GPT-vup
支持BiliBili和抖音直播,基于生产者-消费者设计,使用了openai嵌入、GPT3.5 api

- python 3. 8
- windows
- 确保有VPN 并开启全局代理
- 回答弹幕和SC
- 欢迎入场观众
- 感谢礼物
- 表情 动作响应
- 自定义任务
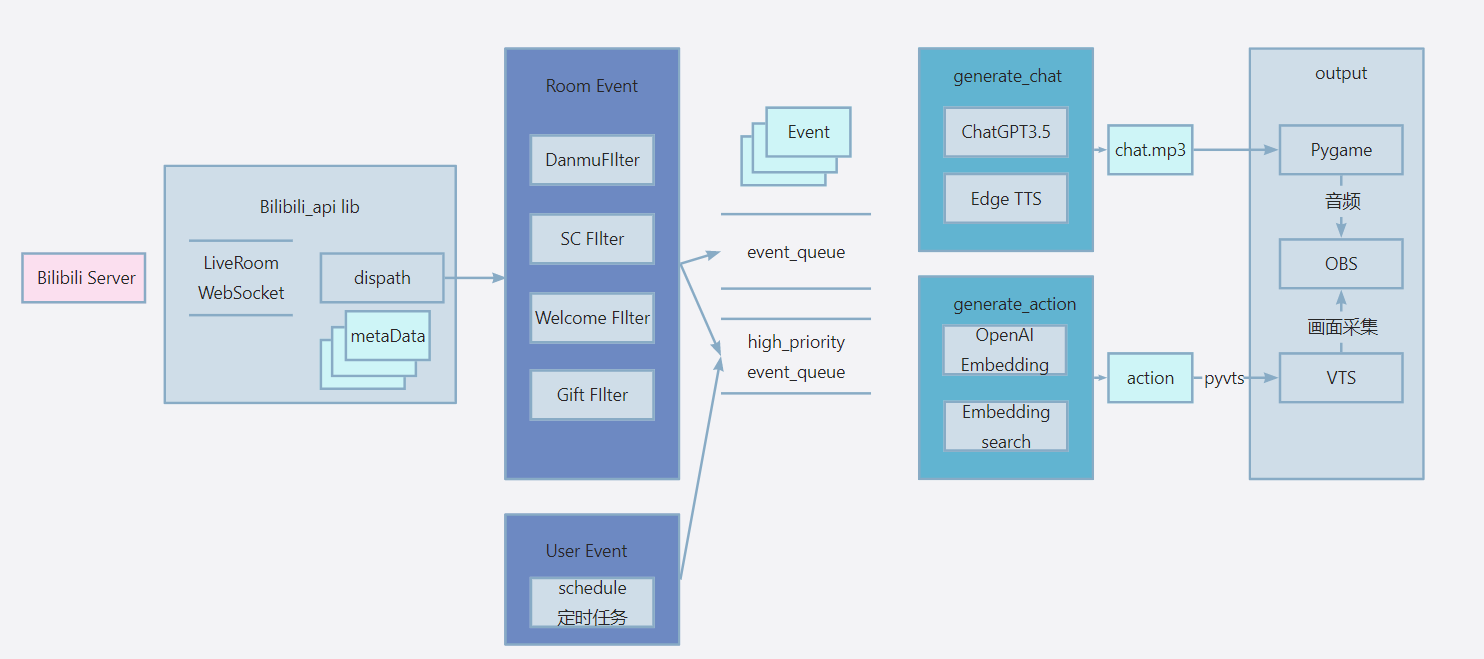
GPT-vup一共运行三个子线程:
生产者线程一:BiliBili Websocket
- 运行bilibili_api库,通过长连接websocket不断获取直播间的Event,分配到每个filter函数。
- filter函数干两件事,筛选哪些event入队,入哪个队列
- 线程消息队列有两个:
- 前提:生产者的生产速度远大于消费者
- event_queue:有最大长度,超过长度时挤掉最旧的消息,因此它是不可靠的,用来处理直播间的一般消息(普通弹幕、欢迎提示)
- hight...queue:不限长,处理直播间重要消息(sc、上舰)
生产者线程二:抖音 WebSocket
- 借助开源项目 抖音弹幕抓取数据推送: 基于系统代理抓包打造的抖音弹幕服务推送程序 在本地开一个转发端口
- 再运行一个线程监听这个端口即可,同样用filter过滤,入队
生产者线程三:
- 如果vup只有回应弹幕,我觉得有些单调了,因此可以通过schedule模块,每隔一段时间往high_priority_event_queue送一些自定义Event,比如我想让她每隔十分钟做一个自我介绍、表演节目。
消费者线程:
- worker类,有三个函数:generate_chat、generate_action、output去处理不同的Event
- 遵循依赖倒置原则,不管弹幕Event、sc Event都依赖抽象Event,而worker也依赖Event
说明:
- 消费者线程必须运行,生产者线程保证至少一个开启
git https://github.com/jiran214/GPT-vup.git
cd src
pip install -r .\requirements.txt
在src目录下创建配置文件config.ini(该项目所有配置信息都在这)
[openai]
api_key = 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
[room]
id=27661527
[edge-tss]
voice = zh-CN-XiaoyiNeural
rate = +10%
volume = +0%
[other]
debug = True
proxy = 127.0.0.1:7890说明:
-
room-id 为直播间房,比如我的是哔哩哔哩直播,二次元弹幕直播平台 (bilibili.com)最后一部分(没有房间号可以随便找一个作为测试)
-
edge-tss 语音相关配置
- 安装及使用教程网上有,只说明程序部分
- 打开VTS,开启VTS的API开关
