Machine learning, data exploration, and data viz for volleyball data https://www.volleydataverse.com/
The project adds a more scientific spin to the classical analyses of volleyball statistical data, trying to add to a descriptive approach some novel predictive and interpretative approaches. The goal of the project is to take more data-driven decisions, find non-trivial patterns, and hopefully using that knowledge during volleyball games to maximize the winning odds.
The project currently includes:
- 01_hypothesis_testing: Intro to the dataset and presentation of different solutions for hypothesis testing
- 02_linear_regression: With a goal of interpretation, use linear regression models to evaluate which factors are most important in determining the side-out performance
- 03_classification: Prediction of attacker served by the setter in side-out
- 04_clustering_unsupervised: Clustering of outside-hitters based on performance
What is a sideout?

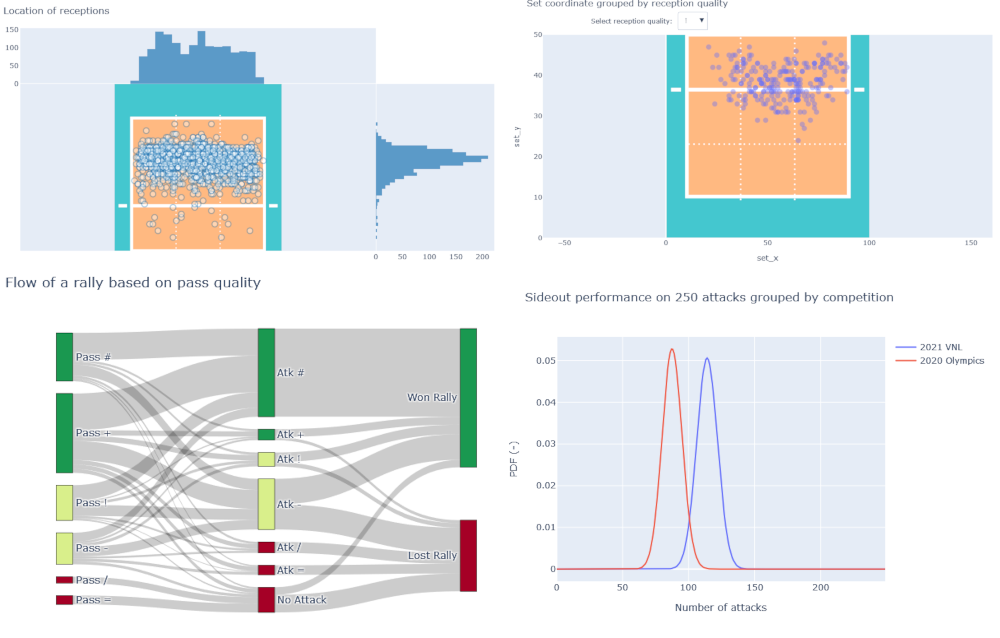
See the results here: https://www.volleydataverse.com/advanced-analysis/hypothesis-testing
- In the context of the 2021 Summer Season, data from the USA National Team was used to prove (and disprove) some hypotheses in a strict statistical sense
- The work includes a data exploration section, that uses both descriptive statistics and interactive visualization techniques
- Hypothesis testing proceeds from the analysis of a contingency table, using Binomial test, Chi-square test, and Fisher's exact test to investigate null and alternative hypotheses
