Motivation
Results
Bundled-Edged Views of the Github Event Graph
Methodology and Source Code
At the heart of this plot are the SQL (or rather, BQL) queries sent to Google Bigquery. The queries consist of two types: a model query and state query. The model query collects the data necessary for building a markov matrix by counting transitions between sequential events. The state query computes a census of the most recent events (i.e. events not followed by another event). These two sets of data are then "munged" by munger.py. A cluster detection algorithm is used to group events. The results are gathered into a single JSON structure (example:results.json). The front end retrieves the results via AJAX and generates the illustrations using D3js.
Dependencies
This application uses MCL. The source is contained in the external/ directory. Install as follows:
tar xfz mcl-latest.tar.gzcd mcl-14-137- ``configure --prefix=`pwd```
makemake install
MCL will then be installed to external/mcl-14-137. If you install to a different path, then change the MCL_BIN string found in mclinterface.py.
Numpy/Scipy are also required. If you're using Mavericks, use this: ScipySuperpack.
Authorization of APIs
This application uses Google Bigquery. You'll need to supply authenticated credentials:
- Log into Google Developer Console
- Navigate to the project list
- Create a new project. (Or use one you may have previously created :)
- Enable the BigQuery API: Select Project -> APIs and Auth -> API's -> BigQuery
- Generate a client_secrets JSON -> API's and Auth -> Credentials -> Create New Client ID
- Download the generated JSON and save as
client_secrets.jsonto the root of this project. - When you run the app a browser window will open and request authorization.
- Authorize it.
Data Collection and Munging
main.py is where interested readers should begin. It is invoked as follows:
python main.py -i identifier -q bigquery-id model:model.sql state:state.sql
-i [setId]This identifies the set. The query results will be stored in a folder named data/[setId]. If no query is specified using-q, then the most recent queries in the [setId] folder will be (re)munged.-q [projectId] [name:sql name2:sql2] ...projectId is a BigQuery project number (ex: 'spark-mark-911'). The [name:sql] entries specify sql files and the id to use when storing the results. Each of the sql files will be sent to BigQuery, and the responses recorded underdata/[setId]/[name]. The munger will subsequently process the responses to produceresults.json.
Use the Scripts
collect.sh demonstrates the use of main.py. It is the same script used to generate the results used by this page. If you wish watch it operate:
./collect.sh [projectId] You'll need to specify the projectId obtained from your Google developer console.
deploy.sh generates the presentation pages and writes them to the specified directory. It assumes that collect.sh has completed successfully. The generated site should be served through a webserver because the results.json files are loaded through Ajax. If you do not have a local webserver then node http-server or Python's SimpleHTTPServer are easy and recommended:
./deploy.sh deployed/path/http-server deployed/path/orcd deployed/path && python -m SimpleHTTPServer 8080- Navigate to http://localhost:8080
Citations
- Stijn van Dongen, Graph Clustering by Flow Simulation. PhD thesis, University of Utrecht, May 2000. link
Contact
Addendum
These images show the evolution from very hairball, to less hairball, to combed hairball.
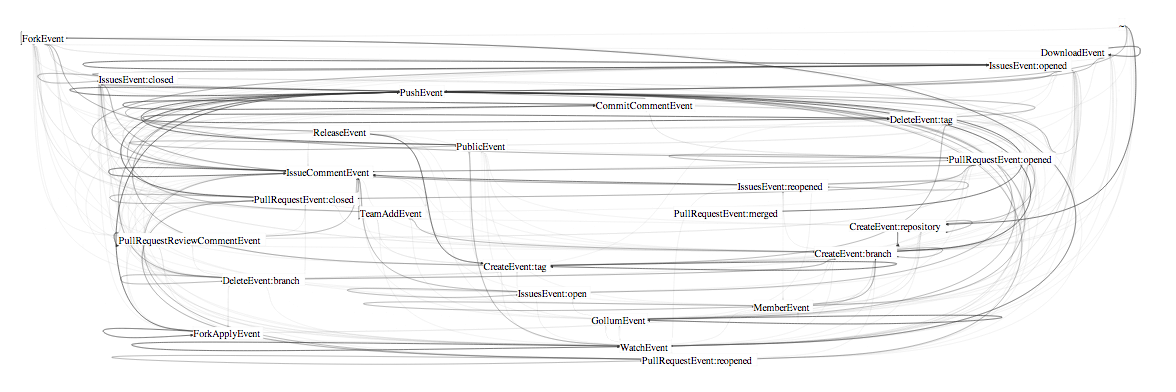
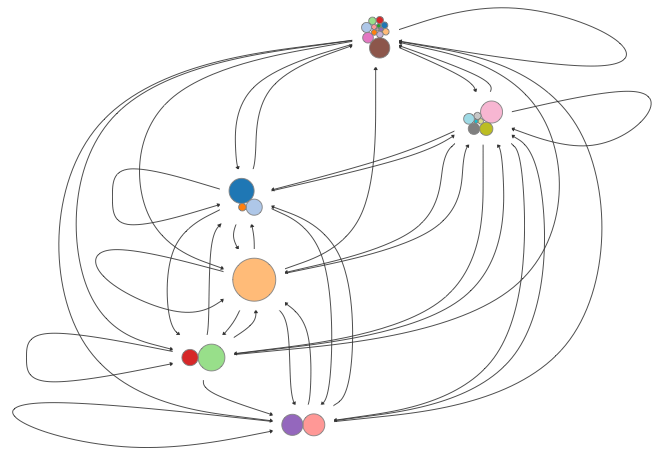

More Features
Please visit the dev branch: README.md for additional features developed after submission. The conclusion of this competition shares poetic cohomology with a certain video of a polar bear and a can of condensed milk (video no longer available).