![]()
Sparkify, a music streaming startup, is experiencing a solid expansion in their user base and song database, and to improve its resources and services performance, the company needs to move the data warehouse to a data lake. The response to this big data job needs the adoption of a distributed, in-memory data structures processing engine like Apache Spark.
In order to support the analytics team to continue discovering insights (i.e. behaviours, interactions) in their users and music world, as data engineers at Sparkify, we have been asked to build an ETL pipeline that extracts the data from a data lake like Amazon Simple Storage Service (S3) (in JSON format), processes it using Spark, and loads the data back into S3 as a set of dimensional tables (in Parquet format).
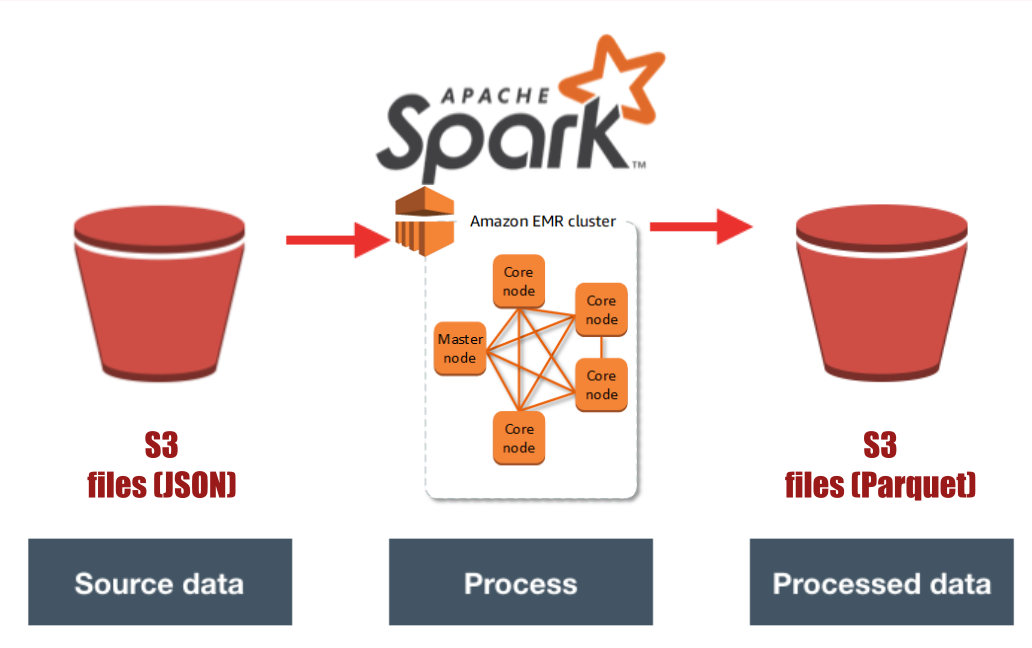
For this job we have adopted Spark (Python API - PySpark) to distribute the processing across the Amazon Elastic MapReduce (EMR) cluster, Amazon S3 as object storage service (data lake), and AWS SDK for Python - Boto3 to create/configure/manage Amazon services.
Taking advantage of PySpark SQL we have the ETL processing, first, the song dataset to produce songs and artists data (songs data is partitioned by year and artist_id values); second, processing log dataset to produce users and time data (time is partitioned by year and month values); third, joining data from song and log objects to produce songplays (songplays is partitioned by year and month values).
For the sake of this project the data and metadata under processing is part of the Million Song Dataset1 - the song dataset contains metadata about songs and artists. The log dataset holds log files about users activity and was generated by the program eventsim.
- s3://udacity-dend/song_data
- s3://udacity-dend/log_data
sparkify-spark
| .gitignore # Config file for Git
| analytics.ipynb # Test sparkify
| dl.cfg # Configuration parameters for AWS
| emr_summary.txt # Cluster definition summary (parameters)
| etl.py # Runs ETL pipeline to ingest, wrangler & load data
| launch.py # Launches AWS services (clients, clusters, storages)
| README.md # Repository description
| requirements.txt # Contains libraries needed to run scripts
|
└--graphics
| data_model.png # Data model
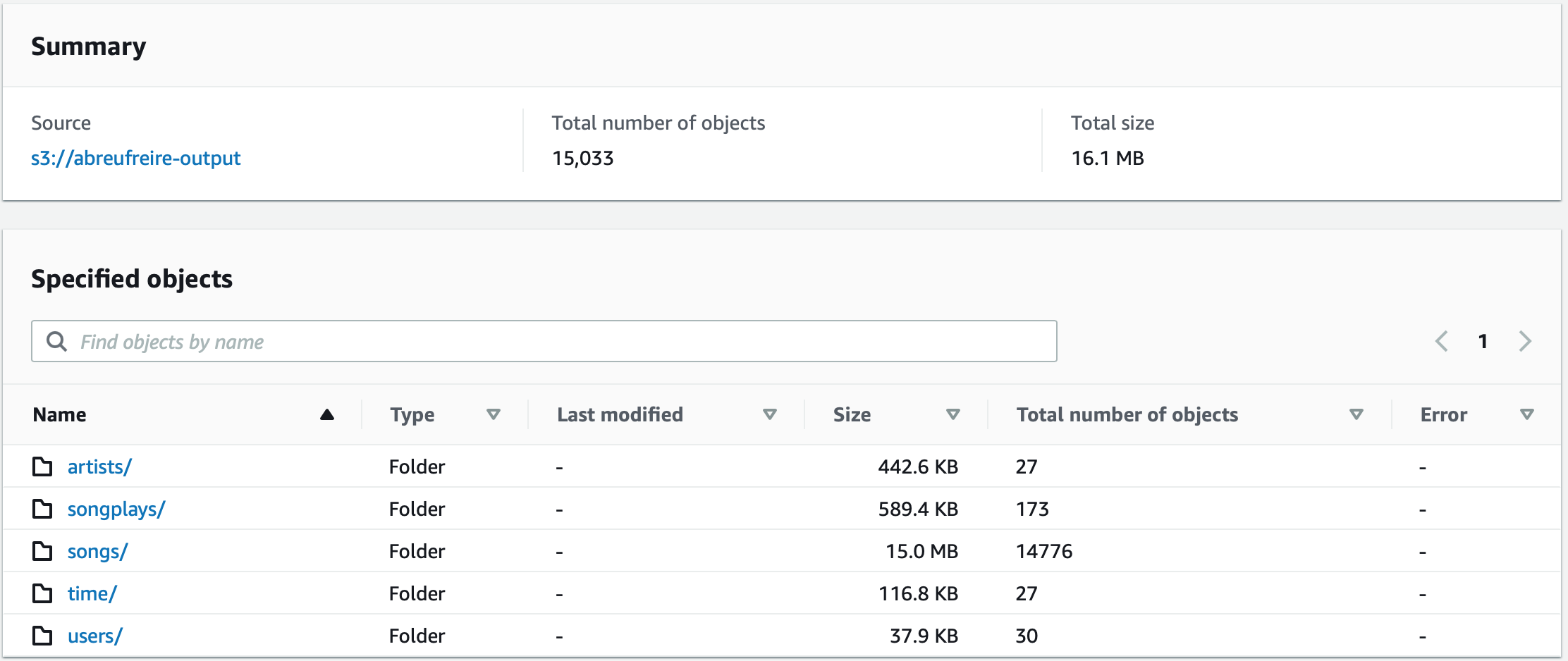
| s3_output_content.png # Content & size of data output bucket
| sparkify_logo.png # Project logo (source: Udacity)
SONGPLAYS (fact)
|-- songplay_id: long (nullable = false)