- This work was developed with Python in a Jupyter Notebook, using Pandas as a framework for most operations, Plotly and Seaborn as visualization libraries
-

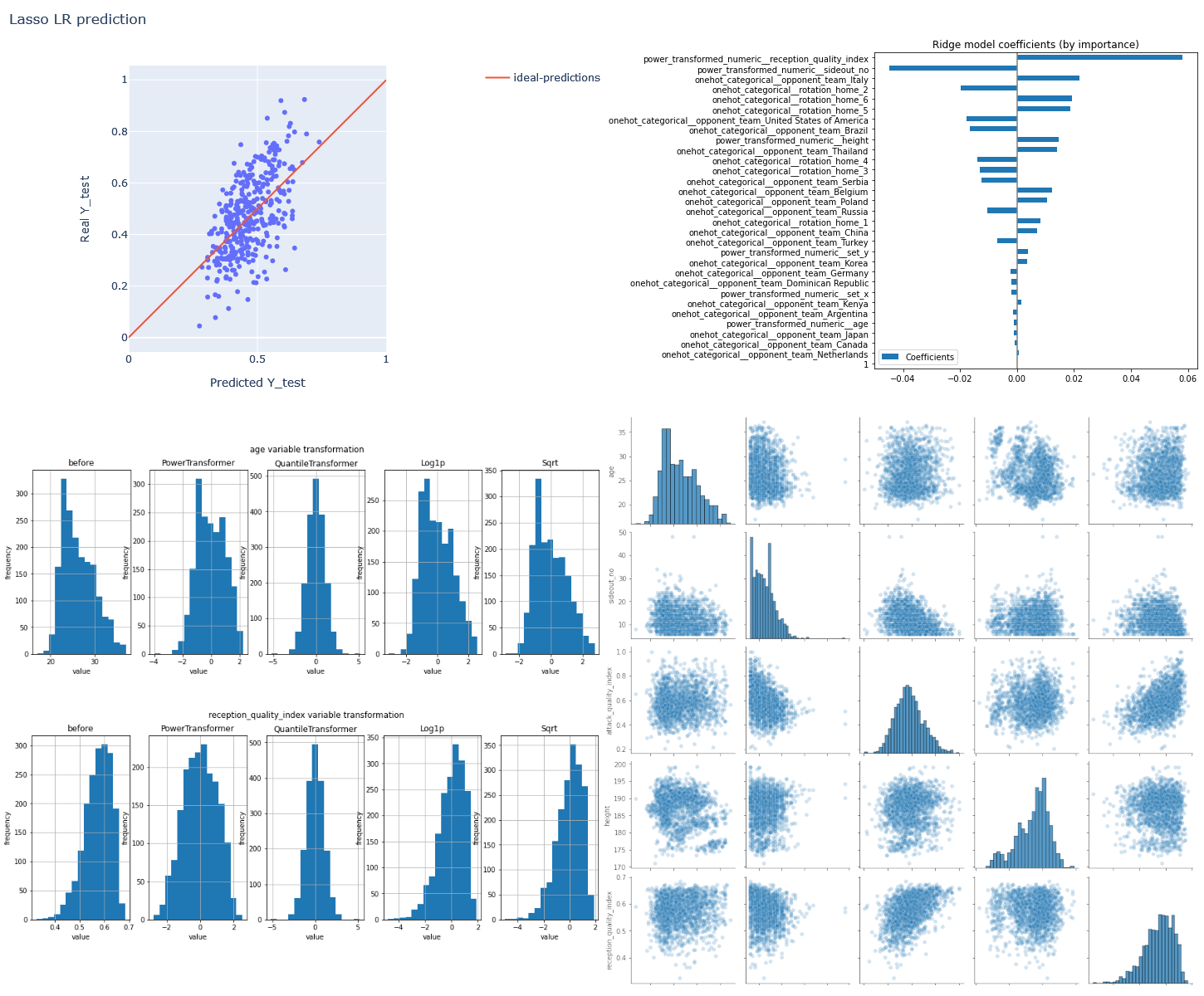
See the results here: https://www.volleydataverse.com/advanced-analysis/linear-regression-ml
- In the context of the 2021 Summer Season, data from the 2020 Tokyo Olympics and 2021 Volleyball Nations League was used in linear regression machine learning models to evaluate the importance of different features on team's attack quality. The models are hence more targeted to interpretation of the observed data rather than prediction
- The work includes a data exploration section, that uses both descriptive statistics and visualization techniques, with a correlation analysis
- It follows a data engineering and data preparation using a pipeline for the machine learning linear regression models
- Results from linear regression models (linear regression, Ridge regression, Lasso regression, ElasticNet regression) are compared, including polynomial features
- An 80-20 training-test split is used, with k-fold validation (10-folds) and GridSearchCV to find the appropriate regularization hyperparameter/s when appropriate
- This work was developed with Python in a Jupyter Notebook, using Pandas and scikit-learn, with Plotly and Seaborn as visualization libraries

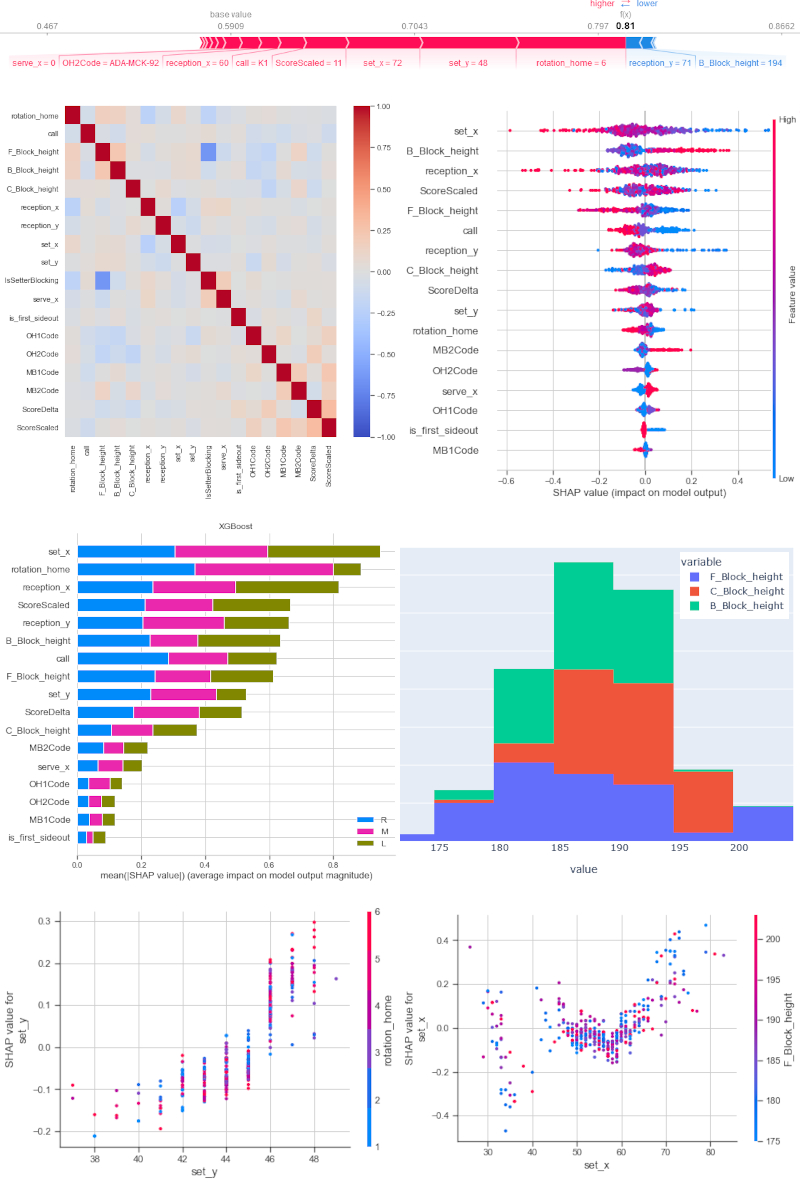
