- 文本类别数:>=10类。
- 训练集文档数:>=500000篇;每类平均50000篇。
- 测试机文档数:>=500000篇;每类平均50000篇。
利用朴素贝叶斯算法实现对文本的数据挖掘,主要包括:
- 语料库的构建,主要包括利用爬虫收集Web文档等。
- 语料库的数据预处理,包括文档建模,如去噪,分词,建立数据字典。
- 自行实现朴素贝叶斯,训练文本分类器。
- 对测试集的文本进行分类
- 对测试集的分类结果利用正确率和召回率进行分析评价。
- 部分原始爬取数据

- 对爬取数据进行分词、去除停用词

- 经过TF_IDF处理

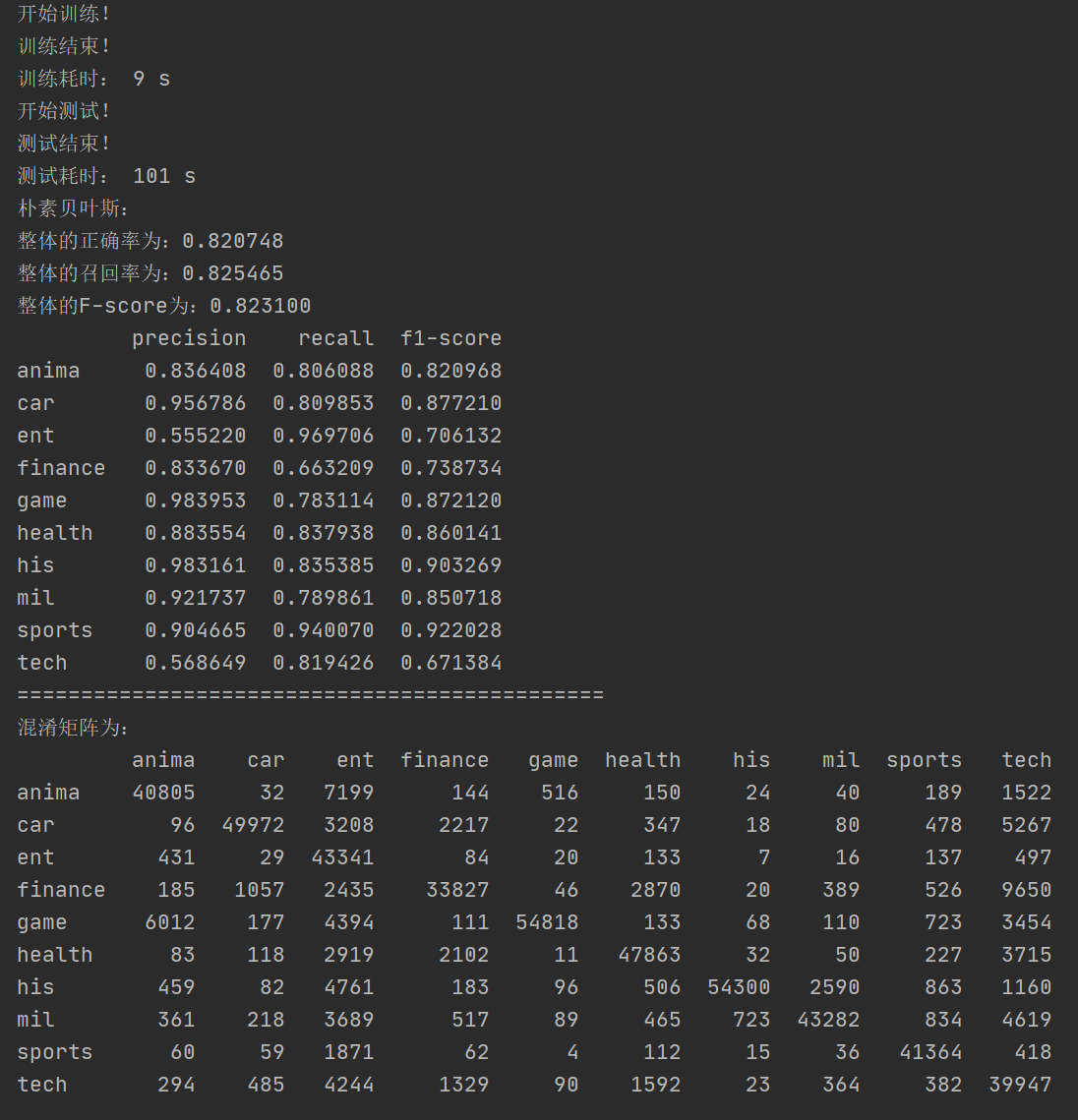
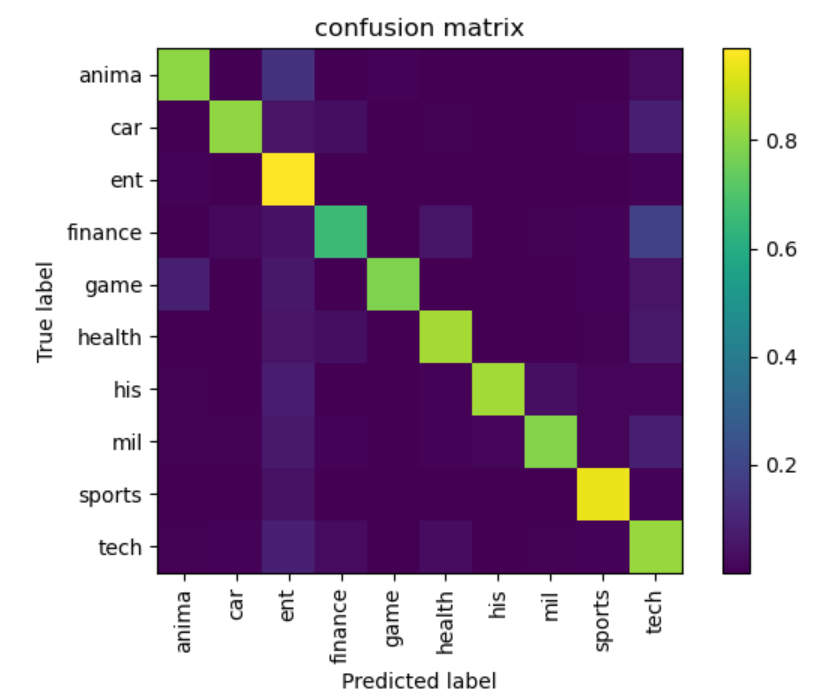
- 50w条测试集的测试结果