![]()
🌏 NeRF the globe if you want
There are many one-of-a-kind highlights in the LandMark:
- Large-scale, high-quality novel view rendering:
- For the first time, we realized efficient training of 3D neural scenes on over 100 square kilometers of city data; and the rendering resolution reached 4K. We used over 200 billion learnable parameters to model the scene.
- Multiple feature extensions:
- Beyond rendering, we showcased layout adjustments such as removing or adding buildings, and scene stylization with alternative appearances such as changes of lighting and seasons.
- Training, rendering integrated system:
- We delivered a system covering algorithms, operators, and computing systems, which serves as a solid foundation for the training, rendering, and application of real-world 3D large models.
The LandMark supports multiple types of parallel strategies. With the strategies, we achieve huge NeRF speedups and make the NeRF truly applicable to city-scale reconstruction. These parallel strategies mainly include the following types:
Here we present how our Parallel methods work. Basic knowledge of NeRF are needed for better understanding.
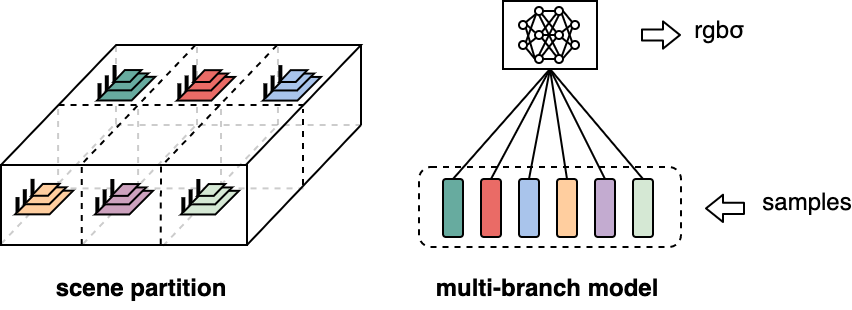
The scene area is divided into multiple scene blocks. Correspondingly, the model changes from having a single large grid to multiple sub-grids. with each sub-grid representing a scene block.
All sub-grids share the same MLPs to decode features and output rgbσ. All the sub-grid and the shared MLPs constitute a complete multi-branch large model.