See the results here: https://www.volleydataverse.com/advanced-analysis/classification-ml
- Several machine learning classification algorithms were used to predict setter Asia Wolosz (Imoco Conegliano) choices in side-out based on the available information. The models target prediction, however, they will also learn for us which factors are the most important in driving her decisions
- The data-set consists of data from the 2019/2020 season of Imoco Conegliano kindly provided by César Hernández González
- The work includes a data exploration section with a correlation analysis, and it uses descriptive statistics and visualization techniques. A data engineering and data preparation using a pipeline follows, in preparation for the classification models
- Results from several classifier models (XGBoost, Random Forest, HistGradientBoosting, SVC, ExtraTrees, GradientBoosting, Logistic Regression, ADABoost, DecisionTree, K-Neighbors) are compared. The tuning procedure, both manual and using Hyperopt, is described
- Model interpretation with Shapley values (using the SHAP library) is provided
- In the context of the 2021 Summer Season, data from the 2020 Tokyo Olympics and 2021 Volleyball Nations League was used in linear regression machine learning models to evaluate the importance of different features on team's attack quality. The models are hence more targeted to interpretation of the observed data rather than prediction
- The work includes a data exploration section, that uses both descriptive statistics and visualization techniques, with a correlation analysis
- It follows a data engineering and data preparation using a pipeline for the machine learning linear regression models
- Results from linear regression models (linear regression, Ridge regression, Lasso regression, ElasticNet regression) are compared, including polynomial features
- This work was developed with Python in a Jupyter Notebook, using Pandas and scikit-learn, with Plotly and Seaborn as visualization libraries

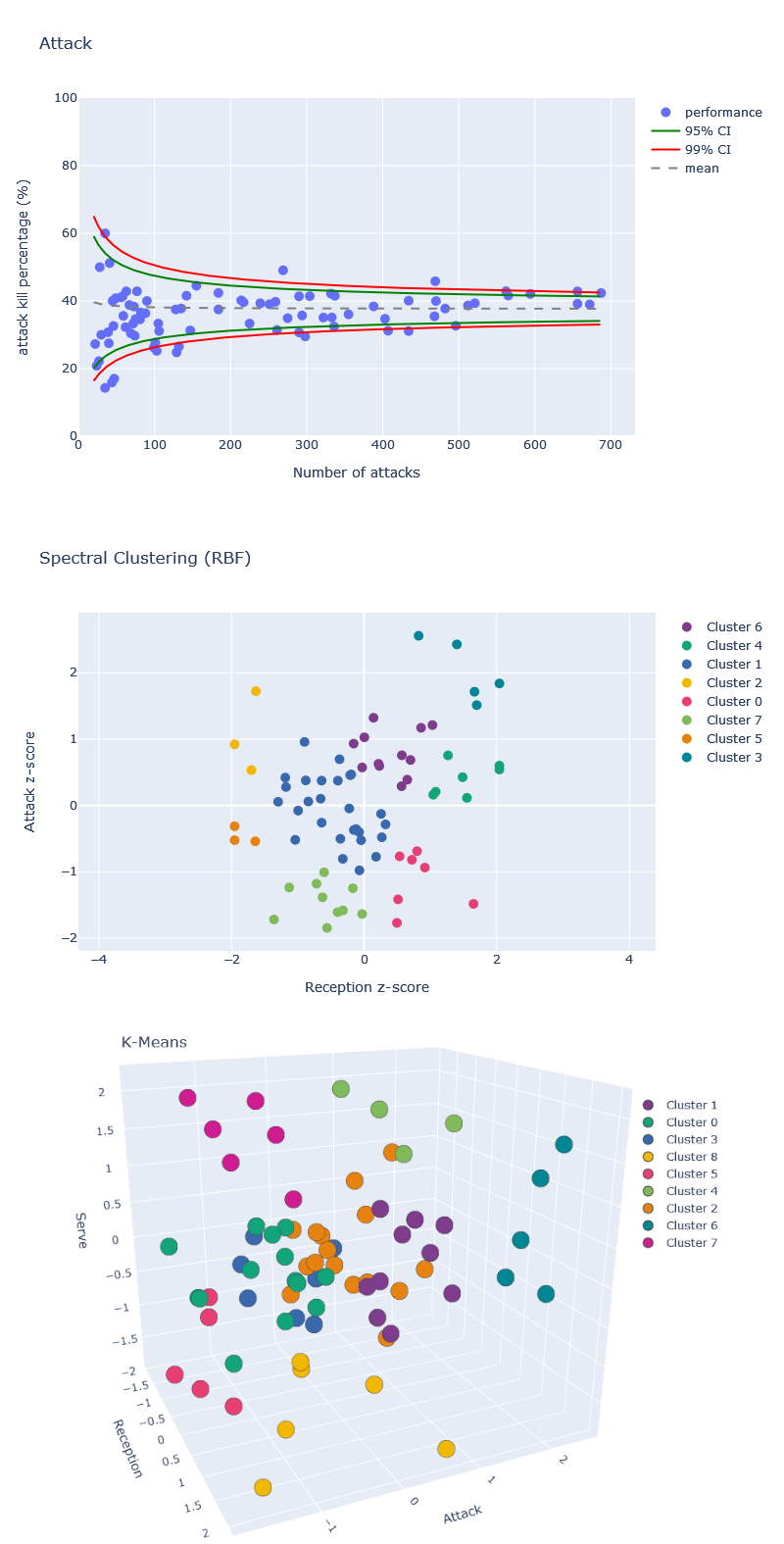
See the results here: https://www.volleydataverse.com/advanced-analysis/clustering-ml
- In the context of the 2021 Summer Season, data from the 2020 Tokyo Olympics and 2021 Volleyball Nations League was used with several clustering algorithms to group outside hitters based on their attack, reception, and serve performances
- The work includes a standardization of the performance indexes to compare players with different amount of data available
- Results from several clustering models (K-Means, Agglomerative Clustering, Spectral Clustering, DBSCAN, Mean Shift) are displayed for a 2-feature and 3-feeature analysis (with same weight)
- This work was developed with Python in a Jupyter Notebook, using Pandas and scikit-learn, with Plotly as visualization library
- This work was developed with Python in a Jupyter Notebook, using Pandas and scikit-learn, with Plotly as visualization library
