从spark 2.3版本开始,我们可以在Kubernetes上运行和管理Spark资源。在此之前,只能在Hadoop Yarn、Apache Mesos或独立集群上运行Spark。在Kubernetes上运行Spark应用有以下优点:
-
通过把Spark应用和依赖项打包成容器,享受容器的各种优点,很容易的解决Hadoop版本不匹配和兼容性问题。还可以给容器镜像打上标签控制版本,这样如果需要测试不同版本的Spark或者依赖项的话,选择对应的版本做到了。
-
重用Kubernetes生态的各种组件,比如监控、日志。把Spark工作负载部署在已有的的Kubernetes基础设施中,能够快速开始工作,大大减少了运维成本。
-
支持多租户,可利用Kubernetes的namespace和ResourceQuota做用户粒度的资源调度,利用Kubernetes的节点选择机制保证Spark工作负载得到专用的资源。另外,由于driver pods创建executor pods,我们可以用Kubernetes service account控制权限,利用Role或者Cluster Role定义细粒度访问权限,安全的运行工作负载,避免受其他工作负载影响。
-
把Spark和管理数据生命周期的应用运行在同一个集群中,可以使用单个编排机制构建端到端生命周期的解决方案,并能很容易的复制到其他区域部署,甚至是在私有化环境部署。
