Still under constructing
It's my first time to get Kaggle silver medal. So excited. At now I prepare to put together some gold medal solution and my solution.
-
Data Extration:
- Concatenate with prompt, question and options to form the text.
- Organize and categorize the corpus into three types: the complete text (15GB), STEM text snippeta and STEM text snippet 2.
-
Embedding:
- We use the embedding model 'gte-base' to generate embeddings for query and 3 types of corpus.
-
Index Creation:
- We use the FAISS library to create the index for the corpus.
-
Retrieval:
- Conduct semantic similarity search using Inner Product Similarity.
- Query the embeddings in the three types of corpus indexs individually, obtaining the top 10 text as the retrieval results.
-
Generation:
- We use the retrieval results (base on the full text) as the training set's external knowledge. Then form complete samples from context (knowledge base) + prompt + question + options.
-
Fine-Tuning:
- Input the complete samples into the 'deberta-v3-large' model for five-category classification training, adapting for RAG and stylistic behavioral vocabulary based on the following format.
- format: External knowledge text {context}, please answer the question {question prompt}, which one is the most correct in options {option [1-5]} ABCDE?
-
Inference (Answer Prediction):
- Input the retrieved texts from the three corpus knowledge bases into the fine-tuned 'deberta-v3-large' model to predict the probabilities for each option.
- Calculate the weighted average of the prediction results to obtain the final top three answer options. (Actually for STEM sinpped 2, We got a worse performance, When we deleted the STEM sinpped 2(seting weight is 0), we got better performance. We guess the reason is the data bias, addtionally we found for Pre-training model, Quantity of Data Over Quality of Data. It's different for MLLM's alignment.)
There are some key points from their team:
- RAG on Wikipedia chunks(2.4TB)
- e5 worked best. (Actually they tried top-20 model list on MTEB Leaderboard MTEB )
- Custom pytorch cosine similarity code, no need for FAISS.
- Using five chunks as context was best for us with 1k max_length
- Mostly ensemble of 7B LLMs, one 13B is also in, but larger ones were not useful. (Deberta is not necessary, LLM + Context is better)
- Ensemble of different wiki/chunking/embedding techniques with late fusion (i.e. each llm gets a different technique)
- All LLMs fine-tuned with H2O LLM Studio with binary classification head.
In fact, many article have proved that Demonstrations's role in LLM. Usually it's make LLM higher performance on most of NLP tasks. After they tried top-20 list on MTEB Lead, their submission has contexts from e5-base-v2,e5-large-v2,gte-base,gte-large and bge-large models.
For Wikipedia, they mostly encode the tittle and Wikipedia chunks. They use two variations for the question.
- Simple concatentaion: "{prompt}{A},{B},{C},{D},{E}"
- Search contexts individually for each "{prompt}{A}","{prompt}{B}","{prompt}{C}","{prompt}{D}","{prompt}{E}", and sort them by similarity.
For a pretty quick and scalable similarity search on GPUs.They split the whole 60M
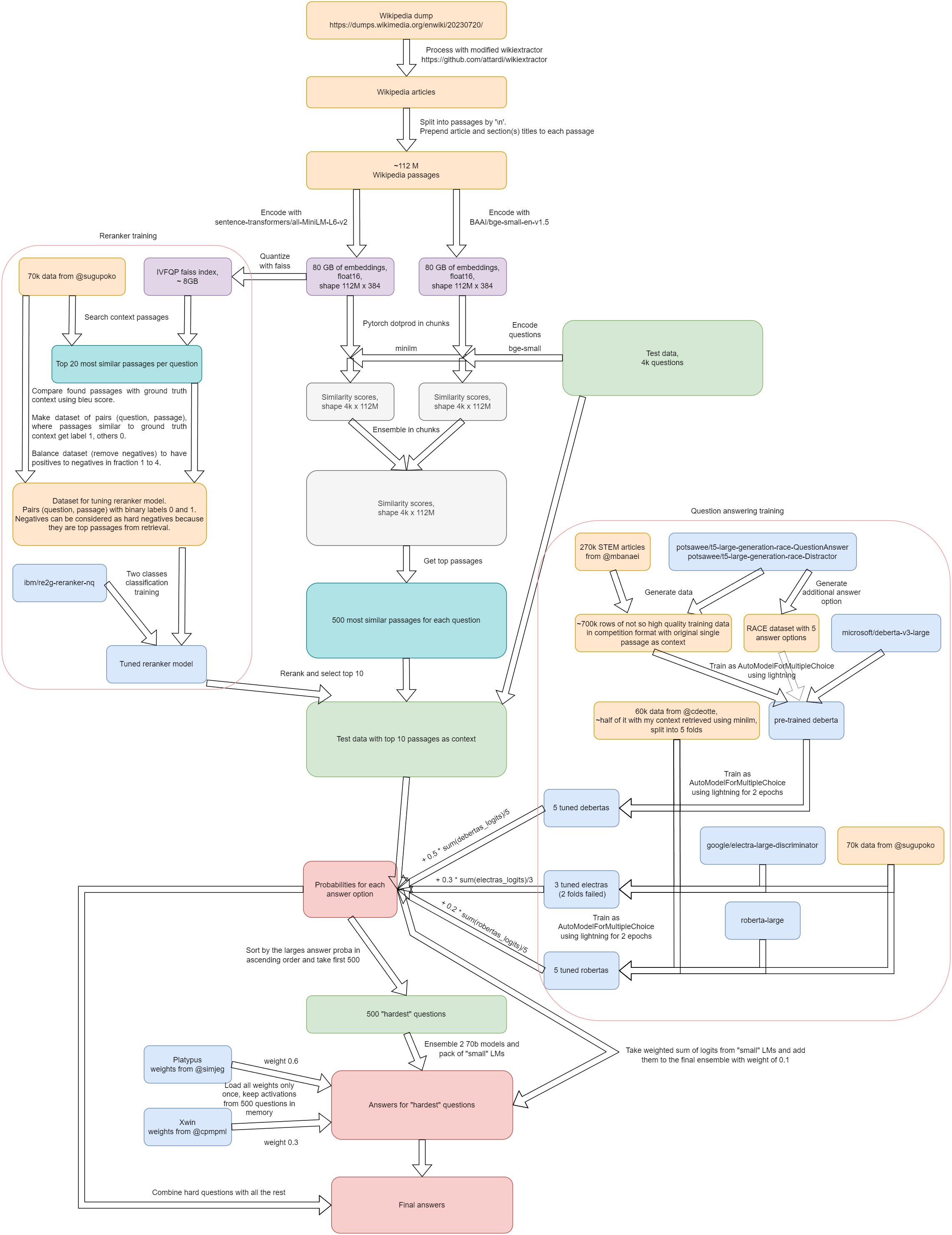
Similar With mine.