- Introduction
- Citation
- For Applications
- For Research
- Available Models and Audio Tagging Performance
- License
- Contact
[HuggingFace Space] (Try Whisper-AT without Coding!)
[Local Notebook Demo](for user without Colab access)
cooking.mp4
Whisper-AT is a joint audio tagging and speech recognition model. It inherits strong speech recognition ability from OpenAI Whisper, and its ASR performance is exactly the same as the original Whisper. The API interface and usage are also identical to the original OpenAI Whisper, so users can seamlessly switch from the original Whisper to Whisper-AT.
The advantage of Whisper-AT is that with minimal (less than 1%**) additional computational cost, Whisper-AT outputs general audio event labels (527-class AudioSet labels) in desired temporal resolution in addition to the ASR transcripts. This makes audio tagging much easier and faster than using a standalone audio tagging model.
Internally, Whisper-AT freezes all original Whisper parameters, and trains a Time- and Layer-wise Transformer (TL-TR) on top of the Whisper encoder representations for the audio tagging task.
To help better understand the pros and cons of this work, we have attached the anonymous reviews and our responses [here]. We thank the anonymous reviewers' invaluable comments.
** Not for all models, see the paper for details.
Quick Start (Run in 8 lines of code)
In shell,
pip install whisper-at
For Mac/Windows users, there is a known bug, please use the following workaround:
# install all dependencies except triton
pip install numba numpy torch tqdm more-itertools tiktoken==0.3.3
# install whisper-at without any dependency
pip install --no-deps whisper-at Then, in Python,
import whisper_at as whisper
audio_tagging_time_resolution = 10
model = whisper.load_model("large-v1")
result = model.transcribe("audio.mp3", at_time_res=audio_tagging_time_resolution)
# ASR Results
print(result["text"])
# Audio Tagging Results
audio_tag_result = whisper.parse_at_label(result, language='follow_asr', top_k=5, p_threshold=-1, include_class_list=list(range(527)))
print(audio_tag_result)Please cite our Interspeech 2023 paper if you find this repository useful.
@inproceedings{gong_whisperat,
author={Gong, Yuan and Khurana, Sameer and Karlinsky, Leonid and Glass, James},
title={Whisper-AT: Noise-Robust Automatic Speech Recognizers are Also Strong Audio Event Taggers},
year=2023,
booktitle={Proc. Interspeech 2023}
}
The best way to learn how to use Whisper-AT is this [Colab Tutorial]. You can skip all below if you read it. If you don't have Google Colab access (uncommon), you can use this [Local Notebook] as a substitution.
If you do not care how Whisper-AT is implemented, but just want to use it, you only need to read this section. This will be very simple.
We intentionally do not any additional dependencies to the original Whisper. So if your environment can run the original Whisper, it can also run Whisper-AT.
Whisper-AT can be installed simply by:
pip install whisper-at
For Mac/Windows users, there is a known bug, please use the following workaround:
# install all dependencies except triton
pip install numba numpy torch tqdm more-itertools tiktoken==0.3.3
# install whisper-at without any dependency
pip install --no-deps whisper-at Note that following original Whisper, it also requires the command-line tool ffmpeg to be installed on your system. Please check OpenAI Whisper repo for details.
# note this is whisper"_"at not whisper-at
import whisper_at as whisper
# the only new thing in whisper-at
# specify the temporal resolution for audio tagging, 10 means Whisper-AT predict audio event every 10 seconds (hop and window=10s).
audio_tagging_time_resolution = 10
model = whisper.load_model("base")
# for large, medium, small models, we provide low-dim proj AT models to save compute.
# model = whisper.load_model("large-v1", at_low_compute=Ture)
result = model.transcribe("audio.mp3", at_time_res=audio_tagging_time_resolution)
print(result["text"])
## translation task is also supported
# result = model.transcribe("audio.mp3", task='translate', at_time_res=audio_tagging_time_resolution)
# print(result["text"])result["text"] is the ASR output transcripts, it will be identical to that of the original Whisper and is not impacted by at_time_res, the ASR function still follows Whisper's 30 second window. at_time_res is only related to audio tagging.