阿里云容器服务Kubernetes版(简称 ACK)提供高性能可伸缩的容器应用管理能力,支持企业级容器化应用的全生命周期管理。整合阿里云虚拟化、存储、网络和安全能力,打造云端最佳容器化应用运行环境,我们将介绍在在ACK上运行Spark工作负载的最佳实践和benchmark结果。
Spark on Kubernetes Operator帮助用户在Kubernetes上像其他工作负载一样用通用的方式运行Spark Application,它使用Kubernetes custom resources来配置、运行Spark Application,并展现其状态,需要Spark 2.3及以上的版本来支持Kubernetes调度。
TPC-DS由第三方社区创建和维护,是事实上的做性能压测,协助确定解决方案的工业标准。这个测试集包含对大数据集的统计、报表生成、联机查询、数据挖掘等复杂应用,测试用的数据和值是有倾斜的,与真实数据一致。可以说TPC-DS是与真实场景非常接近的一个测试集,也是难度较大的一个测试集。
TPC-DS包含104个query,覆盖了SQL 2003的大部分标准,有99条压测query,其中的4条query各有2个变体(14,23,24,39),最后还有一个“s_max”query进行全量扫描和最大的一些表的聚合。
这个基准测试有以下几个主要特点:
- 遵循SQL 2003的语法标准,SQL案例比较复杂;
- 分析的数据量大,并且测试案例是在回答真实的商业问题;
- 测试案例中包含各种业务模型(如分析报告型,迭代式的联机分析型,数据挖掘型等);
