有很多小伙伴发邮件问我要数据,由于年代久远,原始数据我已经找不到了,其实就是把点云数据按 x y z 一行行写成一个文本txt就行
三维点云激光分类(建筑,树木)


首先去除地面,(滤波,随机采样等均可),利用连通性分析分离点云,同时删除点云个数小于20个点的点云快。(剔除一些杂点,不太便于辨别形状的点)。




由于树木和建筑直观上看还是比较好区分的,因此取两个特征值组成特征向量分类效果还可以。





KNN算法很多库都有,C#里有Alglib,Python的一个强大的第三方库sklearn里面也有封装


老师上课PPT里有的一个东西,一开始没怎么懂,后来在《遥感学报》上看到了一篇论文用到了这个来做分类,实践了下后懂了原理,就是通过计算协方差阵的特征值来描述点云的分布。

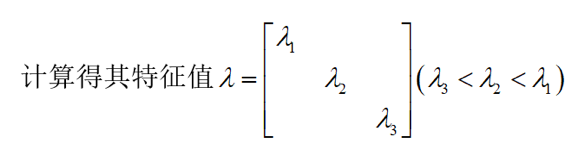

![来源:遥感学报,马振宇,庞勇,李增元,卢昊,刘鲁霞,陈博伟.地基激光雷达森林近地面点云精细分类与倒木提取 [J].遥感学报,2019, 23(4)。](https://img-blog.csdnimg.cn/20191129225959407.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NDE4MDIzNg==,size_16,color_FFFFFF,t_70)
如果面状性较好的话,可以知道会有两个特征值大小接近,一个特征值很小;如果点云很分散的话,那么3个特征值的大小应该是比较接近的。



我用的是python里Sklearn库里面SVM,sklearn也安利一下,基本常见的机器学习算法里面都有封装好。





完整代码以及点云可以访问Github https://github.com/YhQIAO/PointCloudSVMDemo.git
程序结构说明 依赖文件: MyHelper.py:封装计算特征值和特征向量的函数。 FileOperator.py: 封装文件读取和写入功能。 程序运行: 1.首先运行SaveFV.py,读取./points/trees以及./points/buildings中的训练样本数据,计算特征值,设树木标签为1,建筑标签为-1。保存的文件位于./FeatureVectors.txt。 2.再运行svmdemo.py,训练支持向量机分类器,并且读取待分类数据(位于./points/testdata/data1文件夹下),若分类为树木,则在每一点坐标后添加0 255 0,使其在导入CloudCompare时颜色为绿色;若分类为建筑,则在每一点坐标后添加0 0 255,使其在导入CloudCompare时颜色为蓝色。
测试步骤: 1.运行SaveFV.py,提取样本数据的特征向量,保存于FeatureVectors.txt文件中。 2.运行svmdemo.py,训练分类器,并对待分类数据进行分类 3.在CloudCompare中查看分类结果(蓝色的表示分类为建筑,绿色表示分类为树木)
文件路径格式说明 本程序运行在MacOS(类Unix,Linux)系统上,文件路径格式为./…/… ,若在windows环境下运行,需修改文件路径格式。如./points/trees需修改为D:\points\trees。
文件内容说明 所有点云数据在./points文件夹内 ./points/buildings内为建筑样本 ./points/trees内为树木样本 ./points/testdata/data1 为BlockA_FULLA.txt测试数据 ./points/testdata/data2 为BlockB_FULL.txt测试数据 ./points/testdata/resultdata 为分类完成后的点云数据