
Given the embedding of the search query we can efficent get the top matching k results form DB with 20M document.The objective of this project is to design and implement an indexing system for a semantic search database.

Check Final Notebook
https://github.com/ZiadSheriif/IntelliQuery/blob/main/Evaluate_ADB_Project.ipynb
Clone Repo
git clone https://github.com/ZiadSheriif/IntelliQuery.git
Install dependencies
pip install -r requirements.txt
Run Indexer
$ python ./src/evaluation.py

This is out final Approach with Some Enhancements
- Changed MiniBatchKMeans to regular KMeans
- We calculate initial centroids with just the first chunk of data
- Introduced parallel processing for different regions
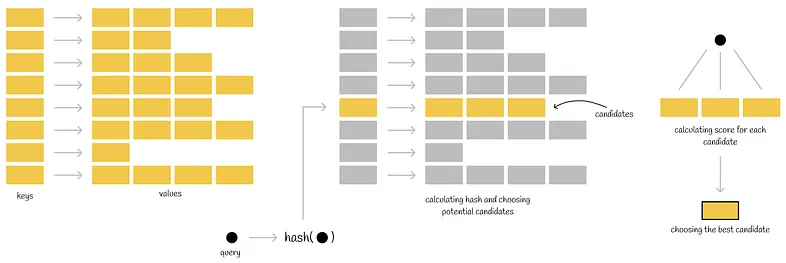
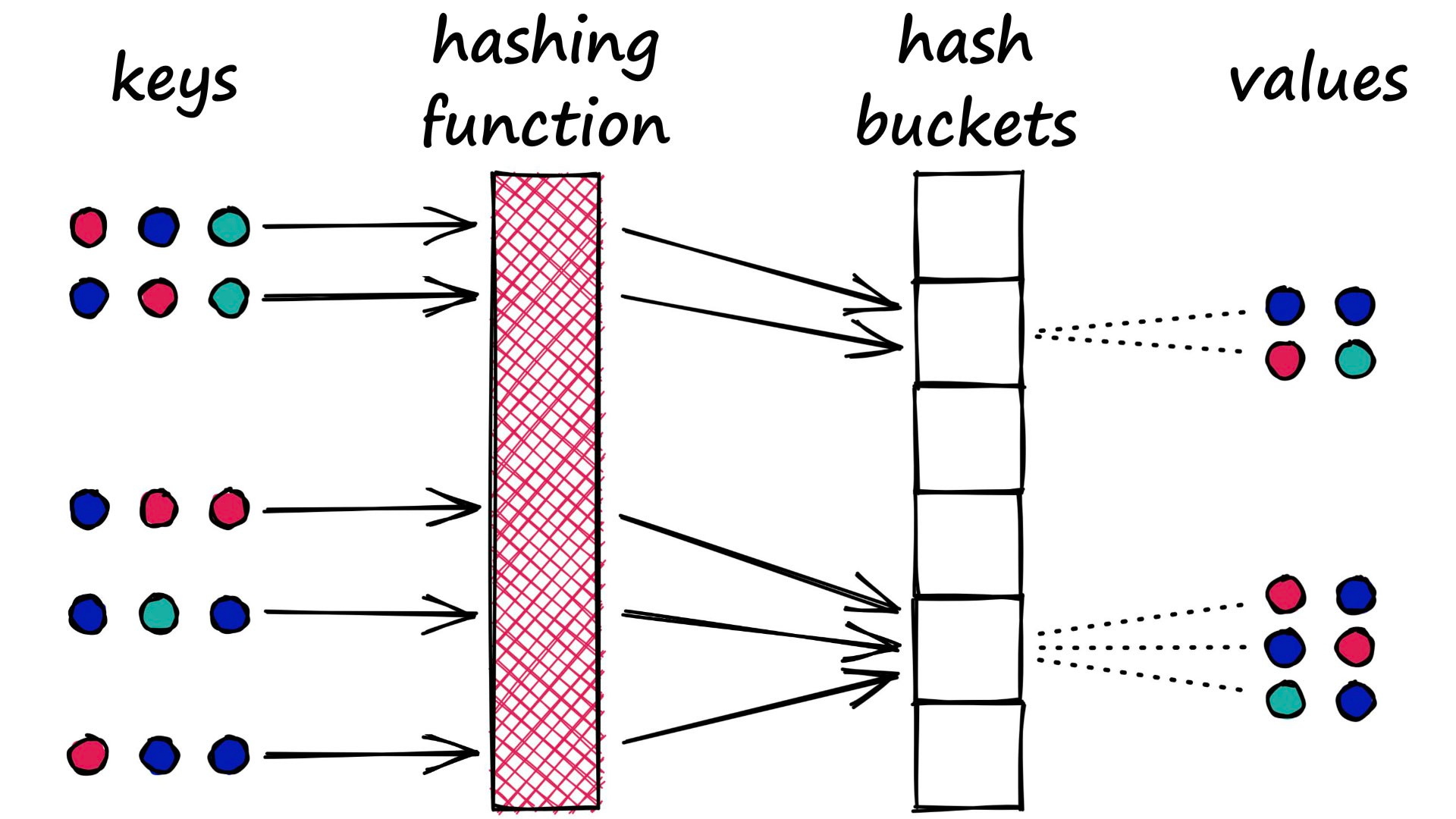
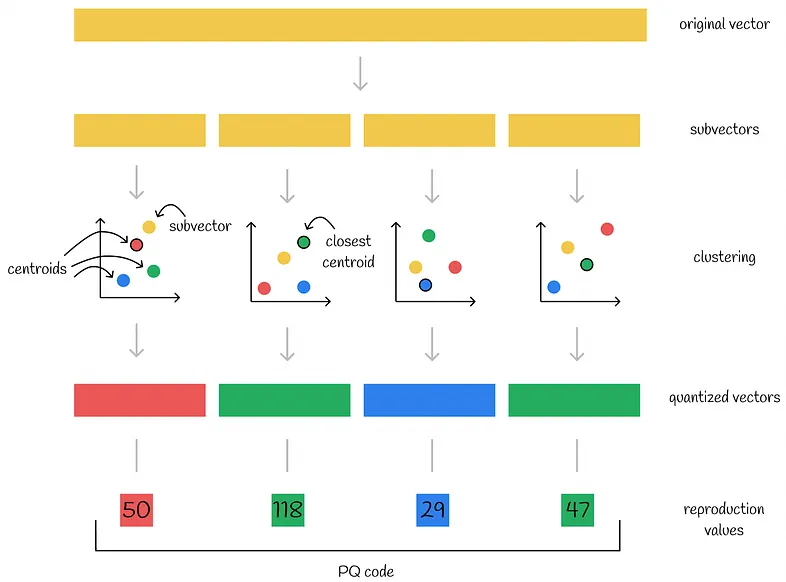
It Combines both LSH & PQ
 Ziad Sherif |
 Zeyad Tarek |
 Abdalhameed Emad |
 Basma Elhoseny |
This software is licensed under MIT License, See License for more information ©Ziad Sherif.