Uniffle is a unified remote shuffle service for distributed compute engines. It provides the ability to aggregate and store shuffle data on remote servers, thus improving the performance and reliability of large jobs. Currently it supports Apache Spark and Apache Hadoop MapReduce.
![]()


 Uniffle cluster consists of three components, a coordinator cluster, a shuffle server cluster and an optional remote storage (e.g., HDFS).
Uniffle cluster consists of three components, a coordinator cluster, a shuffle server cluster and an optional remote storage (e.g., HDFS).
Coordinator will collect the status of shuffle servers and assign jobs based on some strategy.
Shuffle server will receive the shuffle data, merge them and write to storage.
Depending on different situations, Uniffle supports Memory & Local, Memory & Remote Storage(e.g., HDFS), Memory & Local & Remote Storage(recommendation for production environment).
-
Spark driver ask coordinator to get shuffle server for shuffle process
-
Spark task write shuffle data to shuffle server with following step:
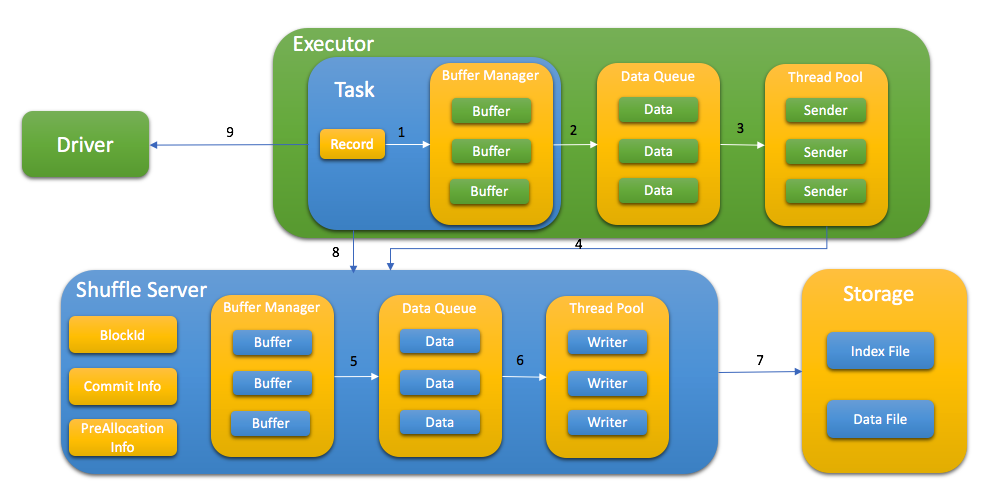
- Send KV data to buffer
- Flush buffer to queue when buffer is full or buffer manager is full
- Thread pool get data from queue
- Request memory from shuffle server first and send the shuffle data
- Shuffle server cache data in memory first and flush to queue when buffer manager is full
- Thread pool get data from queue
- Write data to storage with index file and data file
- After write data, task report all blockId to shuffle server, this step is used for data validation later
- Store taskAttemptId in MapStatus to support Spark speculation
-
Depending on different storage types, the spark task will read shuffle data from shuffle server or remote storage or both of them.

The shuffle data is stored with index file and data file. Data file has all blocks for a specific partition and the index file has metadata for every block.