Compared to the original Whisper, the only new thing is at_time_res, which is the hop and window size for Whisper-AT to predict audio events. For example, for a 60-second audio, setting at_time_res = 10 means the audio will be segmented to 6 10-second segments, and Whisper-AT will predict audio tags based on each 10-second segment,
a total of 6 audio event predictions will be made. Note at_time_res must be an integer multiple of 0.4, e.g., 0.4, 0.8, ..., the default value is 10.0, which is the value we use to train the model and should lead to best performance.
Compared with the original Whisper, result contains a new entry called audio_tag. result['audio_tag'] is a torch tensor of shape [⌈audio_length/at_time_res⌉, 527]. For example, for a 60-second audio and at_time_res = 10, result['audio_tag'] is a tensor of shape [6, 527]. 527 is the size of the AudioSet label set, result['audio_tag'][i,j] is the (unnormalised) logits of class j of the ith segment.
If you are familiar with audio tagging and AudioSet, you can take raw result['audio_tag'] for your usage. But we also provide a tool to make it easier.
You can feed the result to whisepr.parse_at_label
audio_tag_result = whisper.parse_at_label(result, language='follow_asr', top_k=5, p_threshold=-1, include_class_list=list(range(527)))
print(audio_tag_result)
# Outputs (audio tag, unnormalised logits):
# {'time': {'start': 0, 'end': 10}, 'audio tags': [('Music', 1.821943759918213), ('Speech', 0.9335958957672119)]}
# {'time': {'start': 10, 'end': 20}, 'audio tags': [('Music', 1.3550536632537842), ('Grunge', -1.3502553701400757), ('Progressive rock', -1.424593210220337), ('Punk rock', -1.5715707540512085)]}
# {'time': {'start': 20, 'end': 30}, 'audio tags': [('Music', 0.8052308559417725)]}Input Arguments of whisper.parse_at_label:
result: The result dict returned by the whisper-at transcribe function.language: The audio tag label name language, e.g., 'en', 'zh'. Default='follow_asr', i.e., same with the ASR result.top_k: Output up to k sound classes that have logits abovep_threshold. Default=5.p_threshold: The logit threshold to predict a sound class. Default=-1.include_class_list: A list of indexes that of interest. Default = list(range(527)) (all classes).
Return: A dictionary of audio tagging results.
This makes the audio tagging result human-readable, in specified language. If not specified, whisepr.parse_at_label output label names in the same language with the ASR output.
That's it!