- 运行
python ./actions,pyvts会请求vts api(注意:此时VTS会有确认弹窗),控制台会打印当前模型的所有动作 ps:会自动请求embedding,请忽略 - 配置VTS动作:将所有动作黏贴到actions.py 的live2D_actions列表。每次运行main 程序时,会获取所有live2D_action_emotions的向量。
live2D_actions = ['Heart Eyes', 'Eyes Cry', 'Angry Sign', 'Shock Sign', 'Remove Expressions', 'Anim Shake', 'Sad Shock']
live2D_action_emotions = ['Heart Eyes', 'Eyes Cry', 'Angry Sign', 'Shock Sign', 'Remove Expressions', 'Anim Shake', 'Sad Shock']
action_embeddings = sync_get_embedding(live2D_action_emotions)说明:live2D_action_emotions和action_embeddings的作用?
- 简单说 根据用户发来的弹幕响应对应的动作,先去获取弹幕或者相关信息的向量,用这个向量查找action_embeddings中余弦相似度最接近的向量,也就是最接近的动作,作为响应action。
- 动作响应不一定依靠embedding,实际效果差强人意,用embedding是因为我有考虑到 后期可以给用户的输入匹配更多上下文。上下文可以来源于任何地方 贴吧、小红书...只要提前生成向量保存到向量数据库即可,让AI主播的回答更丰富。
- 关于openai的embedding的介绍和作用,可以看openai文档 Embeddings - OpenAI API
- 终端输入
python ./main,正常情况会先打印连接信息,在打印运行debug
网上有教程
- 再用openai库的acreate 关闭ssl还是会偶尔遇到ssl报错,怀疑lib底层调aiohttp有冲突,使用create后报错明显减少
- 和vts交互上,最开始尝试keyboard键盘操作操控,发现vts的快捷键不像其它软件一样,只能通过pyvts调用api实现动作响应
- 在这个AI主播的场景里,需要确保每个 消息队列出队-处理-输出过程的原子性,最好不要同时处理多个弹幕(Event)
- 协程适合轻量级的任务,或者说一个协程函数里awiat不能太多,否则并发安全很难维护
- 每个线程要创建自己的事件循环
- 本项目利用协程解耦不同的生产消费过程,也可以看看这篇文章写个AI虚拟主播:看懂弹幕,妙语连珠,悲欢形于色,以一种简单的实现 - 掘金 (juejin.cn),它用到端口/进程解耦,最后把所有组件用Go组装,AI 主播 总体流程都差不多
- 4.26 支持抖音直播
欢迎加我WX:yuchen59384 交流!