This project implements our paper AdaRNN: Adaptive Learning and Forecasting for Time Series at CIKM 2021. Please refer to our paper [1] for the method and technical details. Paper video | Zhihu article
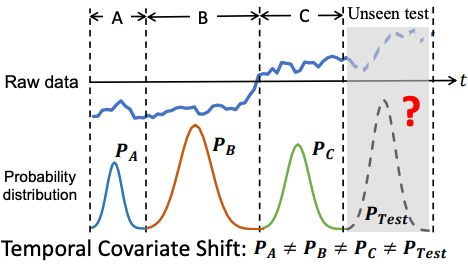
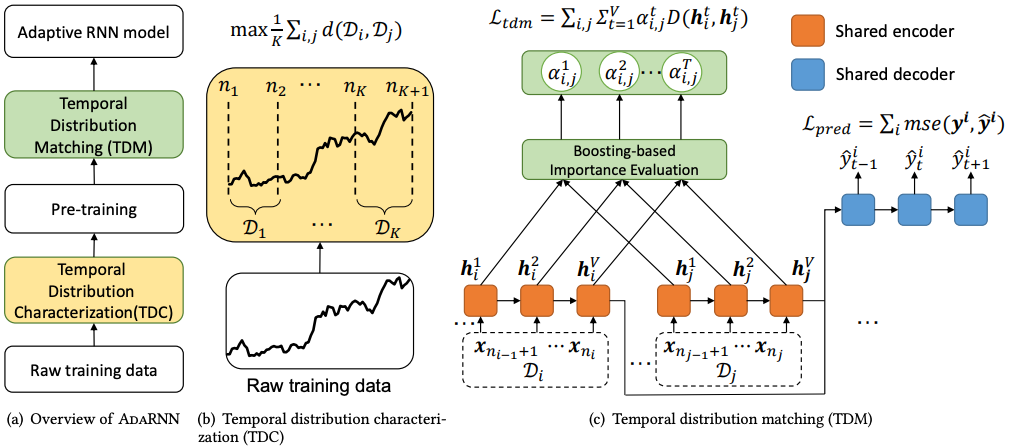
Abstract: Time series has wide applications in the real world and is known to be difficult to forecast. Since its statistical properties change over time, its distribution also changes temporally, which will cause severe distribution shift problem to existing methods. However, it remains unexplored to model the time series in the distribution perspective. In this paper, we term this as Temporal Covariate Shift (TCS). This paper proposes Adaptive RNNs (AdaRNN) to tackle the TCS problem by building an adaptive model that generalizes well on the unseen test data. AdaRNN is sequentially composed of two novel algorithms. First, we propose Temporal Distribution Characterization to better characterize the distribution information in the TS. Second, we propose Temporal Distribution Matching to reduce the distribution mismatch in TS to learn the adaptive TS model. AdaRNN is a general framework with flexible distribution distances integrated. Experiments on human activity recognition, air quality prediction, and financial analysis show that AdaRNN outperforms the latest methods by a classification accuracy of 2.6% and significantly reduces the RMSE by 9.0%. We also show that the temporal distribution matching algorithm can be extended in Transformer structure to boost its performance.
To use this code, you can either git clone this transferlearning repo, or if you just want to use this folder, you can go to this site to paste the url of this code (https://github.com/jindongwang/transferlearning/edit/master/code/deep/adarnn) and then download just this folder.
- CUDA 10.1
- Python 3.7.7
- Pytorch == 1.6.0
- Torchvision == 0.7.0
The required packages are listed in requirements.txt.
The original air-quality dataset is downloaded from Beijing Multi-Site Air-Quality Data Data Set . The air-quality dataset contains hourly air quality information collected from 12 stations in Beijing from 03/2013 to 02/2017. We randomly chose four stations (Dongsi, Tiantan, Nongzhanguan, and Dingling) and select six features (PM2.5, PM10, S02, NO2, CO, and O3). Since there are some missing data, we simply fill the empty slots using averaged values. Then, the dataset is normalized before feeding into the network to scale all features into the same range. This process is accomplished by max-min normalization and ranges data between 0 and 1. The processed air-quality dataset can be downloaded at dataset link.
The procossed .pkl files contains three arraies: 'feature', 'label', and 'label_reg'. 'label' refers to the classification label of air quality (e.g. excellence, good, middle), which is not used in this work and could be ignored. 'label_reg' refers to the prediction value.
The code for air-quality dataset is in train_weather.py. After downloading the dataset, you can change args.data_path in train_weather.py to the folder where you place the data.
Then you can run the code. Taking Dongsi station as example, you can run
python train_weather.py --model_name 'AdaRNN' --station 'Dongsi' --pre_epoch 40 --dw 0.5 --loss_type 'adv' --data_mode 'tdc'
For transformer model, the adapted transformer model is in transformer_adapt.py, you can run,
python transformer_adapt.py --station 'Tiantan' --dw 1.0
Air-quality dataset
| Dongsi | Tiantan | Nongzhanguan | Dingling | |||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | |
| FBProphet | 0.1866 | 0.1403 | 0.1434 | 0.1119 | 0.1551 | 0.1221 | 0.0932 | 0.0736 |
| ARIMA | 0.1811 | 0.1356 | 0.1414 | 0.1082 | 0.1557 | 0.1156 | 0.0922 | 0.0709 |
| GRU | 0.0510 | 0.0380 | 0.0475 | 0.0348 | 0.0459 | 0.0330 | 0.0347 | 0.0244 |
| MMD-RNN | 0.0360 | 0.0267 | 0.0183 | 0.0133 | 0.0267 | 0.0197 | 0.0288 | 0.0168 |
| DANN-RNN | 0.0356 | 0.0255 | 0.0214 | 0.0157 | 0.0274 | 0.0203 | 0.0291 | 0.0211 |
| LightGBM | 0.0587 | 0.0390 | 0.0412 | 0.0289 | 0.0436 | 0.0319 | 0.0322 | 0.0210 |
| LSTNet | 0.0544 | 0.0651 | 0.0519 | 0.0651 | 0.0548 | 0.0696 | 0.0599 | 0.0705 |
| Transformer | 0.0339 | 0.0220 | 0.0233 | 0.0164 | 0.0226 | 0.0181 | 0.0263 | 0.0163 |
| STRIPE | 0.0365 | 0.0216 | 0.0204 | 0.0148 | 0.0248 | 0.0154 | 0.0304 | 0.0139 |
| ADARNN | 0.0295 | 0.0185 | 0.0164 | 0.0112 | 0.0196 | 0.0122 | 0.0233 | 0.0150 |
@inproceedings{Du2021ADARNN,
title={AdaRNN: Adaptive Learning and Forecasting for Time Series},
author={Du, Yuntao and Wang, Jindong and Feng, Wenjie and Pan, Sinno and Qin, Tao and Xu, Renjun and Wang, Chongjun},
booktitle={Proceedings of the 30th ACM International Conference on Information \& Knowledge Management (CIKM)},
year={2021}
}