An intuitive and powerful scouting solution for FRC robotics teams. A video demo can be found here
The purpose of Phoenix Scout is to enable quick scouting entry and consumption during a robotics competition.
FIRST robotics is an international high-school robotics organization where each year, a new game is announced and teams are given 6 weeks to design, manufacture, and program a robot to compete at regional events. Each event brings together 40-60 different teams, in which they compete in randomly assigned qualification matches for a spot in in the finals.
Each match is designed such that 3 robots play against 3 other robots. It becomes imperative that a team has readily available statistics on the abilities of every robot on the field. This can help enable a team to devise a successful strategy.
The main objectives for the Phoenix Scout system are:
-
Easy Data Entry
A student is assigned to collect performance data on a robot, where they gather relevant data on the robot's performance. Many solutions in the past have primarily used either paper forms, a centralized excel sheet to process the data, or a combination thereof. This often involves a lot of manual work to centralize all this data, and even more consideration to keep all this data in sync. This can be fully automated, as this project sets out to accomplish.
-
Immediate Data Views
Previous solutions have always required some element of manual work to process raw data and put this into the hands of those who need it. The solution presented here seeks to eliminate this completely by hosting a centralized backend API service which becomes the source of truth.
-
Offline-first access
There are many unique constraints that the physical venue poses. Often, due to dense concentration of people at these events, the network service may be limited. Therefore, a requirement of a fully online system requires that no data is lost if network service is unavailable, and that changes are synced once the device comes back online.
This application consists of a frontend, backend, and database layer. This project utilizes docker to manage each process.
- Duplicate and rename the sample
.env-examplefile to.env. - Install docker and docker-compose for your operating system.
- Run the following command
> docker-compose up -d- Visit localhost:3000 in the web browser.
- React (utilizes React Hooks)
- MongoDB
- Node.js backend (Express framework)
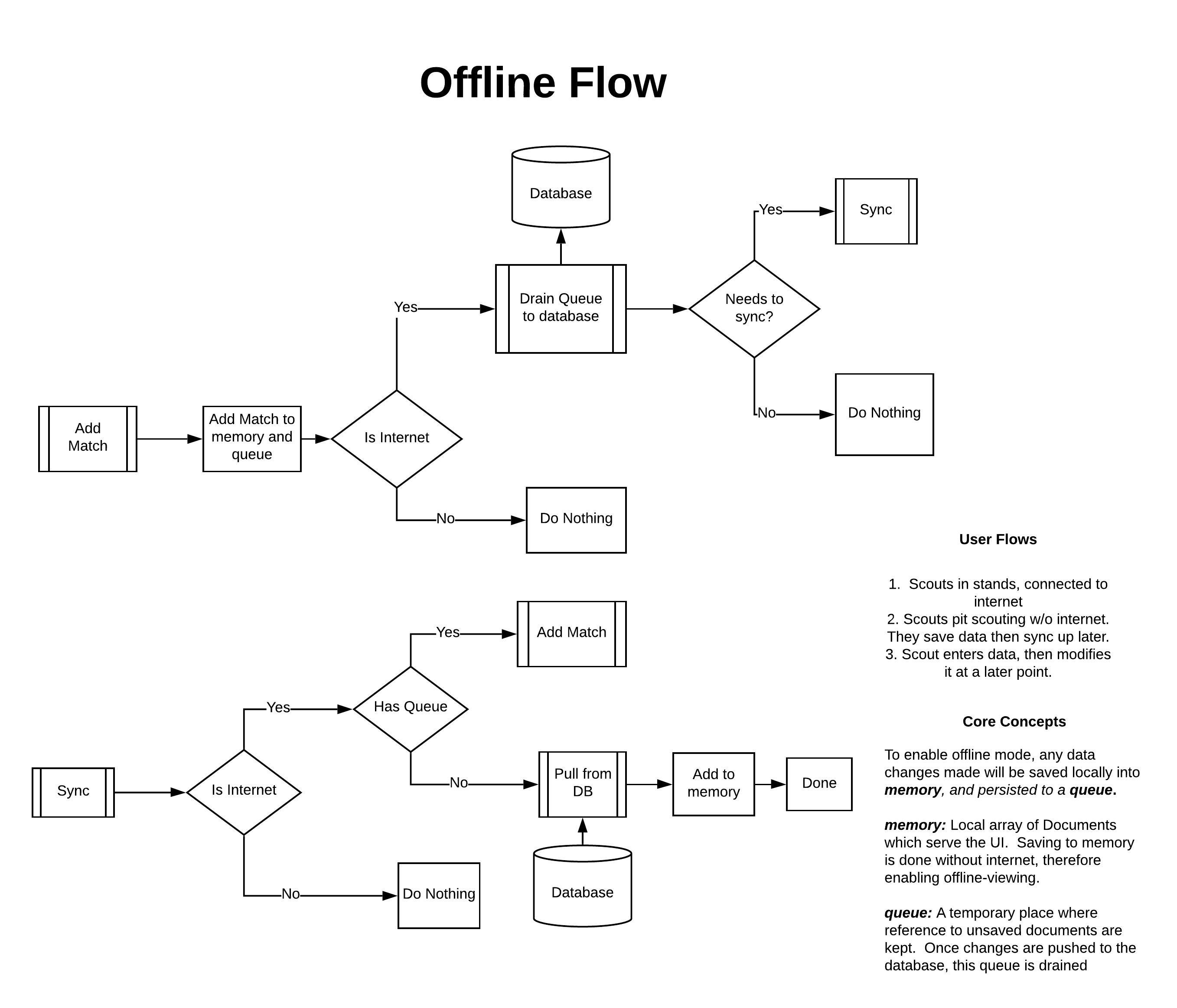
The central requirement for this application is to enable seamless data entry/display irrespective of one's network connectivity -- If connection to the server is broken, one can still enter new data and see changes reflected immediately.
Immediate data access drives the need to hold all data in memory. With data cached in memory, data access is possible irrespective of network connectivity. The problem to be solved is how to reconcile a possibly modified local cache of data with possibly modified data from the server.
This is the problem of concurrency in a multi-user application, where applications such as Google Drive seek to reconcile a stream of data changes all happening at once.
For the purposes of this application, it was determined that updates do not have to happen in real-time. For this reason, the proposed solution implemented in this application is to:
- Have data held in memory as the source of truth. Any updates to a preexisting document changes this in-memory data, and additionally adds the unique document key to a queue.
- When data is to be synced with the server, this queue is used to find documents that were changed locally, pushing the newest state of these documents to the server before draining this queue.
This solution meets the requirement that the application provides a way to add/update existing data in an offline-first environment.
This solution was implemented as follows:
-
Client (Link to Custom Hook)
-
A custom React hook was written which manages the offline flow. A diagram of the hook architecture is shown below:
-
-
-
Server (Link to Controller)
- The solution described requires that the backend exposes a GET/POST REST endpoint. The GET endpoint returns a dump of all data, where the POST endpoint accepts full document objects. New documents not already present in the database will be inserted into the database, while if a document ID is passed inside of the object, then MongoDB will try to modify an existing document accordingly.
