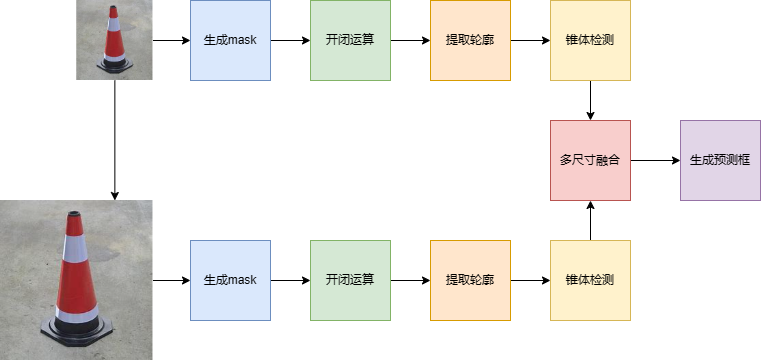
随着自动驾驶的兴起,实时的道路视觉信息处理变得尤为重要。针对道路路障识别这一任务,已经有了很多相关工作。例如使用YOLOv5模型,补齐了YOLO在小目标识别上的劣势。还有最近几年提出ViT架构,将transformer应用到识别任务上取得了很好的性能提升。但是,基于深度学习的方法难以部署到小型设备上,计算成本很高。因此本文提出一种基于多尺度融合和颜色轮廓检测的传统图像处理算法,能够快速地识别出图像或视频中特定颜色的路障。代码开源在Xilluill/traffic_safety_cones (github.com)
传统图像处理的卷积核往往根据人类视觉所能看到的先验特征进行设计,设计、计算成本低。但是也带了很多不足。由于卷积核固定,在不同分辨率,环境下的图像会提取出差异非常大的特征,这往往是灾难性的。因此,本文所提出的算法针对不同尺寸的图像做了优化,能够自适应识别图像中不同大小的路障。
首先,算法设计先筛选出特定颜色的部分,因为大部分路障都是为红色的。在算法的第一阶段,将根据所设置的颜色阈值提取遮罩,生成感兴趣部分。除了红色,算法内部还定义了另一种常用颜色,安全黄,由于安全黄偏绿色,因此很容易和背景中植被干扰。
第二阶段对于感兴趣部分进行形态学计算。开闭运算能够很好的去掉噪点和完善图形轮廓,这可以很好解决图像中少部分与路障颜色相同的部分和连接路障中的反光带部分。比起传统的开闭运算,本文算法使用了非规则卷积核,针对路障的普遍形态,在横向和纵向两个方向上差异性进行开闭运算,能够在一定程度上区分开两个相近的目标。
第三阶段将对所得到的形态图像进行轮廓提取,并用多边形对其逼近。由于开闭运算可能导致凹多边形的出现,因此需要计算出多边形的凸轮廓,并筛选出其中合适的部分。并设计了一个算法对形态进行检测,符合形态的轮廓将被认为是锥体。
第四阶段将图像进行多次缩放,并重复以上步骤,将在不同尺度下得到的预测框,使用非极大值抑制*(Non-Maximum Suppression)*算法去除重叠的部分,得到最终的预测结果。


从常规的OpenCV算法 [2,3] 到YOLOv5深度学习模型 [1],路障识别这个任务已经很好地完成了。但是在计算资源受限地情况下,并没有一个很好的解决方案。尽管有的模型已经足够轻量,但仍有节省计算成本的空间。
网上开源的路障识别项目 [2,3] 都是基于颜色与形态做的一次检测,目标都是提取红色的锥形物体。其中采用固定尺寸5×5的卷积核进行腐蚀和膨胀操作。然而,这种操作无法区分相隔很近的路障,小尺寸的路障也会在第一次腐蚀的时候被当作噪声去掉。
与简单的算法相比,本文提出的算法能够更好地区分挨着的路障,并且通过多次缩放检测出小尺寸目标,同时,基于先验信息,优化了对于锥体形态的判断,使其更加适应路障的特征。
本文提出的算法可以在多个尺寸下进行信息融合,基于Python的OpenCV库实现,以1280×1280分辨率的图像为基础尺寸,进行多次放大,增强小尺寸目标的检测能力。


