论文地址:Character Region Awareness for Text Detection
作者推理部分的代码:clovaai/CRAFT-pytorch
本文用Keras实现了CRAFT文本检测算法,通过预测单个字符的高斯热图以及字符间的连接性来检测文本。

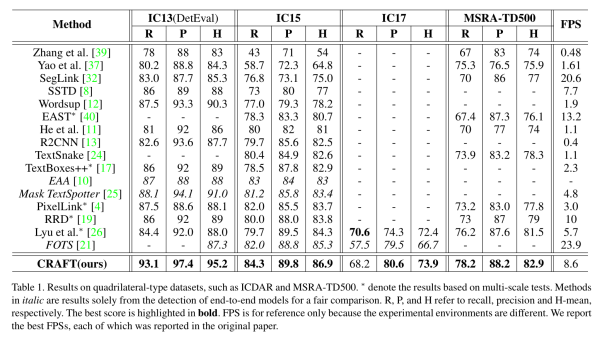
主干网络采用了VGG16-BN,上采用部分设计了一个UpConv Block结构,网络最终在1/2图上产生两个输出:
1、Region score:字符级的高斯热图
2、Affinity score:字符间连接的高斯热图
VGG16采用Keras自带的,没有加入BN
输出的热图增加sigmoid激活函数,原作没有采用任何激活函数
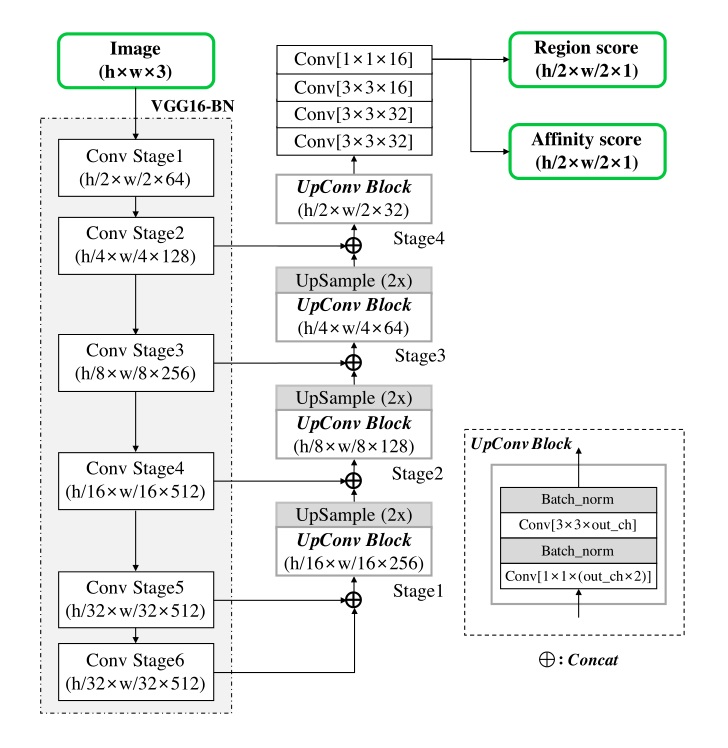
1、连接Character Box对角线,得到上三角形和下三角形。
2、连接相邻两个字符的上三角形和下三角形中心,得到Affinity Box。
1、连接Character Box对角线,得到2对三角形,上三角形(T)和下三角形(B),左三角形(L)和右三角形(R)。
2、字符1的2对三角形与字符2的两对三角形进行组合,产生4种组合情况,每组4个三角形。
3、每组4个三角形构成一个候选的Affinity Box。
4、选出其中面积最大且为凸四边形的Affinity Box。(面积最大的方法有待验证)
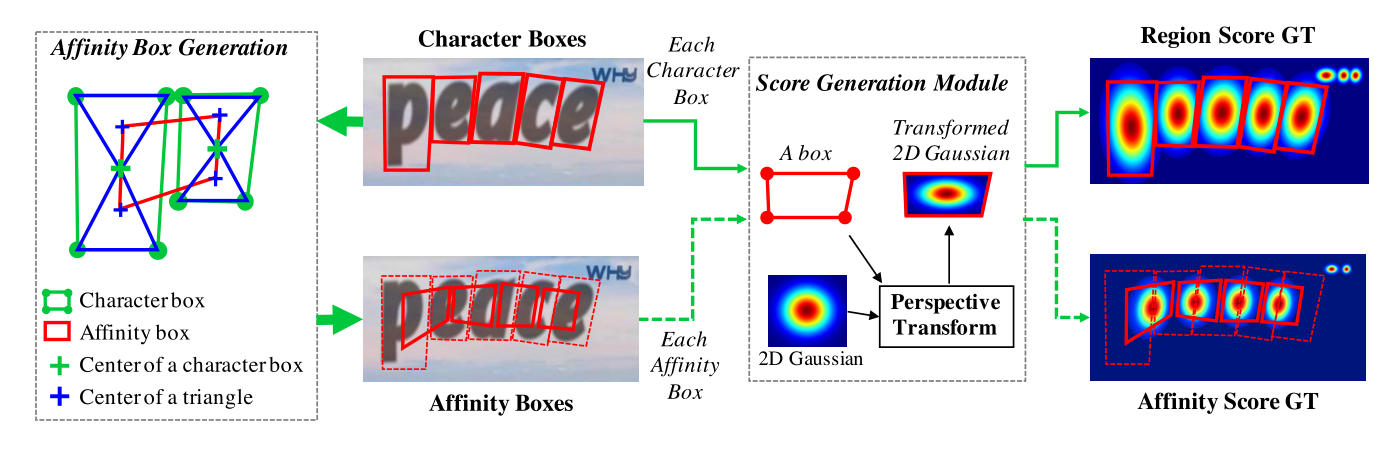
参考CornerNet生成一个正方形的2D高斯热图。
Github:princeton-vl/CornerNet
使用Opencv中的PerspectiveTransform计算出对应形状的高斯热图,热图出现重合时,本文参考CenterNet的做法,取分数最大值。
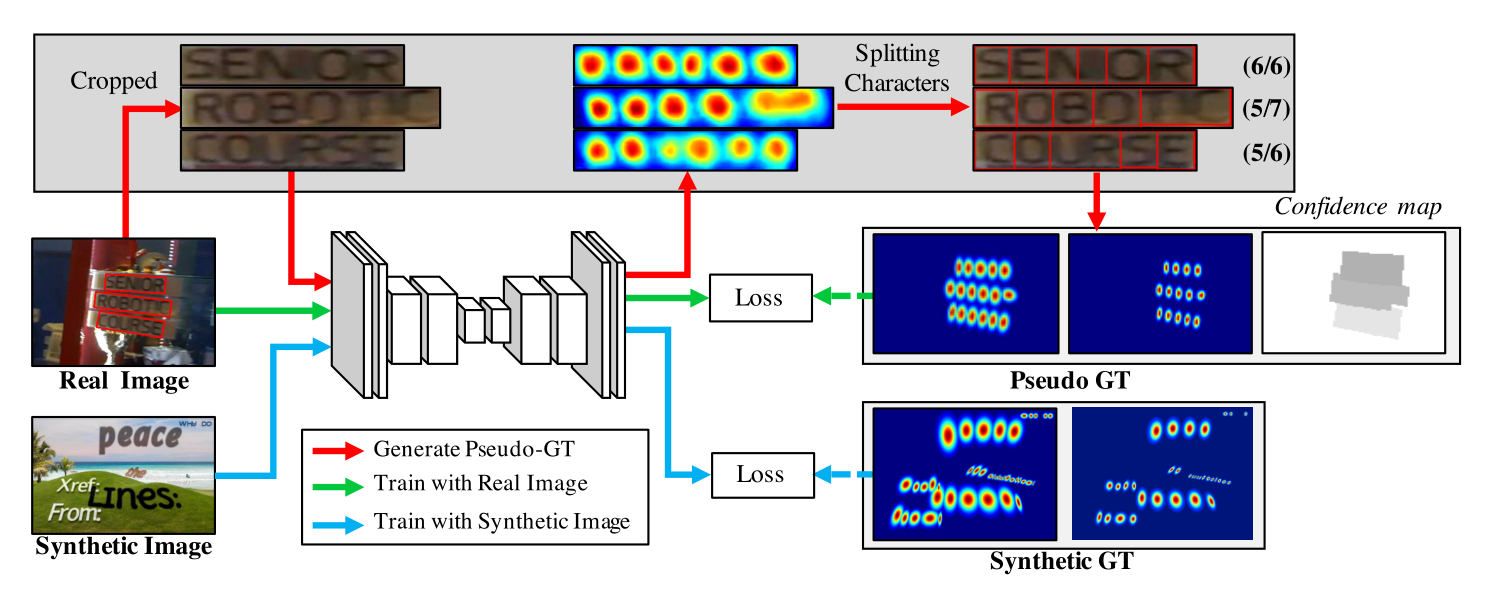 模型训练有两个关键部分:Confidence map计算和Loss计算。