If you are interested in the findings and experiments in our Interspeech paper Whisper-AT: Noise-Robust Automatic Speech Recognizers are Also Strong Audio Event Taggers, please check this section. We provide our code to reproduce the experiments in the paper.
The paper mainly contains two contributions:
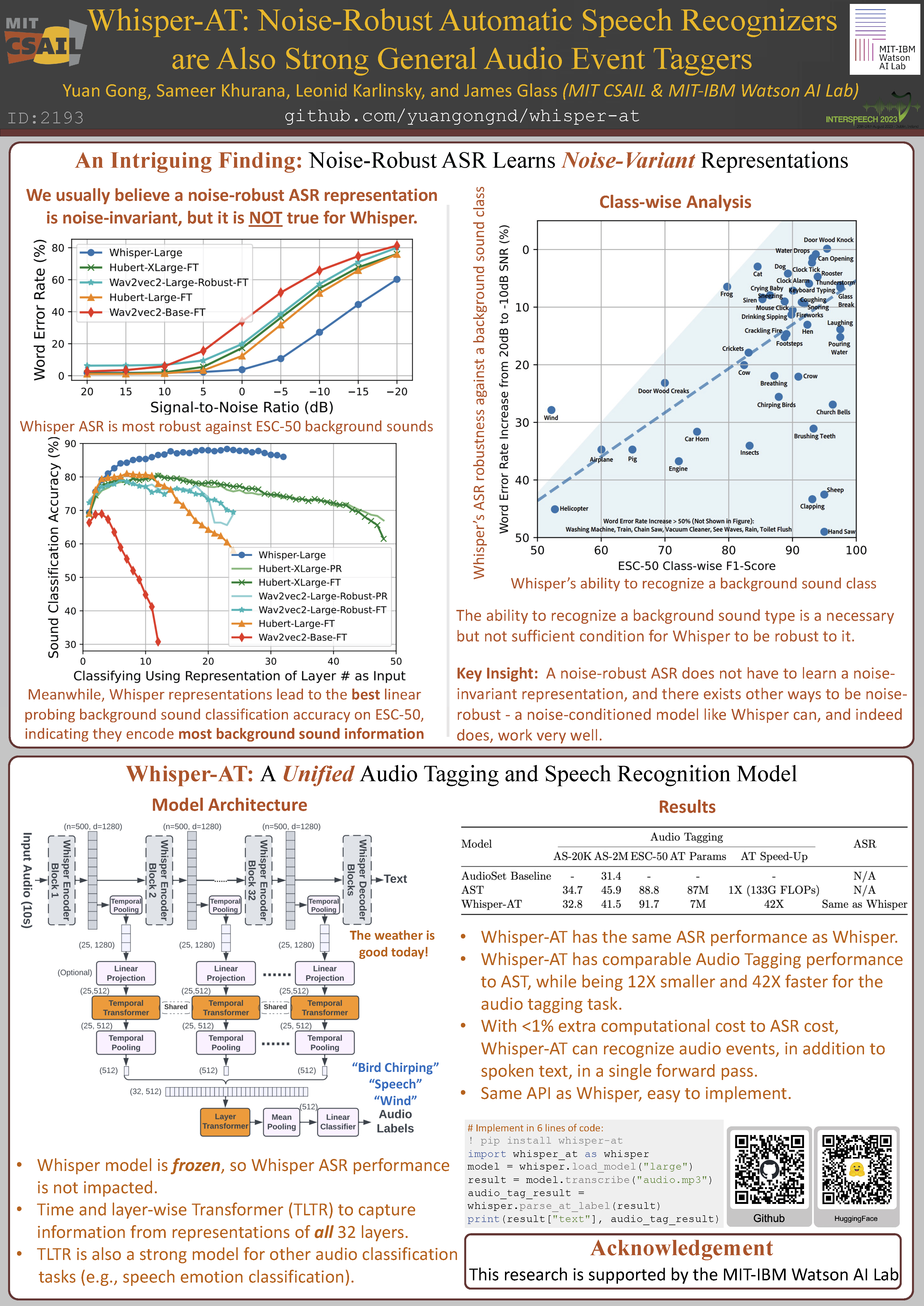
- First we report an interesting and surprising finding that while Whisper is very robust against real-world background sounds (e.g., music), its audio representation is actually NOT noise-invariant, but is instead highly correlated to non-speech sounds, indicating that Whisper recognizes speech conditioned on the noise type.
- Second, with the above finding, we build a unified audio tagging and speech recognition model Whisper-AT by freezing the backbone of Whisper, and training a novel audio tagging model called Time and Layer-wise Transformer (TL-TR) on top of it. With <1% extra computational cost, Whisper-AT can recognize audio events, in addition to spoken text, in a single forward pass.
The most important finding of this paper is that a robust ASR actually learns a noise-variant representation; most previous work focuses on noise-invariant representations.
Since we freeze the Whisper model, in our experiments, we extract and save the Whisper features first.
There are two ways to extract Whisper features:
- You can use the released version of Whisper-AT and get the audio feature [at this line], by adding
result.audio_features_for_atto the returns oftranscribefunction. You can get the pooled (x20 temporal downsampling) audio representation of each Whisper audio encoder. E.g., for Whisper-Large,result.audio_features_for_atis of shape [32, 75, 1280], where 32 is the number of Whisper encoder layer, 75 is the time length (30s * 100 = 3000 frames / 2 (Whisper downsample) / 20 (AT downsample) = 75). Note the Whisper window is always 30s. So if your input audio is 10s, you need to slice the first 25 time steps. i.e., [32, 25, 1280]. In addition, with the padded zeros and attention mechanism, the output won't be same as just inputting 10s audio without padding.- Advantage: polished code.
- Disadvantage: always padded to 30s (which is acceptable), not used in our paper experiments.
- We also provide our actual code to extract feature at [here]. This code is researchy, but trims the audio to 10s instead of padding.
- We don't have time to polish this, use if you are an expert on Whisper.
To facilitate reproduction, we release the ESC-50 features used for experiments [here].
This part of code is [here] and [here].
