查看完整文档: https://zhuanlan.zhihu.com/p/34585912
基于知识图谱的自动问答(Question Answering over Knowledge Base, 即 KBQA)问题的大概形式是,预先给定一个知识库(比如Freebase),知识库中包含着大量的先验知识数据,然后利用这些知识资源自动回答自然语言形态的问题(比如“肉夹馍是哪里的美食”,“虵今年多大了”等人民群众喜闻乐见的问题)。
假设要回答“Where was Leslie Cheung born”这个问题,主要分四步:
- 实体识别(Named Entity Recognition),即把问题中的主要实体的名字从问题中抽出来,这样才知道应该去知识库中搜取哪个实体的信息来解决问题,即图中把“Leslie Cheung”这个人名抽出来;
- 实体链接(Entity Linking),把抽取出来的实体名和知识库中具体的实体对应起来,做这一步是因为,由于同名实体的存在,名字不是实体的唯一标识,实体独一无二的编号(id)才是,找到了实体名没卵用,必须要对应到知识库中具体的实体id,才能在知识库中把具体实体找到,获取相关信息。即图中将“Leslie Cheung”映射到“m.sdjk1s”这个 id 上(Freebase 的实体 id 是这个格式的)。这一步会存在一些问题,比如直接搜“姓名”叫“Leslie Cheung”的实体是搜不到的,因为“Leslie Cheung”其实是某个实体的“外文名”,他的“姓名”叫“张国荣”,以及有时候还会有多个叫“Leslie Cheung”的人。具体解决方式后面再说。
- 关系预测(Relation Prediction),根据原问句中除去实体名以外的其他词语预测出应该从知识库中哪个关系去解答这个问题,是整个问题中最主要的一步。即图中从“Where was born”预测出“people.person.place_of_birth”(Freebase 的关系名格式,翻译过来就是“出生地”)这个关系应该连接着问题的主要实体“Leslie Cheung”与这个问题的答案。 找到了实体与关系,直接在知识库中把对应的三元组检索出来,即 “<m.sdjk1s, people.person.place_of_birth, m.s1kjds>”,那么这条三元组的尾实体,即“m.s1kjds”就是问题的答案,查询其名字,就是“Hong Kong”。
SimpleQuestions & WebQuestions 学术界问答领域比较喜闻乐见的两个数据集了,相当权威
另外,知识库用的是 Freebase ,业界最权威的知识库之一了
Pytorch
word2vec (WikiAnswers 数据预训练) 模型下载:https://pan.baidu.com/s/1DNlPPqeYnkPldmJLnyAiwA
从 tensorflow 转过来发现,pytorch 真好用
问答问题目前的解决方法,框架基本都是上面说那四步,但是具体做法五花八门,模型各式各样,文中所用的 seq2seq 也只是一个简单实践,效果上比较如下图(out-of-state now 是业界目前最好结果,APVA-TURBO 是我最近在做的一篇论文)
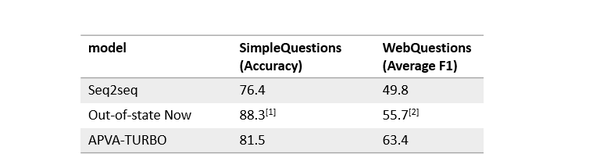
简单的 seq2seq 效果还不错,虽然跟学术界目前最好成绩有很大差距,但是还不错。后来我又加入了一些比如 KB embedding,turbo training 等一言难尽的补丁上去,变成现在的 APVA-TURBO 模型,在 WebQuestions 上已经快领先 8 个点了,但是文章里不提了,太乱了,直接发一个论文链接,感兴趣的可以深入研究
无关的吐槽发泄一下:论文在半个月前投 ACL2018 的,然后因为段落的格式问题被拒了(是的,因为格式问题,WTF???),快毕业了 A 没有了太遗憾了,现在准备这星期投 COLING 2018,都是命啊
还是想说,pytorch 真好用啊真好用