
This R package provides a set of methodological tools that enable researchers to apply matching methods to time-series cross-section data. Imai, Kim, and Wang (2018) proposes a nonparametric generalization of difference-in-differences estimator, which does not rely on the linearity assumption as often done in practice. Researchers first select a method of matching each treated observation from a given unit in a particular time period with control observations from other units in the same time period that have a similar treatment and covariate history. These methods include standard matching and weighting methods based on propensity score and Mahalanobis distance. Once matching is done, both short-term and long-term average treatment effects for the treated can be estimated with standard errors. The package also offers a visualization technique that allows researchers to assess the quality of matches by examining the resulting covariate balance.
You can install the most recent development version of PanelMatch using the devtools package. First you have to install devtools using the following code. Note that you only have to do this once:
if(!require(devtools)) install.packages("devtools")Then, load devtools and use the function install_github() to install PanelMatch:
library(devtools)
install_github("insongkim/PanelMatch", ref = "arg_changes", dependencies=TRUE)If you encounter problems during installation, please consult the wiki page that has some ideas for handling common issues.
Users can visualize the variation of treatment across space and time. This will help users build an intuition about how comparison of treated and control observations can be made.
library(PanelMatch)
DisplayTreatment(unit.id = "wbcode2",
time.id = "year", legend.position = "none",
xlab = "year", ylab = "Country Code",
treatment = "dem", data = dem)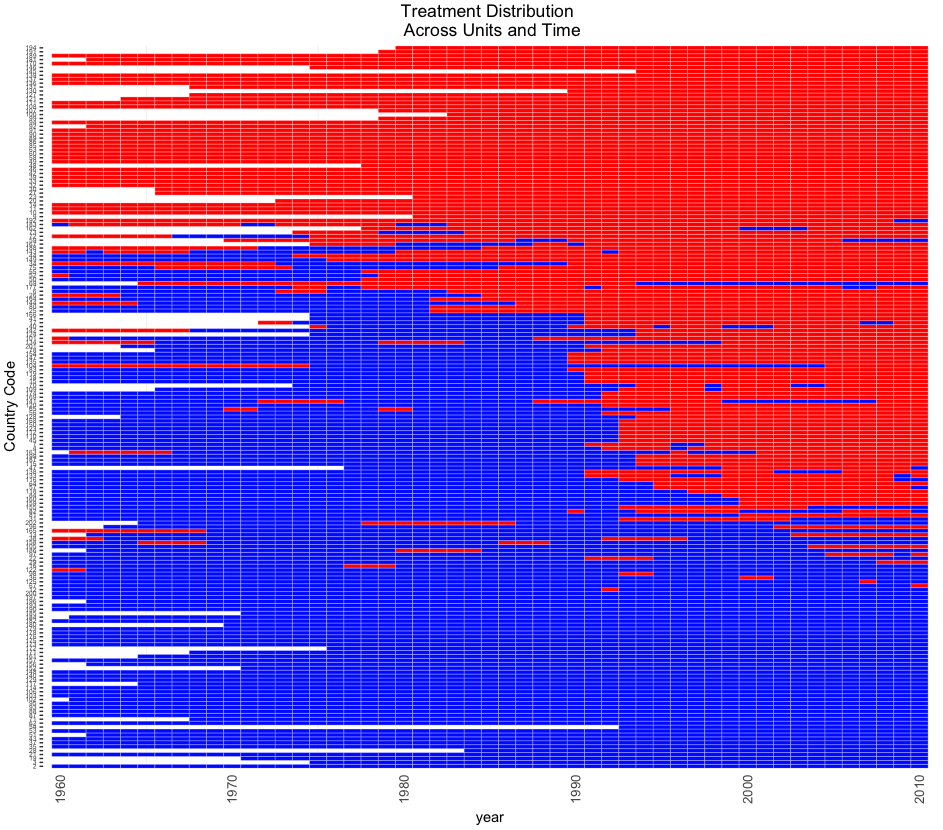
PanelMatch identifies a matched set for each treated
observation. Specifically, for a given treated unit, the matched set
consists of control observations that have an identical treatment
history up to a chosen number (lag) of years. This number corresponds with the lag parameter, which must
be chosen by the user. Users must also consider various parameters regarding the refinement of created matched sets:
refinement.method-- Users may choose between standard propensity score weighting or matching (ps.weight,ps.match), covariate balanced propensity score weighting or matching (CBPS.weight,CBPS.match), and mahalanobis distance matching (mahalanobis).size.match-- This sets the maximum number of control units that can be included in a matched set.covs.formula-- This sets which variables are considered in creating the refined matched sets. This can be set to include lagged versions of any variable as well. See thePanelMatchdocumentation for more information about this parameter.
PM.results <- PanelMatch(lag = 4, time.id = "year", unit.id = "wbcode2",
treatment = "dem", refinement.method = "mahalanobis",
data = dem, match.missing = T,
covs.formula = ~ lag("tradewb", 1:4) + lag("y", 1:4), size.match = 5, qoi = "att"
,outcome.var = "y",
lead = 0:4, restricted = FALSE)
The PanelMatch function will return a matched.set object. Users can extract information about individual matched sets as well as statistics about all created matched sets from this object. Consult the Wiki page on Matched Set Objects for a much more detailed walkthrough and description of these objects.
Once proper matched sets are attained by PanelMatch, users can
estimate the causal quantity of interest such as the average
treatment effect using PanelEstimate. Either bootstrap or weighted
fixed effects methods can be used for standard error
calculation. Users can estimate the contemporaneous effect as well as
long-term effects. In this example, we illustrate the use of
PanelEstimate to estimate the average treatment effect on treated units (att) at time t on the outcomes from time t+0 to t+4.
PE.results <- PanelEstimate(inference = "bootstrap", sets = PM.results,
data = dem)The PanelEstimate function returns a PanelEstimate object, which is a named list. This object will contain the point estimates, standard errors and other information about the calculations. See the wiki page about PanelEstimate objects for more information.
Users can easily obtain and visualize important information about esimtates and standard errors using the summary and plot methods for PanelEstimate objects
summary(PE.results)
Weighted Difference-in-Differences with Mahalanobis Distance
Weighted Difference-in-Differences with Covariate Balancing Propensity Score
Matches created with 4 lags
Standard errors computed with 1000 Weighted bootstrap samples
Estimate of Average Treatment Effect on the Treated (ATT) by Period:
$summary
estimate std.error 2.5% 97.5%
t+0 -0.7681861 0.6440107 -2.013483 0.5455004
t+1 -0.2523489 1.1154698 -2.375974 2.0014498
t+2 0.9621561 1.4521630 -2.001090 3.8658385
t+3 1.9590396 1.7087395 -1.466386 5.3701010
t+4 2.0175749 1.8790923 -1.819543 5.6716292
$lag
[1] 4
$iterations
[1] 1000
$qoi
[1] "att"plot(PE.results)