- 几乎所有的测试案例都有很高的IO负载和CPU计算需求。
这里我们采用TPC-DS来评测Spark在ACK上的性能。
我们从在ACK上搭建环境,并运行社区版Spark和分布式缓存框架Alluxio开始,介绍如何在ACK运行Spark工作负载,详情请参考快速开始。
为了提高在Kubernetes运行工作负载时的性能和易用性,并降低成本,阿里云EMR和ACK团队做了很多优化工作,主要有以下这些:
| 集群配置 | 参数 |
|---|---|
| 集群类型 | ACK标准集群 |
| 集群版本 | 1.16.9-aliyun.1 |
| ECS实例 | ECS规格:ecs.d1ne.6xlarge 操作系统:CentOS 7.7 64位 CPU:24核 内存:96G 数据盘:5500GB HDDx12 |
| Worker Node个数 | 20 |
-
Apache Spark vs EMR Spark
测试数据:10TB
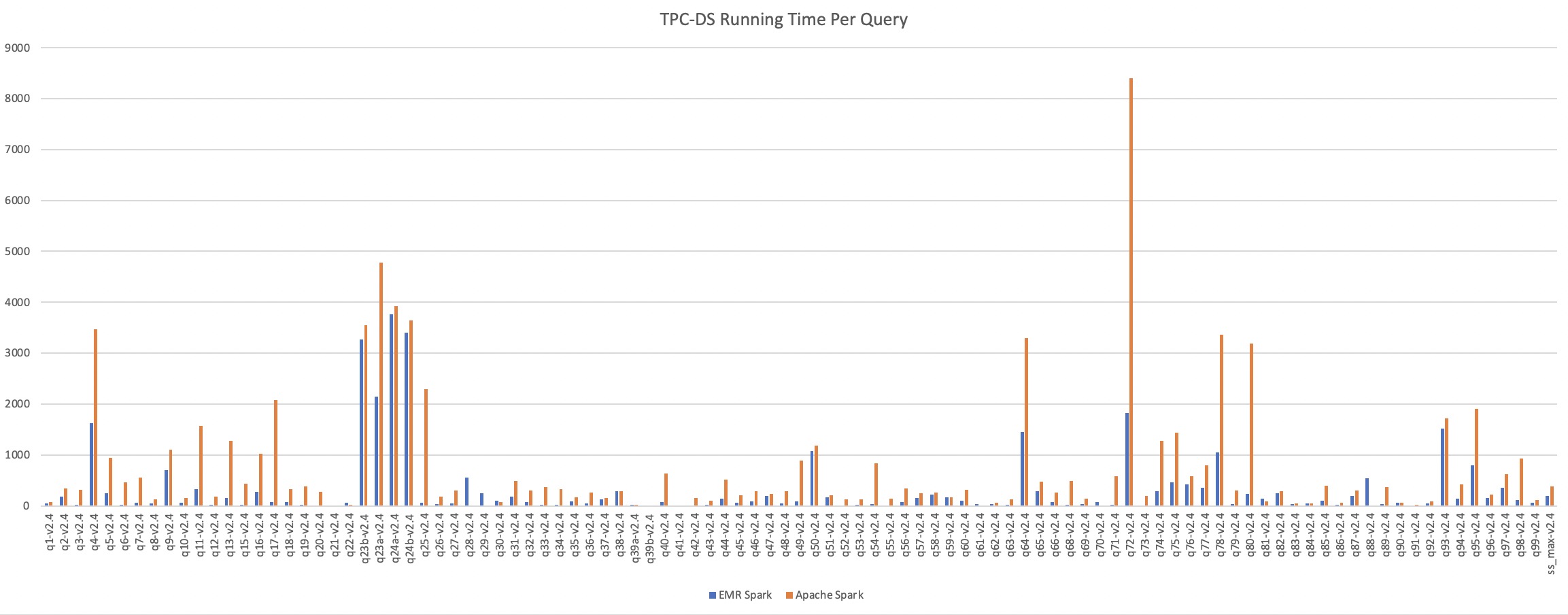
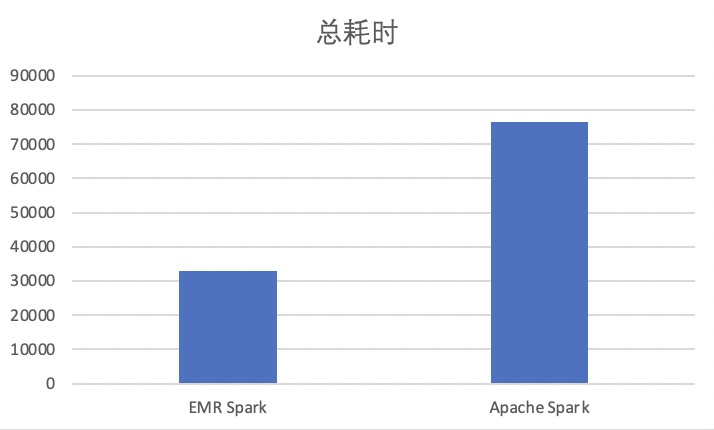
在10TB数据上测试,EMR Spark相比社区版Apache Spark约有57%的性能提升,详细测试过程参考使用EMR Spark运行Spark工作负载。
-
EMR Spark vs EMR Spark + Remote Shuffle Service