Currently supports Spark 2.3.x, Spark 2.4.x, Spark 3.0.x, Spark 3.1.x, Spark 3.2.x
Note: To support dynamic allocation, the patch(which is included in client-spark/patch folder) should be applied to Spark
Currently supports the MapReduce framework of Hadoop 2.8.5
note: currently Uniffle requires JDK 1.8 to build, adding later JDK support is on our roadmap.
Uniffle is built using Apache Maven. To build it, run:
mvn -DskipTests clean package
Build against profile Spark 2 (2.4.6)
mvn -DskipTests clean package -Pspark2
Build against profile Spark 3 (3.1.2)
mvn -DskipTests clean package -Pspark3
Build against Spark 3.2.x, Except 3.2.0
mvn -DskipTests clean package -Pspark3.2
Build against Spark 3.2.0
mvn -DskipTests clean package -Pspark3.2.0
To package the Uniffle, run:
./build_distribution.sh
Package against Spark 3.2.x, Except 3.2.0, run:
./build_distribution.sh --spark3-profile 'spark3.2'
Package against Spark 3.2.0, run:
./build_distribution.sh --spark3-profile 'spark3.2.0'
rss-xxx.tgz will be generated for deployment
- unzip package to RSS_HOME
- update RSS_HOME/bin/rss-env.sh, e.g.,
JAVA_HOME=<java_home> HADOOP_HOME=<hadoop home> XMX_SIZE="16g" - update RSS_HOME/conf/coordinator.conf, e.g.,
rss.rpc.server.port 19999 rss.jetty.http.port 19998 rss.coordinator.server.heartbeat.timeout 30000 rss.coordinator.app.expired 60000 rss.coordinator.shuffle.nodes.max 5 # enable dynamicClientConf, and coordinator will be responsible for most of client conf rss.coordinator.dynamicClientConf.enabled true # config the path of client conf rss.coordinator.dynamicClientConf.path <RSS_HOME>/conf/dynamic_client.conf # config the path of excluded shuffle server rss.coordinator.exclude.nodes.file.path <RSS_HOME>/conf/exclude_nodes - update <RSS_HOME>/conf/dynamic_client.conf, rss client will get default conf from coordinator e.g.,
# MEMORY_LOCALFILE_HDFS is recommended for production environment rss.storage.type MEMORY_LOCALFILE_HDFS # multiple remote storages are supported, and client will get assignment from coordinator rss.coordinator.remote.storage.path hdfs://cluster1/path,hdfs://cluster2/path rss.writer.require.memory.retryMax 1200 rss.client.retry.max 100 rss.writer.send.check.timeout 600000 rss.client.read.buffer.size 14m - start Coordinator
bash RSS_HOME/bin/start-coordnator.sh
- unzip package to RSS_HOME
- update RSS_HOME/bin/rss-env.sh, e.g.,
JAVA_HOME=<java_home> HADOOP_HOME=<hadoop home> XMX_SIZE="80g" - update RSS_HOME/conf/server.conf, e.g.,
rss.rpc.server.port 19999 rss.jetty.http.port 19998 rss.rpc.executor.size 2000 # it should be configured the same as in coordinator rss.storage.type MEMORY_LOCALFILE_HDFS rss.coordinator.quorum <coordinatorIp1>:19999,<coordinatorIp2>:19999 # local storage path for shuffle server rss.storage.basePath /data1/rssdata,/data2/rssdata.... # it's better to config thread num according to local disk num rss.server.flush.thread.alive 5 rss.server.flush.threadPool.size 10 rss.server.buffer.capacity 40g rss.server.read.buffer.capacity 20g rss.server.heartbeat.timeout 60000 rss.server.heartbeat.interval 10000 rss.rpc.message.max.size 1073741824 rss.server.preAllocation.expired 120000 rss.server.commit.timeout 600000 rss.server.app.expired.withoutHeartbeat 120000 # note: the default value of rss.server.flush.cold.storage.threshold.size is 64m # there will be no data written to DFS if set it as 100g even rss.storage.type=MEMORY_LOCALFILE_HDFS # please set a proper value if DFS is used, e.g., 64m, 128m. rss.server.flush.cold.storage.threshold.size 100g - start Shuffle Server
bash RSS_HOME/bin/start-shuffle-server.sh
-
Add client jar to Spark classpath, e.g., SPARK_HOME/jars/
The jar for Spark2 is located in <RSS_HOME>/jars/client/spark2/rss-client-XXXXX-shaded.jar
The jar for Spark3 is located in <RSS_HOME>/jars/client/spark3/rss-client-XXXXX-shaded.jar
-
Update Spark conf to enable Uniffle, e.g.,
spark.shuffle.manager org.apache.spark.shuffle.RssShuffleManager spark.rss.coordinator.quorum <coordinatorIp1>:19999,<coordinatorIp2>:19999 # Note: For Spark2, spark.sql.adaptive.enabled should be false because Spark2 doesn't support AQE.
To support spark dynamic allocation with Uniffle, spark code should be updated. There are 3 patches for spark (2.4.6/3.1.2/3.2.1) in spark-patches folder for reference.
After apply the patch and rebuild spark, add following configuration in spark conf to enable dynamic allocation:
spark.shuffle.service.enabled false
spark.dynamicAllocation.enabled true
- Add client jar to the classpath of each NodeManager, e.g., /share/hadoop/mapreduce/
The jar for MapReduce is located in <RSS_HOME>/jars/client/mr/rss-client-mr-XXXXX-shaded.jar
-
Update MapReduce conf to enable Uniffle, e.g.,
-Dmapreduce.rss.coordinator.quorum=<coordinatorIp1>:19999,<coordinatorIp2>:19999 -Dyarn.app.mapreduce.am.command-opts=org.apache.hadoop.mapreduce.v2.app.RssMRAppMaster -Dmapreduce.job.map.output.collector.class=org.apache.hadoop.mapred.RssMapOutputCollector -Dmapreduce.job.reduce.shuffle.consumer.plugin.class=org.apache.hadoop.mapreduce.task.reduce.RssShuffle
Note that the RssMRAppMaster will automatically disable slow start (i.e., mapreduce.job.reduce.slowstart.completedmaps=1)
and job recovery (i.e., yarn.app.mapreduce.am.job.recovery.enable=false)
We have provided an operator for deploying uniffle in kubernetes environments.
For details, see the following document:
The important configuration is listed as follows.
| Role | Link |
|---|---|
| coordinator | Uniffle Coordinator Guide |
| shuffle server | Uniffle Shuffle Server Guide |
| client | Uniffle Shuffle Client Guide |
The primary goals of the Uniffle Kerberos security are:
- to enable secure data access for coordinator/shuffle-servers, like dynamic conf/exclude-node files stored in secured dfs cluster
- to write shuffle data to kerberos secured dfs cluster for shuffle-servers.
The following security configurations are introduced.
| Property Name | Default | Description |
|---|---|---|
| rss.security.hadoop.kerberos.enable | false | Whether enable access secured hadoop cluster |
| rss.security.hadoop.kerberos.krb5-conf.file | - | The file path of krb5.conf. And only when rss.security.hadoop.kerberos.enable is enabled, the option will be valid |
| rss.security.hadoop.kerberos.keytab.file | - | The kerberos keytab file path. And only when rss.security.hadoop.kerberos.enable is enabled, the option will be valid |
| rss.security.hadoop.kerberos.principal | - | The kerberos keytab principal. And only when rss.security.hadoop.kerberos.enable is enabled, the option will be valid |
| rss.security.hadoop.kerberos.relogin.interval.sec | 60 | The kerberos authentication relogin interval. unit: sec |
- The proxy user mechanism is used to keep the data isolation in uniffle, which means the shuffle-data written by shuffle-servers is owned by spark app's user. To achieve the this, the login user specified by above config should be as the superuser for HDFS. For more details of related sections, please see Proxy user - Superusers Acting On Behalf Of Other Users
Uniffle is under the Apache License Version 2.0. See the LICENSE file for details.
For more information about contributing issues or pull requests, see Uniffle Contributing Guide.