Unbreakable DevOps Pipeline Tutorial with AWS CodeDeploy, AWS CodePipeline, AWS Lambda, EC2 and Dynatrace.
The goal of this tutorial is having a full end-to-end AWS DevOps Pipeline (Staging, Approval, Production) that is fully monitored with Dynatrace. With Dynatrace injected into the pipeline we implement the following use cases:
- FullStack Monitor your Staging Environment
- Shift-Left: Automate Approve/Reject Promotion from Staging to Production based on Performance Data captured while running continuous performance tests
- FullStack Monitor your Production Environment
- Self-Healing: Automatic Deploy of previous revision in case Dynatrace detected problems in Production
You can also download the slides we used at our Dynatrace PERFORM 2018 HOT (Hands On Training) Day. The slides contain more background information and more detailed steps!
Before we launch the CloudFormation stack which will create all required resources (EC2 Instances, Lambdas, CodeDeploy, CodePipeline, API Gateway) lets make sure we have all pre-requisits covered!
- You need an AWS account. If you dont have one get one here
- You need a Dynatrace Account. Get your Free SaaS Trial here!
- You need to clone or copy the content of this GitHub repo to your local disk!
Amazon Web Services (AWS)
As we are going to use AWS CodeDeploy, AWS CodePipeline, AWS Lambda, DynamoDB, API Gateway and EC2 make sure the AWS Region you select provides all these services. We have tested this cloud formation on US-West-2a (Oregon) and US-East-2b (Ohio). To be on the safe side we suggest you pick one of these regions!
- Create an EC2 Key Pair for your AWS Region! Our CloudFormation Template needs an EC2 Key Pair! 1.1. To learn more about Key Pairs and how to connect to EC2 Instances for troubleshooting read Connect to your Linux Instance
- Create a S3 Bucket with the naming scheme: -dynatracedevops and enable versioning. See following screenshots for reference
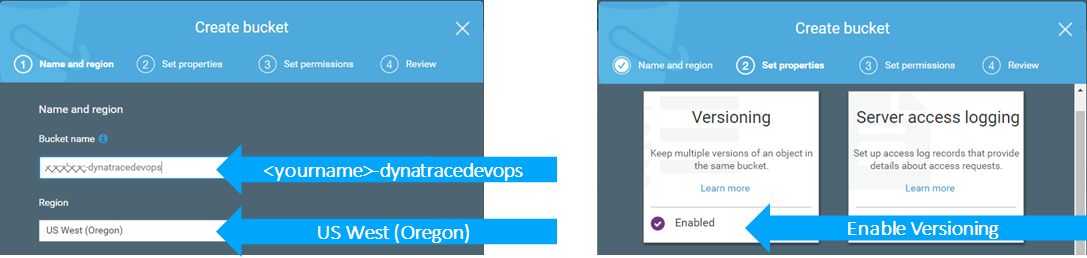
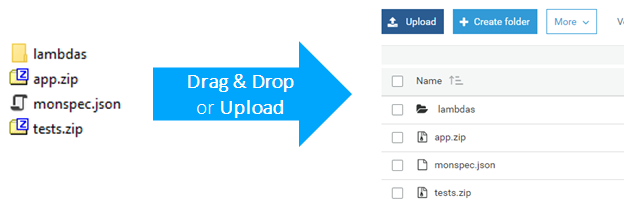
- Copy the content from the folder "copytos3" to your newly created S3 bucket. This includes the application package, tests, monspec as well as all Lambda functions


Dynatrace
We need a couple of things to launch the CloudFormation Template
- Your Dynatrace Tenant URL: For SaaS that would be something like http://.live.dynatrace.com. For Managed it would be http:///e/
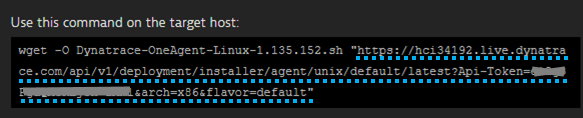
- Your Dynatrace OneAgent for Linux Download URL: Go to Deploy Dynatrace -> Start Installation -> Linux and copy the URL within the quotes as shown below:
- A Dynatrace API Token: Go to Settings -> Integration -> Dynatrace API and create a new Token



(optional)Setup Dynatrace AWS CloudWatch Monitoring)
Dynatrace has a built-in feature to pull in metrics and metadata (e.g: tags ) from CloudWatch. You can setup this integration as explained in the documentation: How do I start Amazon Web Services monitoring?
If you haven't cloned or downloaded the full GitHub repo then download the CloudFormation stack definition from here.
Now click on one of the regional links. This brings you to the CloudFormation Web Console where you can upload your downloaded CloudFormation Stack Definition.
| Region | Launch Template |
|---|---|
| Oregon (us-west-2) | Launch Dynatrace DevOps Stack into Oregon |
| N. Virginia (us-east-1) | Launch Dynatrace DevOps Stack into Virginia |
| Ohio (us-east-2) | Launch Dynatrace DevOps Stack into Ohio |
| Ireland (eu-west-1) | Launch Dynatrace DevOps Stack into Ireland |
| Frankfurt (eu-central-1) | Launch Dynatrace DevOps Stack into Frankfurt |
| Tokyo (ap-northeast-1) | Launch Dynatrace DevOps Stack into Tokyo |
| Seoul (ap-northeast-2) | Launch Dynatrace DevOps Stack into Seoul |
| Singapore (ap-southeast-1) | Launch Dynatrace DevOps Stack into Singapore |
| Sydney (ap-southeast-2) | Launch Dynatrace DevOps Stack into Sydney |




There is a lot of useful information here, e.g: the PublicDNS of the two EC2 Instances that got created and also the links to the Public API Gateway we created that allows us to execute some Lambda functions.