测试数据:10TB
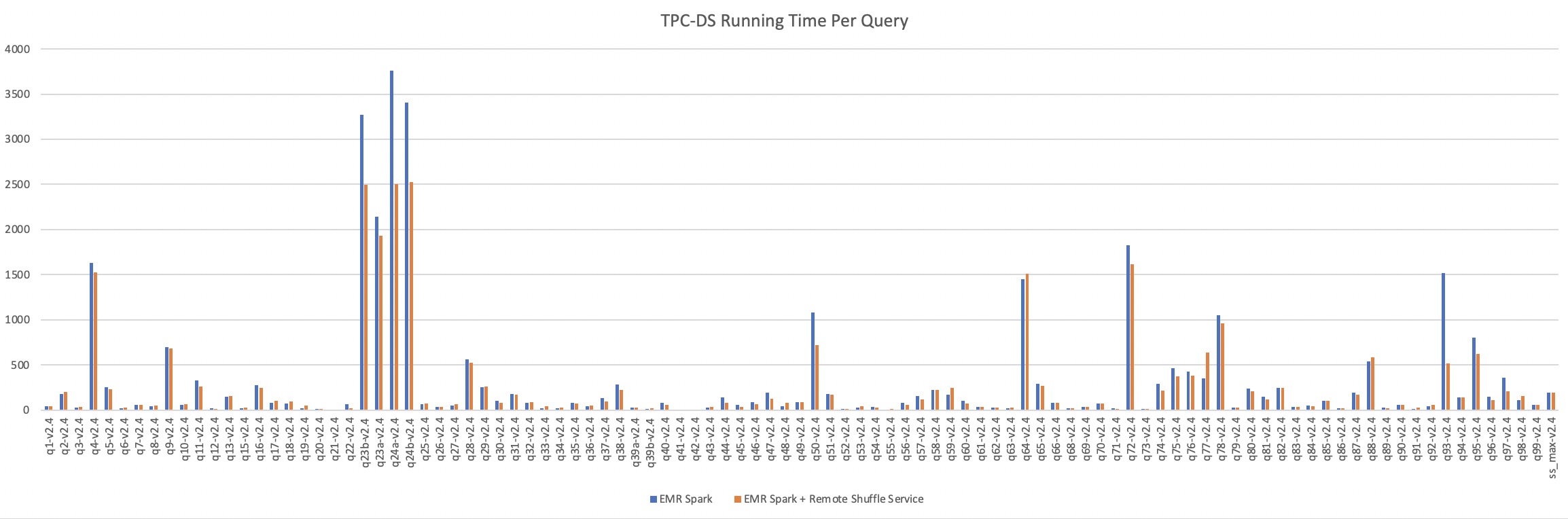
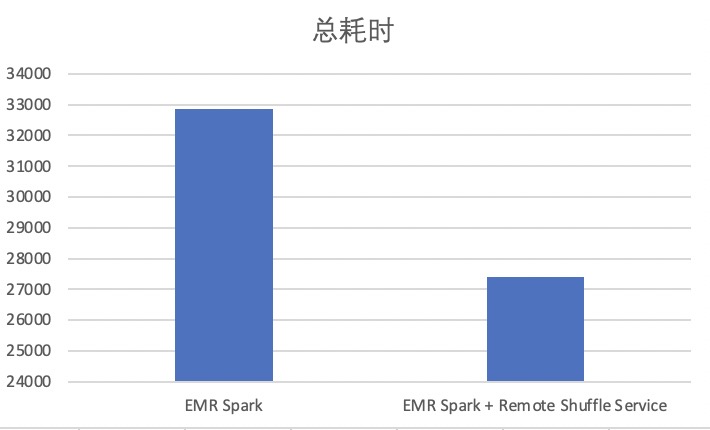
在10TB数据上,增加Shuffle Service后,相比直接使用EMR Spark,约有16%的性能提升。详细测试过程请参考使用EMR Spark + Remote Shuffle Service运行Spark工作负载。
-
EMR Spark vs EMR Spark + JindoFS
测试数据:1TB
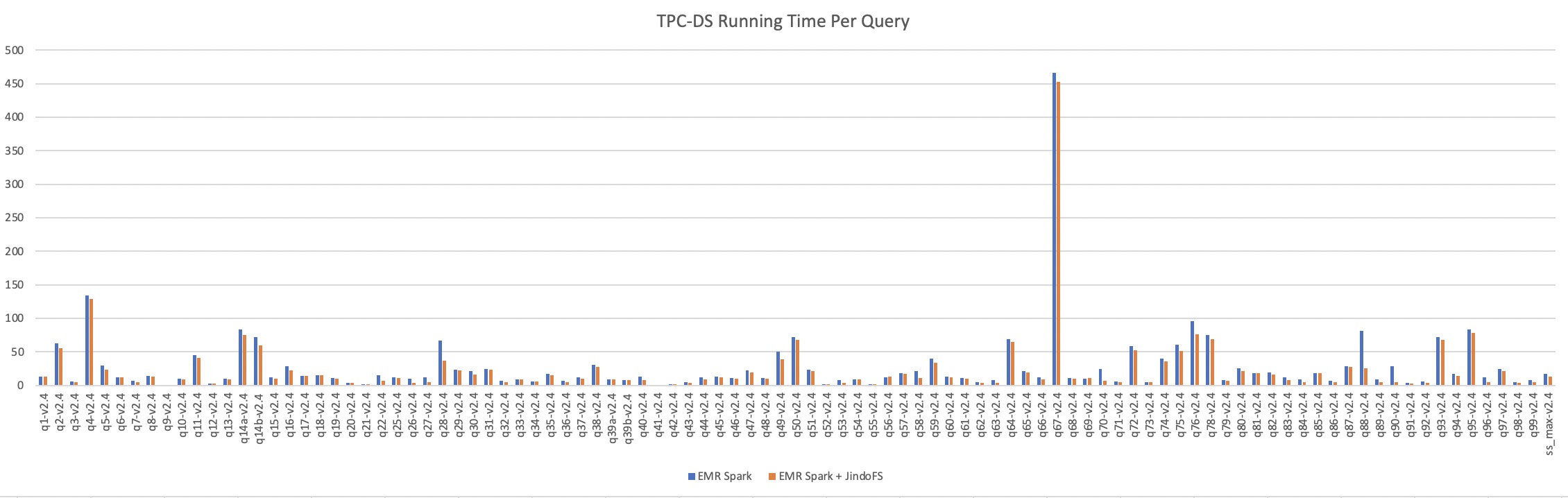
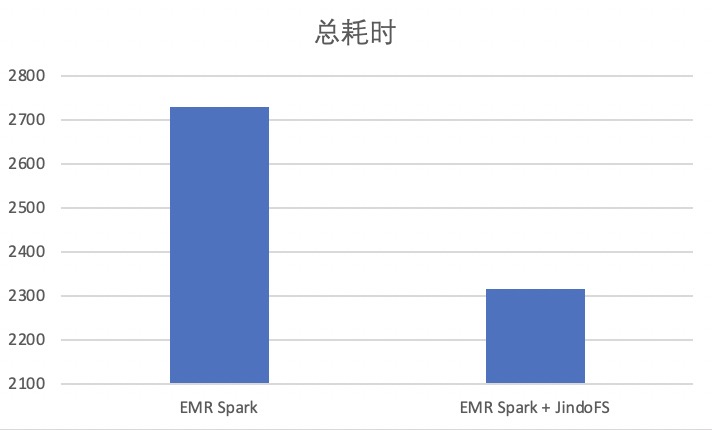
在1TB数据上,使用JindoFS做数据分布式缓存后,相比直接使用EMR Spark,得到约15%性能提升。详细测试过程请参考使用EMR Spark + JindoFS运行Spark工作负载。






- 使用EMR Spark运行Spark工作负载
- 使用EMR Spark + Remote Shuffle Service运行Spark工作负载
- 使用EMR Spark + JindoFS运行Spark工作负载
- 使用EMR Spark + JindoFS + Remote Shuffle Service运行Spark工作负载
本项目参考了eks-spark-benchmark,感谢其优秀的工作。