模型训练有两个关键部分:Confidence map计算和Loss计算。
对于只有Word级而无Character级标签的数据集(如ICDAR2013、ICDAR2015),由于弱监督产生的Character级标签并不一定准确,论文中加入了Confidence来对伪标签进行打分。
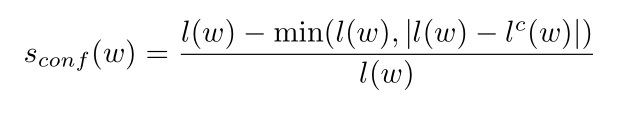
其中, l(w) 表示Word包含的字符个数, l^{c}(w) 表示伪标签中Character Box的个数。
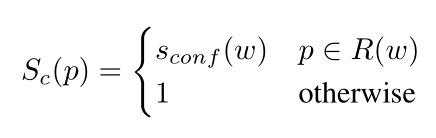
R(w) 表示生成伪标签的区域
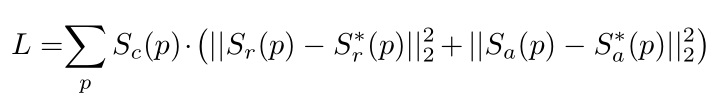
其中,S_{r}(p)和S_{a}(p) 分别表示网络输出的region score和affinity score, S_{r}^{}(p) 和S_{a}^{}(p) 分别表示Region Score GT和Affinity Score GT。
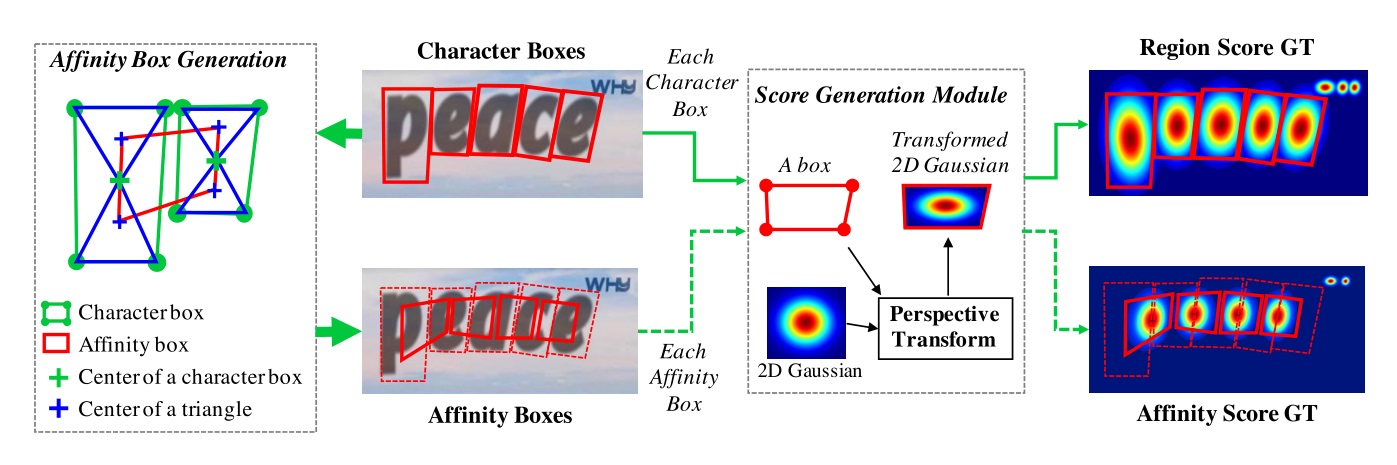
对于只有Word级而无Character级标签的数据集(如ICDAR2013、ICDAR2015),需要生成Character级的标签。
使用Word级的Box坐标crop出文本图像
使用当前训练的模型预测出文本图像的Region Score Map。
使用分水岭算法分割Region Score Map,得到Character Box的坐标。
将Character Box的坐标转换回原坐标
使用当前训练的模型预测出图像的Region Score Map。
使用Word级的Box坐标crop出局部的Region Score Map。
使用分水岭算法分割Region Score Map,得到Character Box的坐标。
将Character Box的坐标转换回原坐标
下面贴出作者在Github上给出的回复
I just followed the instruction provided by opencv document (https://docs.opencv.org/3.3.1/d3/db4/tutorial_py_watershed.html).
We used thresholding for the binary maps for finding three areas such as sure_fg, sure_bg, and unknown in the example.
Two thresholds are used for separating those areas, and the values are 0.6 and 0.2, respectively.
These thresholds are not sensitive for distinguishing those areas since they play a role of the initial guess for the watershed labeling. The initial markers are created by labeling the regions inside surely foreground area.
In addition, we used opencv watershed labeling function.
在强标签数据(SynthText)上进行强监督训练,迭代50k次。
在其他数据集上进行fine-tuning,强标签数据和弱标签数据混合训练。
fine-tuning期间,弱标签数据和强标签数据按照1:5的比例进行训练,从而保证字符级标签的准确性。
对于ICDAR2015和ICDAR2017中部分“DO NOT CARE”的文本在训练阶段将Confidence设置为0。
常用的数据增强,如:Crops,rotations,and/or color variations。
使用Adam优化器进行训练。
按照1:3使用OHEM。
由于直接使用了作者的推理代码,此处就不详细说明了。