Several things have been created.
The stack created two EC2 Instances. One for Staging, one that we use for Production. Go to your EC2 Section in the AWS Console and explore them:

These EC2 Instances launched with a special launch script that was passed in the UserData section of the EC2 Launch Configuration. This script installed requirement components such as the AWS CodeDeployAgent, Node.js, pm2 as well as the Dynatrace OneAgent. Here is a simplified version of that UserData script:
#1: Install Dynatrace OneAgent
yum update -y
yum install ruby wget -y
wget -O Dynatrace-OneAgent-Linux.sh "{{DynatraceOneAgentURL}}
sudo /bin/sh Dynatrace-OneAgent-Linux.sh APP_LOG_CONTENT_ACCESS=1
#2: Install Depending Software, e.g: httpd, nodejs, pm2
...
#3: Launch dummy PM2 App to pass Env Variables to OneAgent -> Trick to get Vars into Web UI
export DT_CUSTOM_PROP=DEPLOYMENT_GROUP_NAME=GROUP_NAME APPLICATION_NAME=APP_NAME
echo "console.log('dummy app run');" >> testapp.js
pm2 start testapp.js &> pm2start.log
#4: Install AWS CodeDeploy Agent and run CFN Update
...
Lets move to Dynatrace and validate that these two EC2 machines are actually monitored. In your Dynatrace Web UI simply go to Hosts - you should see 2 new hosts. If you have the Dynatrace AWS CloudWatch integration setup the host name should reflect the actual names Staging and Production. Otherwise it will show up the unique EC2 Instance Name:
 Sanity Check:
If you dont see these two hosts it means something went wrong with the OneAgent installation. Most likely root cause is that you didnt use the correct OneAgent Download Link when creating the CloudFormation stack. In that case. Delete the stack and start all over. Double check that you really copy the correct Download Link, Tenant URL and API Token!
Sanity Check:
If you dont see these two hosts it means something went wrong with the OneAgent installation. Most likely root cause is that you didnt use the correct OneAgent Download Link when creating the CloudFormation stack. In that case. Delete the stack and start all over. Double check that you really copy the correct Download Link, Tenant URL and API Token!
When clicking on one of these hosts you can also see that Dynatrace alread does FullStack monitoring of that host. Depending on how far the CodePipeline (that also executed in the background) already executed you may or may not see some additional Node.js processes here. As long as you start seeing any data here you are good :-)
 Notice:
If you have the Dynatrace AWS CloudWatch integraton setup you will see all AWS Tags being pulled in automatically. Also expand the properties section and see what meta data we collect. This is good to know as Dynatrace can do A LOT with metadata, e.g: rule based tags, rule based naming, ...
Notice:
If you have the Dynatrace AWS CloudWatch integraton setup you will see all AWS Tags being pulled in automatically. Also expand the properties section and see what meta data we collect. This is good to know as Dynatrace can do A LOT with metadata, e.g: rule based tags, rule based naming, ...
Go to AWS CodePipeline and validate that you see this new pipeline

First Pipeline Run will FAIL :-(
The Pipeline probably already executed as this happens automatically after CloudFormation created the Pipeline. The pipeline most likely failed at the "PushDynatraceDeploymentEvent" action. Thats OK and expected. If you click on details you will see that Dynatrace hasn't yet detected the Entities we try to push information to. This is a missing configuration step on the Dynatrace side.

Action: Configure Proper Dynatrace Service Tagging to detect Staging vs Production Services
While Dynatrace automatically identifies services based on service metadata, e.g: service name, technology, endpoints ... we can go a step further.
If the same service (same name, technology, endpoints ...) is deployed into different environments (Staging, Production) we want Dynatrace to understand which services run in which environments and put a Tag on it. Exactly the tag that our pipeline is expecting so that we can push and pull information for the each services based on which environment it is in!
For Dynatrace to automatically distinguish between a Staging and a Production version of a Microservice we leverage what is called "Rule-Based Tagging". AWS CodeDeploy will pass the Deployment Stage Name (Staging and Production) as an environment variable to the EC2 machine. Dynatrace will automatically pick up these environment variables as additional meta data but doesnt do anything with them unless we specify a rule that extracts this variable and applies it to the microservice monitoring entities.
Here is a short explainer what actually happens when AWS CodeDeploy deploys the app:

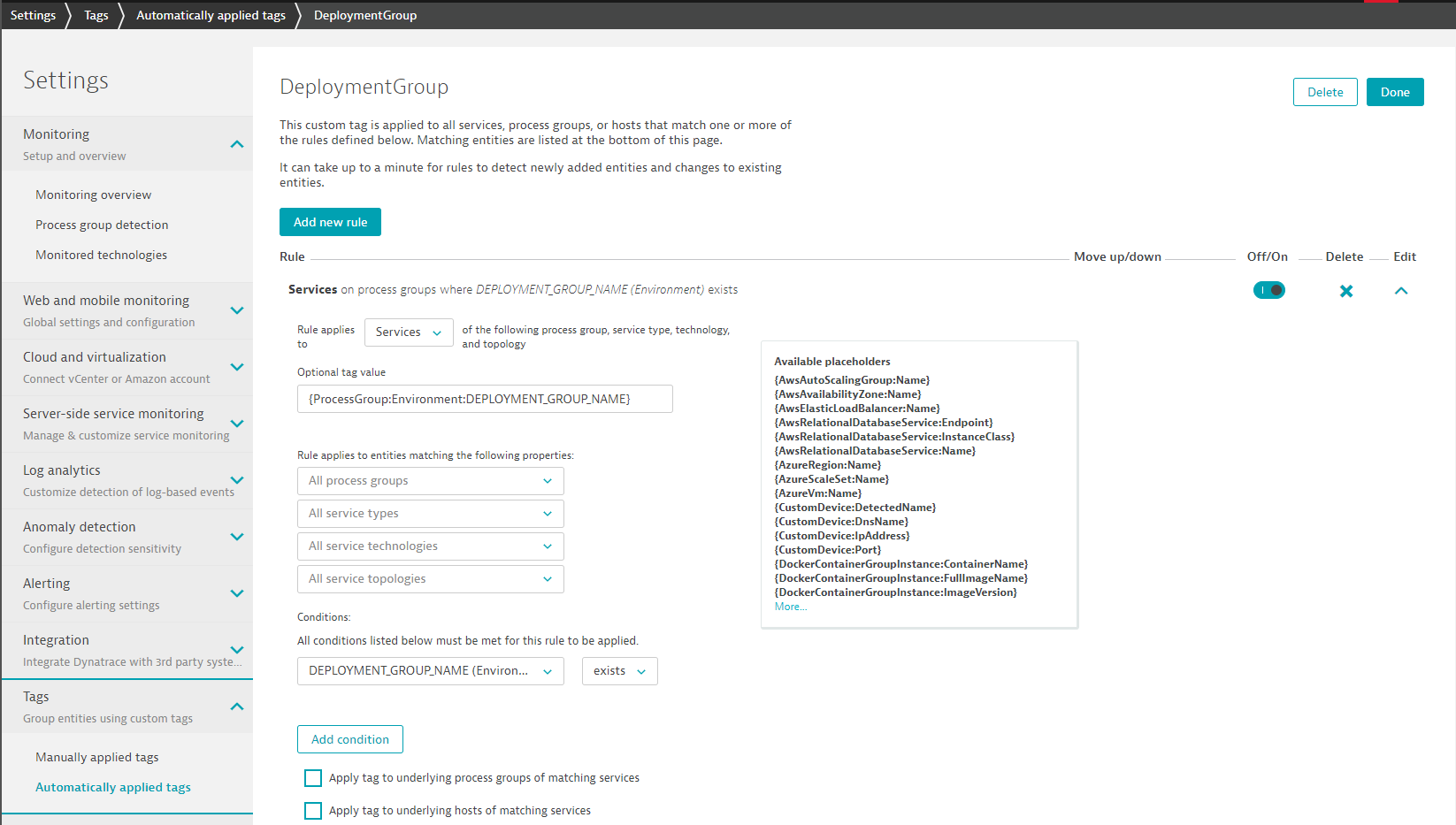
What we want is that Dynatrace extracts some of this meta data on that process and apply it as Tags on the Service. To do this: Please go to Settings -> Tags -> Automatically applied tags and add a new rule as shown in the next screenshot:
- Call the new Tag DeploymentGroup
- Edit that Tag and add a new rule that applies for Services
- In Optional Tag Value add: {ProcessGroup:Environment:DEPLOYMENT_GROUP_NAME}
- In the Condidition also specify that only those services should be tagged where the Process Group Environment Variable DEPLOYMENT_GROUP_NAME exists
- You can click on Preview to see which Services it matches. It should already match our Staging Service!
- Click SAVE!

ACTION: Lets run the Pipeline again
As the Dynatrace configuration for automated Service Tagging is now done, we simply run the pipeline again. Lets click on "Release change"

Pipeline Stages: Source and Staging The Pipeline pulls code from S3 and uses AWS CodeDeploy to deploy an application into staging, launch a simple "load testing script" and will lets Dynatrace know about these deployments by sending a Deployment Event to the monitored Services (this is where the tag rule we just created comes in). The Pipeline will also register a so called Dynatrace Build Validation run (we will learn more about this later).
Pipeline Stage: Approve Staging
Let the pipeline run until it reaches the Approve Staging stage. For now we manually approve the Pipeline once it hits that point. This is a stage we will later automate!