具体的红色和黄色在HSV色域中的数据可以通过网站非常方便的计算在线调色板、颜色代码、配色方案 (d777.com),也可以通过RGB提取之后转换得到。

在OpenCV中用腐蚀和膨胀交替进行,产生开闭计算的效果。先腐蚀再膨胀即为开计算,先膨胀再腐蚀即为闭计算。第一次处理图像的时候,应进行开计算,将相邻的路障区分开,再进行闭计算,将反光带去除,方便后续轮廓提取。这里,本文提出使用非规则卷积核进行开闭计算,能够防止闭计算的时候重新连接上相邻的图形。
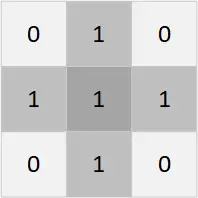
本文采用了一个15×3用于闭计算的卷积核,和1×5、5×1两个单独方向上的卷积核来完成上述的计划。先纵向切开相邻的路障,再横向腐蚀增大距离,再进行闭运算得到整体的形态。

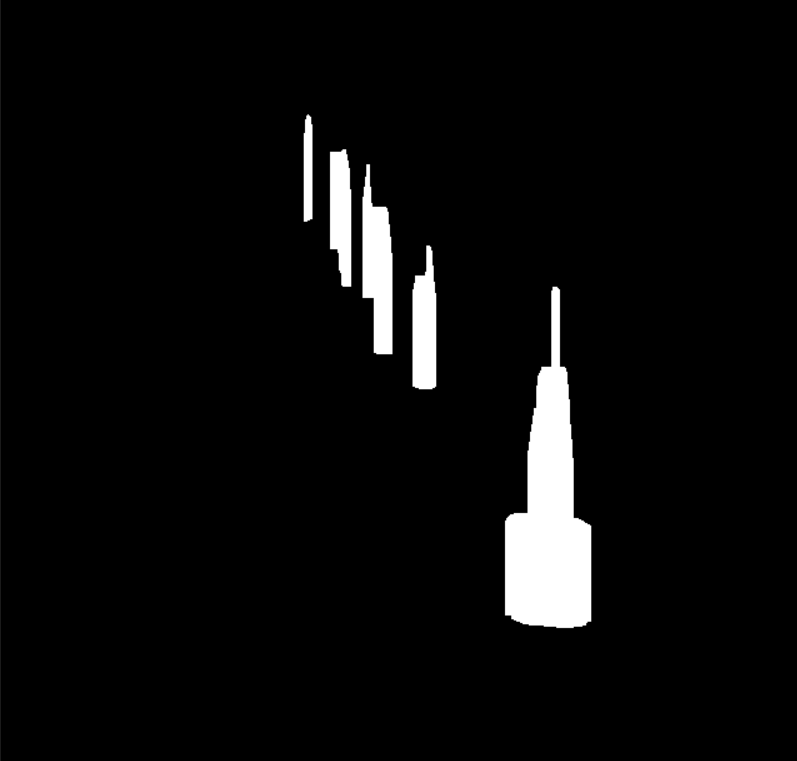

OpenCV内置了提取轮廓的函数、多边形逼近函数、凸包计算函数,再筛选掉点过于多的多边形即可。

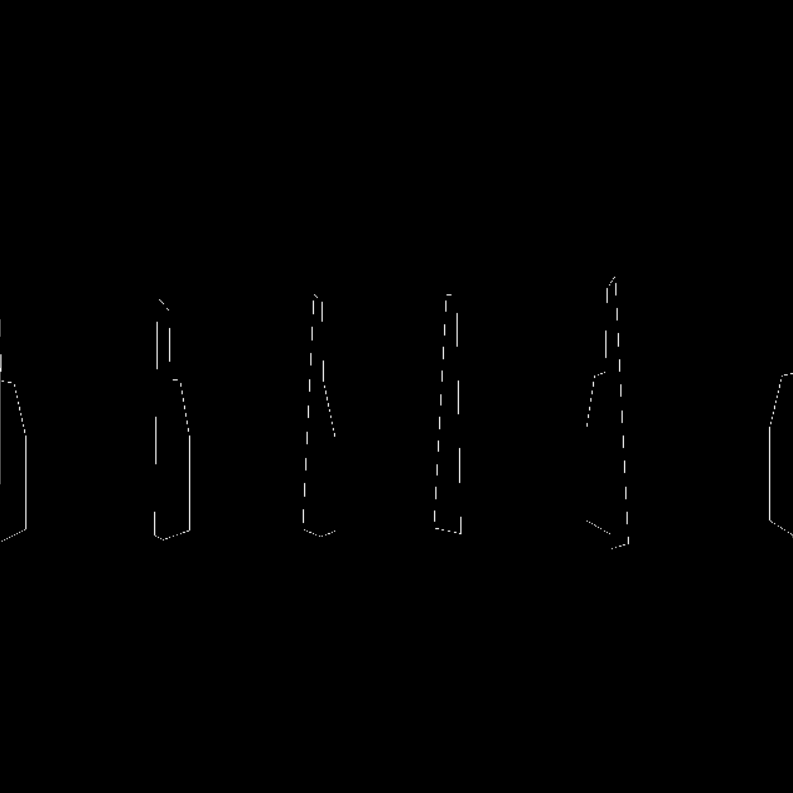
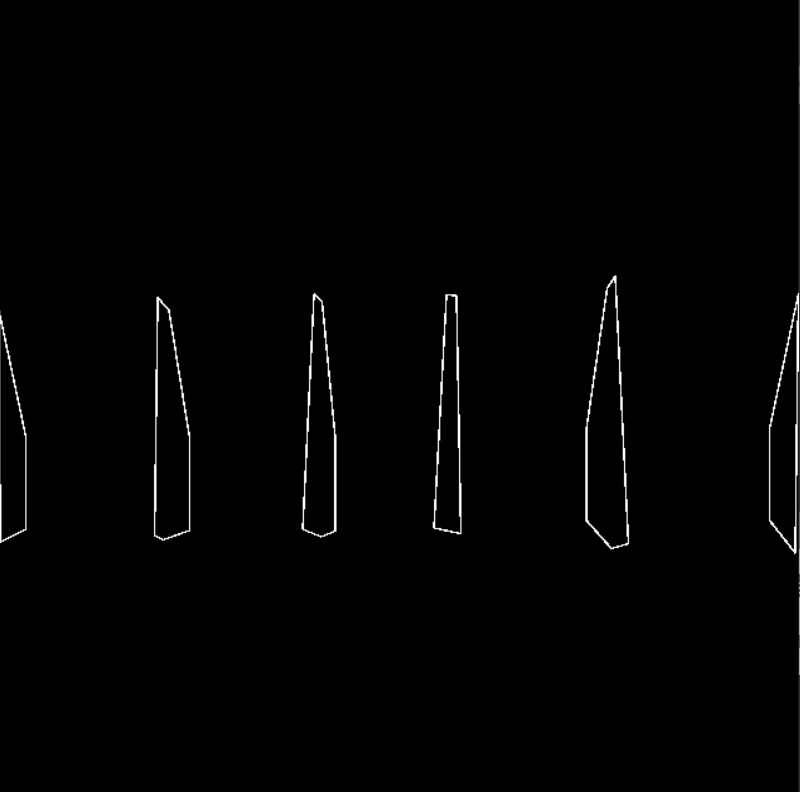
在开源项目 [2,3] 中,锥体提取算法均采用判断垂直中心以上的点是否有超过以下的点最左和最右边界。