When a point sampled along the ray is fed into the multi-branch model, it is first assigned to the corresponding sub-grid based on its coordinate, and then inferred with this branch.
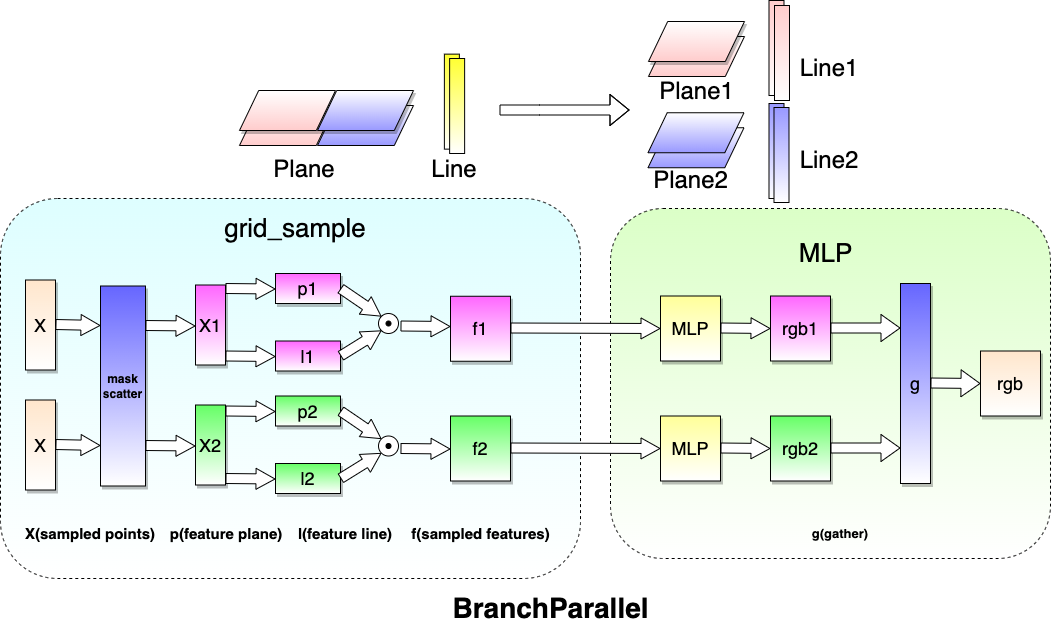
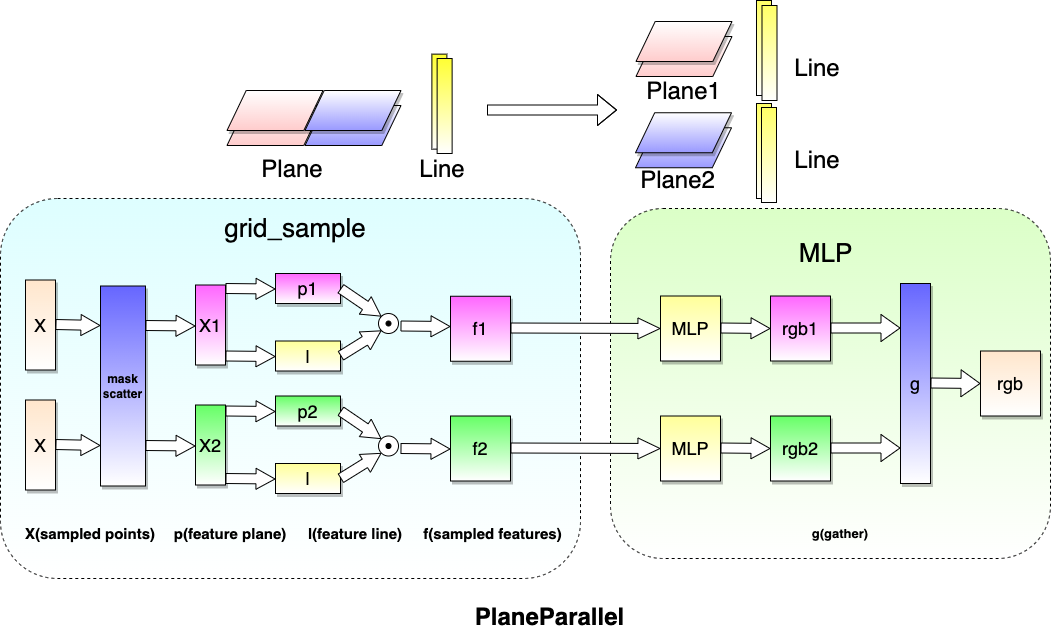
Plane parallel divides the full plane into multiple sub-plane, and then scatters to different devices. Thus, each device holds a part of the full plane. Apart from the plane, the remaining modules are replicated across all devices, and their parameters are shared among all devices.
During training, when a point sampled along the ray is fed into the model, it is first assigned to the sub-plane and the corresponding device based on its x-y coordinate, and then inferred on the device to get its rgbσ value. After inferring a batch of points, the rgbσ values are gathered across all devices.
After training with plane parallel, the weights of all sub-planes can be merged into a full plane. In this way, the model trained with plane parallel can be rendered just like a single model.
Alternatively, the plane weights keep separate without merging, then the model is rendered just following the inferring way in training.
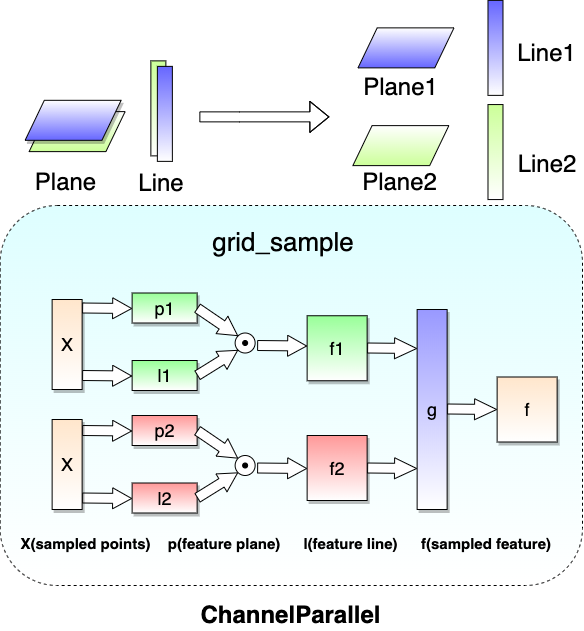
In channel parallel, both feature plane and feature line are shared along the channel dimension. The features computed by grid_sample are also shared along the channel dimension. Then we can get a full-channel feature if we do gather/all-gather on these shared features.