Pipeline Stage: Production Once we approve Staging the Pipeline continues to deploy our application in Production. It will launch another test script (well - we use this to simulate "real users") and will once again let Dynatrace know about that deployment by pushing an event on the monitored services that have the Production tag on it!
Pipeline Stage: Approve Production The last step in the Pipeline is to approve that Production Deployment was good. This is again a manual process for now!
If the Pipeline succeeded we should be able to navigate to our deployed application in Staging and Production. You saw the Public DNS for our two server instances in the CloudFormation Output. If you dont remember either go back to the CloudFormation overview or navigate to your EC2 Instances. You will see both instances there and you can also get to the Public DNS and also Public IP.
If we take the public IP or public DNS we simply put it in a browser and navigate to default port 80. Lets see whether our app is up and running!

GRANTED - not the most beautiful looking app, but it does its job :-)
Behind the scenes a Dynatrace OneAgent not only monitors our hosts (we verified that earlier), but does FullStack monitoring which includes EVERY process, service and application that gets deployed on these hosts!
Service Monitoring When CodeDeploy deployed the app it also pushed some additonal environment variables to the Node.js process, telling Dynatrace more about the actual application and services. Here is part of the start_server.sh script that CodeDeploy executes. You see that we are leveraging our DT_TAGS, DT_CUSTOM_PROP and DT_CLUSTER_ID. If you want to learn more about tagging options start with this blog post: Automate the tagging of entities with environment variables
export DT_TAGS=APPLICATION_NAME=$APPLICATION_NAME
export DT_CUSTOM_PROP="DEPLOYMENT_ID=$DEPLOYMENT_ID DEPLOYMENT_GROUP_NAME=$DEPLOYMENT_GROUP_NAME APPLICATION_NAME=$APPLICATION_NAME"
export DT_CLUSTER_ID="$DEPLOYMENT_GROUP_NAME $APPLICATION_NAME"
If you browse to your Dynatrace Web UI and then select Transaction & Services you will see the two detected services with their correct names and also the environment they run in (Staging or Production)

Lets click on the Service in Staging and explore what Dynatrace sees within that service:

You will notice that the service has our DeploymentGroup:Staging tag applied. That came in through the rule we defined earlier. The name "Staging" comes from an environment variable that is applied to the underlying process. We also start seeing performance metrics such as Response Time, Failure Rate, Throughput, CPU. The longer our service runs the more data we get. Also check out the events section. If you expand it you will find the deployment information from our AWS CodePipeline. This information comes in from a Lambda function that gets called. It is the function that failed in the beginning because the tags were not yet applied. Hope all this now makes sense :-)
If you want to learn more about how to explore this data from here, e.g: see down to method level, exceptions, ... then check out our YouTube Dynatrace Performance Clinic on Basic Diagnositcs with Dynatrace
To simulate a new pipeline run lets go back to our AWS CodePipeline and click on "Release change". This will trigger a new release of the current build. Once the Pipeline reaches the Approval Phases manually aprove it.
Everytime a deployment happens from our Pipeline we should see that information on the service that Dynatrace monitors. Lets go back to one of the services (Staging or Production) and explore the

In a "non automated" world the approver of a build would go off to all sorts of tools, e.g: CodeCoverage, Unit & Functional Test Results, Load Testing Results and Monitoring Tools. In our case we could for instance open up the Dynatrace Dashboards for our Staging service and see how Response Time, Failure Rate and Throughput compares to e.g: current state in production or the timeframe of the previous test. In Dynatrace we could for instance create a chart that compares Staging vs Production Response Time and based on that decide whether to approve the Staging phase:

BUT THAT IS A BORING TASK!! A TASK THAT CAN BE AUTOMATED!!
In our AWS CodePipeline you may have noticed an action called RegisterDynatraceBuildValidation. This action triggers the Lambda function registerDynatraceBuildValidation with the parameters: StagingToProduction,5. These parameters tell our Lambda function to that we want to compare key metrics from Staging vs Production. It also tells it that we dont want to do it right away but start in 5 minutes. Reason for that is because we first want to give the load test the chance to generate some load.
registerDynatraceBuildValidation: This AWS Lambda is actually not doing a whole lot. It is simply putting a "Build Validation Request" in a DynamoDB table with all the information needed to process the request once the timespan, e.g: 5 minutes has passed. If you want go ahead and explorer your DynamoDB table called BuildValidationRequests:
 The key data points in that table are: PipelineName, ComparisonName, Timestamp, Validationtimeframe and Status. In my screenshot you can see that 4 build validation requests. 1 is still waiting for validation. Two are in status OK and one shows status Violation! Violation means that the automated metrics comparison between the two specified environments showed a degradation in performance.
As for status waiting: Waiting means that it is not yet time as the timeframe, e.g: 5 minutes since the request was put into this table has not yet passed!
The key data points in that table are: PipelineName, ComparisonName, Timestamp, Validationtimeframe and Status. In my screenshot you can see that 4 build validation requests. 1 is still waiting for validation. Two are in status OK and one shows status Violation! Violation means that the automated metrics comparison between the two specified environments showed a degradation in performance.
As for status waiting: Waiting means that it is not yet time as the timeframe, e.g: 5 minutes since the request was put into this table has not yet passed!
validateBuildDynatraceWorker: This AWS Lambda is doing all the heavy lifting. It gets triggered via a CloudWatch Rule that calls this function every 2 minutes. The function checks the DynamoDB table and processes those entries that are in status "Waiting" and where "the time is right". The function then looks at the monspec file which contains the definition of environments, comparison configurations as well as metrics. Based on that configuration data the function uses the Dynatrace Timeseries API and pulls in the metrics from the entities and compares them. The result gets put back onto the DynamoDB Item. The monspec column contains all values from the source and the comparison source as well as status information for every compared metric and an overall status. The overall status is also reflected in the Status column.