|-- start_time: timestamp (nullable = true)
|-- year: integer (nullable = true)
|-- month: integer (nullable = true)
|-- user_id: string (nullable = true)
|-- level: string (nullable = true)
|-- song_id: long (nullable = true)
|-- artist_id: string (nullable = true)
|-- session_id: long (nullable = true)
|-- location: string (nullable = true)
|-- user_agent: string (nullable = true)
ARTISTS (dimension)
|-- artist_id: string (nullable = true)
|-- name: string (nullable = true)
|-- location: string (nullable = true)
|-- latitude: double (nullable = true)
|-- longitude: double (nullable = true)
SONGS (dimension)
|-- title: string (nullable = true)
|-- artist_id: string (nullable = true)
|-- year: integer (nullable = true)
|-- duration: double (nullable = true)
|-- song_id: long (nullable = false)
TIME (dimension)
|-- start_time: timestamp (nullable = true)
|-- hour: integer (nullable = true)
|-- day: integer (nullable = true)
|-- week: integer (nullable = true)
|-- month: integer (nullable = true)
|-- year: integer (nullable = true)
|-- weekday: integer (nullable = true)
USERS (dimension)
|-- user_id: string (nullable = true)
|-- first_name: string (nullable = true)
|-- last_name: string (nullable = true)
|-- gender: string (nullable = true)
|-- level: string (nullable = true)
Clone this project, and to up and running it LOCALLY go to its directory (local machine) and create a virtual environment (venv), activate it and install the requirements.txt.
In order to run PySpark locally, Java/JDK needs to be installed in the machine, JAVA_HOME & SPARK_HOME variables need to be defined (declaration done in etl.py).
$ python3 -m venv /path/to/new/venv
$ source venv/bin/activate
$ pip install -r requirements.txt
Using AWS services add parameters to data lake configuration file (dl.cfg):
- create an IAM user (with admin privileges) and take its security credential values (ACCESS & SECRET KEYS);
- create an Elastic Computing Cloud (EC2) key pair to connect (SSH) with EC2 instances (nodes) running inside cluster and take its name (eg name: "aws-ec2-keys");
- pick one Virtual Private Cloud (VPC) Subnet (eg ID: "subnet-a78b978c").
$ python3 launch.py # uses etl.py (spark-submit job)
While EMR is running use EMR console or Spark UI (http://localhost:4040) to check jobs status.
$ jupyter notebook # launches app/browser/localhost with the project files
Navigate to analytics.ipynb and run/analyze it.
Note: When do not need anymore data stored in S3, delete it in S3 console.