- We first add ESC-50 noises to a small subset of Librispeech. Specifically, 40 clean Librispeech clean samples are used, and we add each of the 50 class ESC-50 sounds (each ESC-50 class also has 40 samples) to each of the clean sample (40*50=2000 samples for each SNR). We tested SNR from -20dB to 20dB.
- We then transcribe these noise speech samples using various ASR model and report WER.
This part of code is [here] and [here].
- We first extract representation of various ASR models of all layers and pool over the time dimension.
- We then add a linear layer on top of the representations and report ESC-50 sound event classification accuracy. Note: no speech is mixed in this experiment.
This part of code is [here].
We use the same noise augmentation and ESC-50 sound classification methods as above. But now to class-wise analysis. Note for each noise class, the test speech samples are same, which makes a fair comparison.
This part of code is [here].
We save all features to disk and train TL-TR on top of it. This saves GPU usage but adds i/o cost. Please see 1.1 for how to extract feature. No matter which method you use, the representation must be in shape of [num_layer, 25, representation_dim], e.g., [32, 25, 1280] for Whisper-Large.
The model code is [here].
The Whisper-AT training recipe is here. This contains everything needed to train Whisper-AT except the data.
The starting point is run_as_full_train.sh, which calls run.sh, which then calls traintest.py.
Hyper-parameters are:
| Model | Initial LR | Train Epochs (Equivalent**) | Weight Averaging |
|---|---|---|---|
| large | 5e-5 | 30 (3) | 16-30 |
| large (low proj) | 1e-4 | 30 (3) | 16-30 |
| medium | 5e-5 | 30 (3) | 16-30 |
| medium (low proj) | 1e-4 | 30 (3) | 16-30 |
| small | 1e-4 | 50 (5) | 21-50 |
| small (low proj) | 1e-4 | 50 (5) | 21-50 |
| base | 1e-4 | 50 (5) | 21-50 |
| tiny | 1e-4 | 50 (5) | 21-50 |
** We stop each epoch when 10% iteration is done. So the equivalent epochs = 0.1 * epochs.
Training logs are also released [here].
The model code is [here].
The Whisper-AT script downloads the original OpenAI Whisper model and our AT model automatically. So you do not really need to download it manually. But in case your device does not have Internet access, here is the [links]
| Model Name |
#ASR Params |
Language | #AT Params (TL-TR) |
AS mAP (TL-TR) |
#AT Params (TL-TR-512) |
AS mAP (TL-TR-512) |
|---|---|---|---|---|---|---|
large-v2 ( large) |
1550M | Multilingual | 40.0M | 41.7 | 7.2M | 40.3 |
large-v1 |
1550M | Multilingual | 40.0M | 42.1 | 7.2M | 41.6 |
medium.en |
769M | English | 25.8M | 41.4 | 7.1M | 41.1 |
medium |
769M | Multilingual | 25.8M | 40.8 | 7.1M | 41.2 |
small.en |
244M | English | 14.6M | 40.1 | 6.9M | 39.9 |
small |
244M | Multilingual | 14.6M | 39.8 | 6.9M | 39.8 |
base.en |
74M | English | 6.6M | 37.5 | - | - |
base |
74M | Multilingual | 6.6M | 37.6 | - | - |
tiny.en |
39M | English | 3.8M | 35.8 | - | - |
tiny |
39M | Multilingual | 3.8M | 36.5 | - | - |
- Abbreviations:
#ASR Params= Model parameters for the automatic speech recognition task.#AT Params= Model parameters for audio tagging.TL-TR= The proposed time and layer-wise Transformer model, the dimension follows the Whisper model, e.g., 1280 forwhisper-large.TL-TR-512= The proposed low-computational time and layer-wise Transformer model, the dimension is projected to 512, not available forbaseandsmallmodels that have lower dimensions than 512.AS mAP= The audio tagging mean average precision (mAP) on the AudioSet evaluation set.
- Whisper-AT supports all Whisper models. The script downloads the original OpenAI Whisper model and our AT model automatically.
- All results reported in the paper are based on
large-v1,medium.en,small.en,base.en, andtiny.en.large-v2and multi-lingual models are trained after the paper is finished.
Whisper-AT's code and model weights are released under a BSD license, which is similar with the original OpenAI Whisper's MIT license. Commercial use is welcome.
If you have a question, please create a Github issue (preferred) or send me an email yuangong@mit.edu.