. Are you using this project ? you can add your company

We have received some precious honors, which belong to everyone who contributes to StreamX, Thank you !


You can submit any ideas as pull requests or as GitHub issues.
If you're new to posting issues, we ask that you read How To Ask Questions The Smart Way (This guide does not provide actual support services for this project!), How to Report Bugs Effectively prior to posting. Well written bug reports help us help you!
Thank you to all the people who already contributed to StreamX!
StreamX enters the high-speed development stage, we need your contribution.