然而这种算法无法适应拍摄视角造成的形态变形,我们可以发现经常有轮廓提取出来时,边缘是垂直底边或者稍稍歪出,这是因为进行的腐蚀操作造成的。因此本文使用了一种更加广义的锥体判断准则,即最高部分的边长不超过底长的0.8倍。
这使得部分小尺寸路障的识别成为可能,因为小尺寸路障的轮廓本身就接近矩形,在视角的影响下就是会出现向外侧歪曲的情况。
为了融合不同尺寸图像的信息,本文结合YOLO算法的**,将修改后非极大值抑制*(Non-Maximum Suppression)*算法应用置本文算法中。由于算法输出的box并没有置信度,因此选择box的高度作为得分项进行非极大值抑制,这样做的好处是能够将过于长的反光带造成的多次检测去除。
交并比*(Intersection over Union)是目标检测NMS的依据,衡量边界框位置,常用交并比指标,交并比(Injection Over Union,IOU)发展于集合论的雅卡尔指数(Jaccard Index)。而在本文中,为了更好的去除小尺寸box*,增加了另一判据进行抑制。 $$ Percent=\frac{\textit{两者相交的面积}}{\textit{两者之间更小的box的面积}} $$ 由于大尺寸图像能够检测出更精细的box,因此本文认为在进行抑制的时候,大尺寸的图片的结果应该被保留,但是大尺寸图像也会产生被反光带分割的box,两者如何兼顾还需要进一步研究。