So - one way to look at the data would be to go back to the DynamoDB table and manually look at the Monspec column. BUT - THAT IS ALSO BORING AND A MANUAL TASK!!
getBuildValidationResults: This brings us to this AWS Lambda function which allows us to query build validation information and get it presented in a "nice" HTML page (I have to admit - I am not a Web Frontend Guru - this is the best I could come up with).
To easier acces this AWS Lambda function, our CloudFormation stack created an API Gateway with a public method. If you go back to your CloudFormation Output you should see one output with the name DynatraceBuildReportEndpoint. It should say something like this: https://abcdefgh.execute-api.us-west-2.amazonaws.com/v1/BuildValidationResults
Go ahead and open it - the report gives you a list of metrics and for every build these metrics got evaluated we see the values from our Source System (e.g: Staging), the Comparison System (e.g: Production), the allowed calculated Threshold and whether the current value Violated the threshold!

Alright. So - we now have automated performance data from our Staging Enviornment that gets automatically compared to our Production environment every time we run a build. We have all this data in DynamoDB and accessible as an HTML report.
Now lets automate the approval of the "Manual Approval" action in our CodePipeline. Our Lambda function validateBuildDynatraceWorker which gets executed via the CloudWatch Rule is not only validating the results and writing it back to DynamoDB. It also checks whether the Pipeline that initiated that build validation request is currently waiting for Manual Approval. If that is the case, and if that Manual Approval WANTS validateBuildDynatraceWorker to approve/reject that phase then the Lambda function will do that as well.
The only configuration we have to do is to mark the "Manual Approval" so that our Lambda functions knows it can approve/reject it. This is done via the Comment field. Here our Lambda function expects the CodePipeline Action Name that initiated the build validation request. In our case that is RegisterDynatraceBuildValidation.
Do do this lets edit our AWS CodePipeline and edit the ManualApproval action in the ApproveStaging stage of our Pipeline: RegisterDynatraceBuildValidation

We can do the same for the Production Approval Stage as we also have a Build Validation Request right after we deploy production. That request validates Production with Production from an hour ago - making sure that nothing that was deployed is worse than before. Here is the configuration of the RegisterProductionValidation action right after we deployed the application in Production. It puts a Build Validation Request into our DynamoDB table to validate Production with ProductionLastHour, 5 minutes into the Production Deployment!

In order to automatically validate the Production Approval Stage we simply do the same thing we did for our Staging approval. We put RegisterProductionValidation into the Comments field:

THATS IT!!! - From now on our pipeline approvals will automatically be accepted or rejected based on Dynatrace Build Validation Results. We can always manually approve these actions BEFORE Dynatrace gets to - but - well - whats the point in automating then? :-) In case Dynatrace Accepts or Rejects the Approval Stage you will find details about it on the Action itself. You also find a link to the report that gives you the historical overview.
Approval Example | Reject Example
 |
| 
Here is the build validation overview report showing how it looks like when one of the build didnt validate successful. Seems in my case the max response time is above the allowed threshold:

TIP: If Dynatrace rejects a build but you still want to push it into the next stage simply "Retry" that approval stage and then manually approve it!
Our Sample app is not just a static app. It actually supportes "different builds" where every build lets the app experience different performance behavior. A great way to test our pipeline. By default the app runs with Build 1. Build number is passed as an environment variable when CodeDeploy launches the app. Check out start_server.sh where we pass the env-variable:
export BUILD_NUMBER=1
We can pass other build numbers. Supported values are 1, 2, 3 and 4. Any other value defaults to 1. Here is a quick overview of how each build behaves:
| Build | Problem |
|---|---|
| 1 | no problem |
| 2 | 50% of requests return HTTP 500 Status Code |
| 3 | back to normal |
| 4 | no problem in staging but problem in prod -> higher sleep time and 10% of requests fail |
Here are my suggestions for your next steps:
-
Try Build 2 and see whether the automated approval for Staging actually rejects the build. It should becuase 50% of requests fail which means that Failure Rate should show a violation as compared to Production. Here is my report output nicely showing the spike in Failure Rate which is why my build was violated!
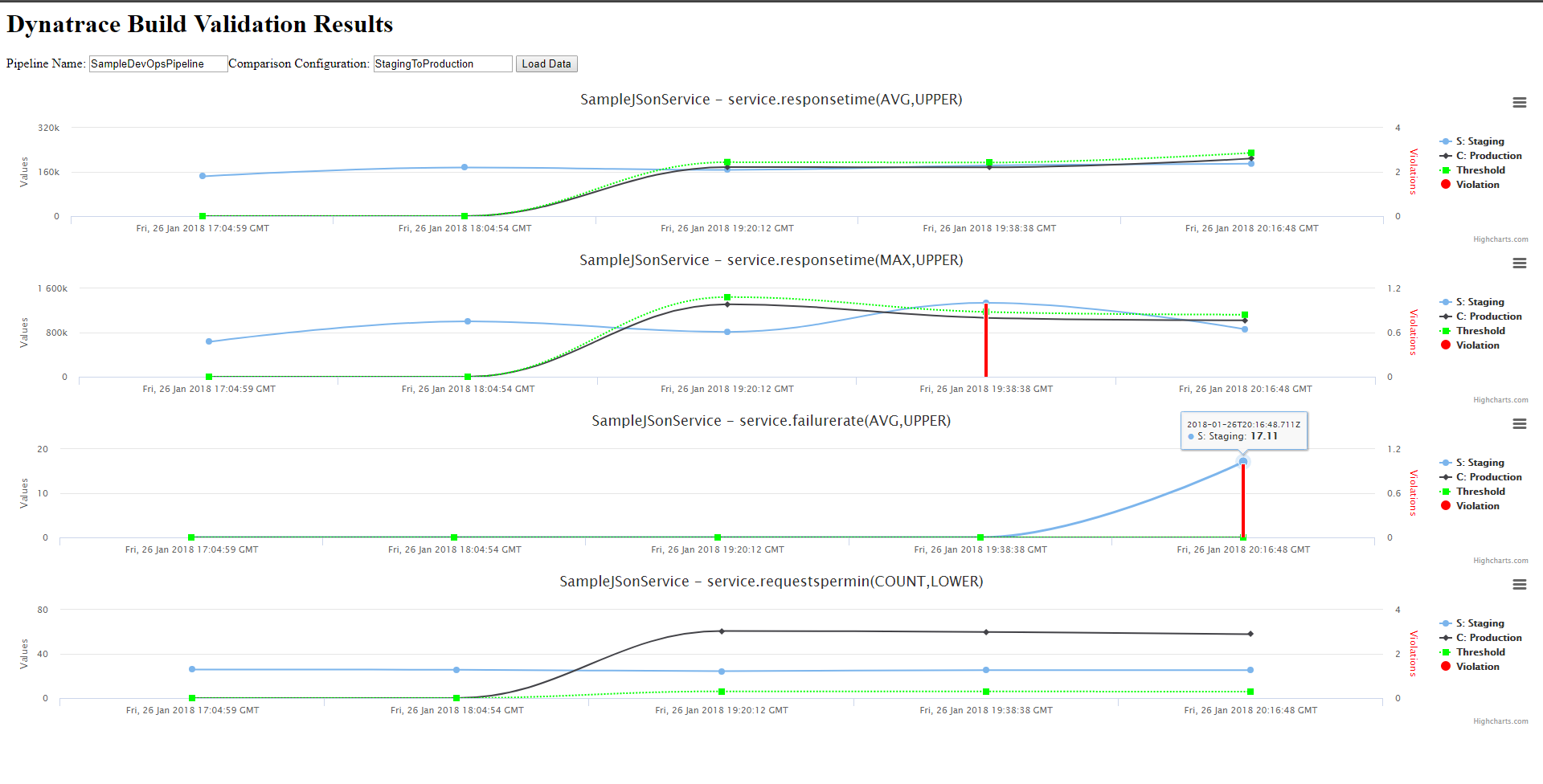
-
Then try Build 3. Everything should be good again and the pipeline should make it all the way to Production
-
Now we can try Build 4. It should make it through Staging as the problem only affects Production Deployments. But we should see Production Approval to fail!
-
Lets go back to Build 1

The GitHub repo contains a directoy called appbuilds_readytodeploy. In this directory you find 4 zip files of the appp. The only difference in each zip file is that the BUILD_NUMBER is set to either 1, 2, 3 or 4. If you want to deploy a build simply take one of these zip files, rename it app.zip and upload it to your S3Bucket where you initially uploaded the app.zip file. Overwrite the existing version. Now go to your AWS CodePipeline and click on "Release Change". Thats it!
Last step in our tutorial is to automate handling a problem in production. Besides doing our Production Approval stage where we compare key metrics against a previous timeframe, Dynatrace provides a much smarter way to detect production problems. Dyntrace baslines every single metric for us, it also keeps an eye on critical log messages, end user behavior and infrastructure issues. In case a problem comes up that impacts our end users or service endpoints a new Problem Ticket gets created. The following ticket is an example if you deploy a bad build. Dyntrace automatically detects that something is wrong with our production service:
 Clicking on the details shows us how and when Dynatrace detected that problem:
Clicking on the details shows us how and when Dynatrace detected that problem:

Everytime a problem ticket is opened Dynatrace can notify external tools, e.g: ServiceNow, PagerDuty, xMatters, JIRA, AWS API Gateways, ... about this problem. For our purposes we can let Dynatrace call an AWS Lambda function that we expose through a public API Gateway. Our CloudFormation Stack already created that endpoint for us. Go back to your CloudFormation Output list and find the link for the output HandleDynatraceProblemEndpoint. It shoudl be something like: https://abcdefgh.execute-api.us-west-2.amazonaws.com/v1/HandleDynatraceProblem
Alerting Profiles
In Dynatrace we can now configure our Problem Notification Integration to always call that endpoint in case a problem is detected. But instead of pushing ALL problems to this endpoint we can configure a so called "Alerting Profile" which allows us to only notify in case certain events happen on certain entities. In our case we only want to push Problems that happen in our Production Environment to this endpoint. In Dynatrace go to Settings - Alerting - Alerting Profiles and lets create a new Profile called ProductionService. In that profile we are only intersted in Error, Slowdown and Custom Alerts for those entities that have the DeploymentGroup:Production tag on it. So - thats our services that are deployed by CodeDeploy and where that environment variable is passed:

Problem Notification with AWS Lambda
No that we have our Alerting Profile we can go ahead and actually setup the integration. In Dynatrace go to Settings - Integration - Problem notification. Click on "Set up notifications" and select "Custom Integration".
Configure your integration as shown in the next screenshot. Give it a meaningful name. Then put in your HandleDynatraceProblem endpoint and click on Test Notification to test it out:

AND THATS IT - seriously! :-)
Now - what is this AWS Lambda function actual doing? handleDynatraceProblemNotification: This lambda functions queries the Dynatrace Problem REST API to capture more data about the impacted entities. In case the Problem was detected on an Entity where an AWS CodeDeploy Deployment was logged as a Deployment Event the function will figure out the previous AWS CodeDeploy Revision and initiate a deployment of that revision. This should then bring the system back into its previous state!
Here is a Problem with a comment from the Lambda function indicating that a previous revision was deployed:

If you want to learn more about Self-Healing and Auto-Remediation I suggest you check out some of our material online. Deploying a previous revision is obviously just one easy remediation action. We could query the Dynatrace Timeseries API to figure out what else is going on in the system and e.g: scale up EC2 instances in case of traffic peaks or stop/promote BLUE/GREEN deployments in case we detect problems with one or the other version:
- Blog: Auto-Mitigation with Dynatrace AI – or shall we call it Self-Healing?
- YouTube Self-Healing Demo with our Lab Team: Auto-Scaling and Restarting Sevices
- Blog: Top Problems Detected and how to Auto-Mitigate them
There are a couple of additional things we can do to make this even better
While Dynatrace automatically detects our services and gives them a proper name we end up having the same service name multiple timese - one per environment. In order to get better default naming we can create a so called "Service naming rule". In the Dynatrace Web UI go to Settings -> Service naming rules and create a new custom rule just as I have done here:

Here is how I configured my name rule: Name: Services by Deployment Group Name Name Format: {ProcessGroup:Environment:DEPLOYMENT_GROUP_NAME}/{Service:DetectedName} Condition: DEPLOYMENT_GROUP_NAME(Environment)
This will result in better to understand service names as the name will include the Deployment Group (Staging Production) as well as the default detected name. In our case we will therefore get services with the names: Production/SampleNodeJsService and Staging/SampleNodeJsService
Dynatrace OneAgent automatically monitors all important log files. Dynatrace automatically detects critical or severe log messages written to these files but we can also define our own custom Log Monitoring Rules which will then automatically create an event on the Entity (Process, Host) that creates that log message. Our application is mainly logging informational entries, e.g: when another 100 requests are processed. But there are two important log messages the app is writing in case somebody
- Forces a critical error by invoking the url /api/causeerror
- Changes the build number by invoking the url /api/buildnumber?newBuildNumber=X
In the first case the app logs a SEVERE log message. In the latter it logs a WARNING. We can see these log messages by opening up the log file.
In Dynatrace Web UI open the Service Details view for your Staging or Production Service. Now navigate to the NodeJS process that actually runs that service. You should see a screenshot like this and you should find the section about monitored log files:

Click on the serviceoutput.log entry which brings you to the Log Monitoring Feature. Click on "Display Log" and you will see all the log messages that came in in the selected timeframe:

If you dont see the error log yet go back to your browser and execute the /api/causeerror on your staging or production instance. Then refresh that log view until you see the log entry coming in.
The Log viewer also allows us to define a filter, e.g: lets filter on "sombody called /api/causerror". You can actually click in the bottom log entry view and the UI will give you an option to start defining these filters based on real log entries. This is what you should see then:

If we have a filter that we are really interested in we can go a step further. We can click on "Define event" which brings us to our Custom Log Event configuration - already pre-populated with our pattern. What we want to do here is to give it a name, select generate "Log Error Problem" and change the occurences to higher than 0 per min. That will force Dynatrace to immediately open a Problem Ticket if one of these error logs is detected. If we want Dynatrace to not only monitor the Staging or Production system but actually both you can adjust the log file filter on the bottom of the screen. Here you can select all log files that Dynatrace should monitor for that log pattern:

Click save. Now go back to your app and start executing another /api/causeerror. What will happen now is that Dynatrace detects that a log entry matches our filter and it will then automatically open a Problem Ticket. Here is how it looks like in my environment!

Now - creating a Problem Ticket for every time we see this log message might not be what you want. But you see now what is possible. Instead of opening a ticket Dynatrace can also just create an Event on the entity. Similar to our Deployment Event when CodePipelins pushes a Deployment out - we can have Dynatrace create an event based on observed log messages!
One aspect we havent discussed in more detail is the actual configuration that tells our lambda functions which Dynatrace Entities to query, which metrics and timeframes to compare. This configuration is all stored in "monspec.json". A json file that our Pipeline defines as an Input Artifact. The idea behind this configuration file is that a developer of a service can define the following things
- How to identify that service in the different environments
- How to compare that service between environments
- Which metrics to compare and whether it is a 1:1 comparison or whether a special baseline factor should be applied
Check out the monspec file that is part of this tutorial. We added some comments to the fields to explain what these fields are!
Here are several snippets of this monspec file that should explain how it works: *** 1: Defining how to identify this entity in the different environments leveraging Dynatrace Tags ***
"SampleJSonService" : {
"etype": "SERVICE", // Allowed are SERVICE, APPLICATION, HOST, PROCESS_GROUP_INSTANCE
"environments" : {
"Staging" : { // This service in Staging is identified through the DeploymentGroup:Staging Tag
"tags" : [
{
"context": "CONTEXTLESS",
"key": "DeploymentGroup",
"value": "Staging"
}
]
},
"Production" : { // This service in Production is identified through the DeploymentGroup:Production Tag
"tags" : [
{
"context": "CONTEXTLESS",
"key": "DeploymentGroup",
"value": "Production"
}
]
}
},
*** 2: Defining different comparision options, e.g: Staging with Prod, Staging with Staging Yesterday, ... ***
"comparisons" : [
{
"name" : "StagingToProduction", // Compare Staging with Production
"source" : "Staging",
"compare" : "Production",
"scalefactorperc" : {
"default": 15, // Allow Staging Values to be 15% OFF on average than Production
"com.dynatrace.builtin:service.requestspermin" : 90 // Except requestpermin. Here Staging can be 90& OFF, e.g: when Staging only executes a fraction of the load frrom prod
},
"shiftcomparetimeframe" : 0,
"shiftsourcetimeframe" : 0,
},
{
"name" : "StagingToProductionYesterday",
"source" : "Staging",
"compare" : "Production",
"scalefactorperc" : {
"default": 15,
"com.dynatrace.builtin:service.requestspermin" : 90
},
"shiftsourcetimeframe" : 0,
"shiftcomparetimeframe" : 86400 // Timeshift allows us to compare different timeframes
},
{
"name" : "StagingToStagingLastHour", // we can also compare the same environments - just a differnt timeframe. Good for Continuous Performance Environments
"source" : "Staging",
"compare" : "Staging",
"scalefactorperc" : { "default": 10},
"shiftsourcetimeframe" : 0,
"shiftcomparetimeframe" : 3600
}
*** 3. Define our Performance Signatures: Which Metrics to Compare using a Static or Dynamic Threshold ***
"perfsignature" : [
{ // We want to compare AVG Response Time and make sure the upper limit doesnt cross the Comparison Source (including the ScaleFactor bandwidth)
"timeseries" : "com.dynatrace.builtin:service.responsetime",
"aggregate" : "avg",
"validate" : "upper",
"_upperlimit" : 100, // Optionally you can define hard coded limits
"_lowerlimit" : 50,
},
{
"timeseries" : "com.dynatrace.builtin:service.responsetime",
"aggregate" : "max"
},
{
"timeseries" : "com.dynatrace.builtin:service.failurerate",
"aggregate" : "avg"
},
{
"timeseries" : "com.dynatrace.builtin:service.requestspermin",
"aggregate" : "count", // for aggregation we allow min, max, avg, sum, count and median
"validate" : "lower" // validate defines whether we validate upper or lower boundaries!
}
]
I hope you enjoyed that tutorial and you saw the value of adding Dynatrace into your DevOps Pipeline. We discussed a couple of concepts on how to leverage the Automation API, Automated Tagging and Baselining to implement concepts such as Shift-Left and Self-Healing. There is more that can be done. If you want to learn more check out my YouTube Channel on Dyntrace FullStack Performance Clinics If you have any further questions dont hesitate to ask!