本文设计了在八张图上进行测试,其中image_3和image_5包含黄色路障,在其他六张图上进行测试时均不开启黄色检测,默认设置融合1280×1280和2560×2560两个尺寸的图像。
实验标准是准确率为目标数与图片中的红色路障的比值,误检率指非路障物体被检测的比值,多个路障仅预测出一个路障按一个正确计算。因反光带造成的预测框缩小不算错误,认为是正确识别。
| 颜色 | 形态 | 多尺寸 | 准确率 | 误检率 |
|---|---|---|---|---|
| 红色 | 未改良锥体检测 | 未进行融合 | 42.4% | 3% |
| 红色 | 改良锥体检测 | 未进行融合 | 45.4% | 3% |
| 红色 | 未改良锥体检测 | 进行融合 | 57.5% | 21% |
| 红色 | 改良锥体检测 | 进行融合 | 60.6% | 21% |
在多路障小尺寸场景中,不进行多尺寸融合基本无法识别到路障,并且为改良的锥体检测可能会将小尺寸的预测框筛除,因此本文所设计的缩放增强了原先算法的鲁棒性,并在多路障小尺寸场景有更优异的性能。
而由于多尺寸融合也会带来更高的误检率,场景中的类似颜色的像素区域也会被检测到,但是误检预测框多为非常小型的预测框,可以通过计算直接去除。但是从第一阶段颜色提取开始,就已经无法区分干扰像素块和小尺寸路障了,这也是传统图像处理算法的局限性,单一的颜色提取会损失过多的信息。
| 多尺度融合具体参数 | 准确率 | 误检率 |
|---|---|---|
| 1280×1280,2560×2560 | 60.6% | 21% |
| 1280×1280,2560×2560,5120×5120 | 69.7% | 51.5% |
| 1280×1280,2560×2560,5120×5120,10240×10240 | 78.8% | 51.5% |
在高分辨率的融合下,小尺寸识别能力得到显著提升,在image_4和image_8多路障小尺寸场景中,普通算法无法检出路障,而在增加分辨率融合后,检出数量逐步提升。受限于测试集过少,无法进一步衡量算法性能和进行消融实验。但已经能看出,本文提出的算法性能明显由于普通的路障识别算法。
本文提出了一个使用多尺度融合和优化锥体检测的路障识别算法。算法能够提取道路图像中的特定颜色的锥形路障,并且能通过多尺度融合适应不同尺寸的路障影像信息。算法整体是传统的,没有涉及到深度学习,因此算法时间复杂度低,效率高,实时性好。在各类场景的图像测试的结果证明了该算法的有效性和通用性。
[1] Katsamenis, I. et al. (2023). TraCon: A Novel Dataset for Real-Time Traffic Cones Detection Using Deep Learning. In: Krouska, A., Troussas, C., Caro, J. (eds) Novel & Intelligent Digital Systems: Proceedings of the 2nd International Conference (NiDS 2022). NiDS 2022. Lecture Notes in Networks and Systems, vol 556. Springer, Cham. https://doi.org/10.1007/978-3-031-17601-2_37