This repository provides code to replicate the paper
Sanity Checks for Saliency Maps by
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, & Been Kim.

Saliency methods have emerged as a popular tool to highlight features in an input deemed relevant for the prediction of a learned model. Several saliency methods have been proposed, often guided by visual appeal on image data. In this work, we propose an actionable methodology to evaluate what kinds of explanations a given method can and cannot provide. We find that reliance, solely, on visual assessment can be misleading. Through extensive experiments we show that some existing saliency methods are independent both of the model and of the data generating process. Consequently, methods that fail the proposed tests are inadequate for tasks that are sensitive to either data or model, such as, finding outliers in the data, explaining the relationship between inputs and outputs that the model learned, or debugging the model. We interpret our findings through an analogy with edge detection in images, a technique that requires neither training data nor model. Theory in the case of a linear model and a single-layer convolutional neural network supports our experimental findings.
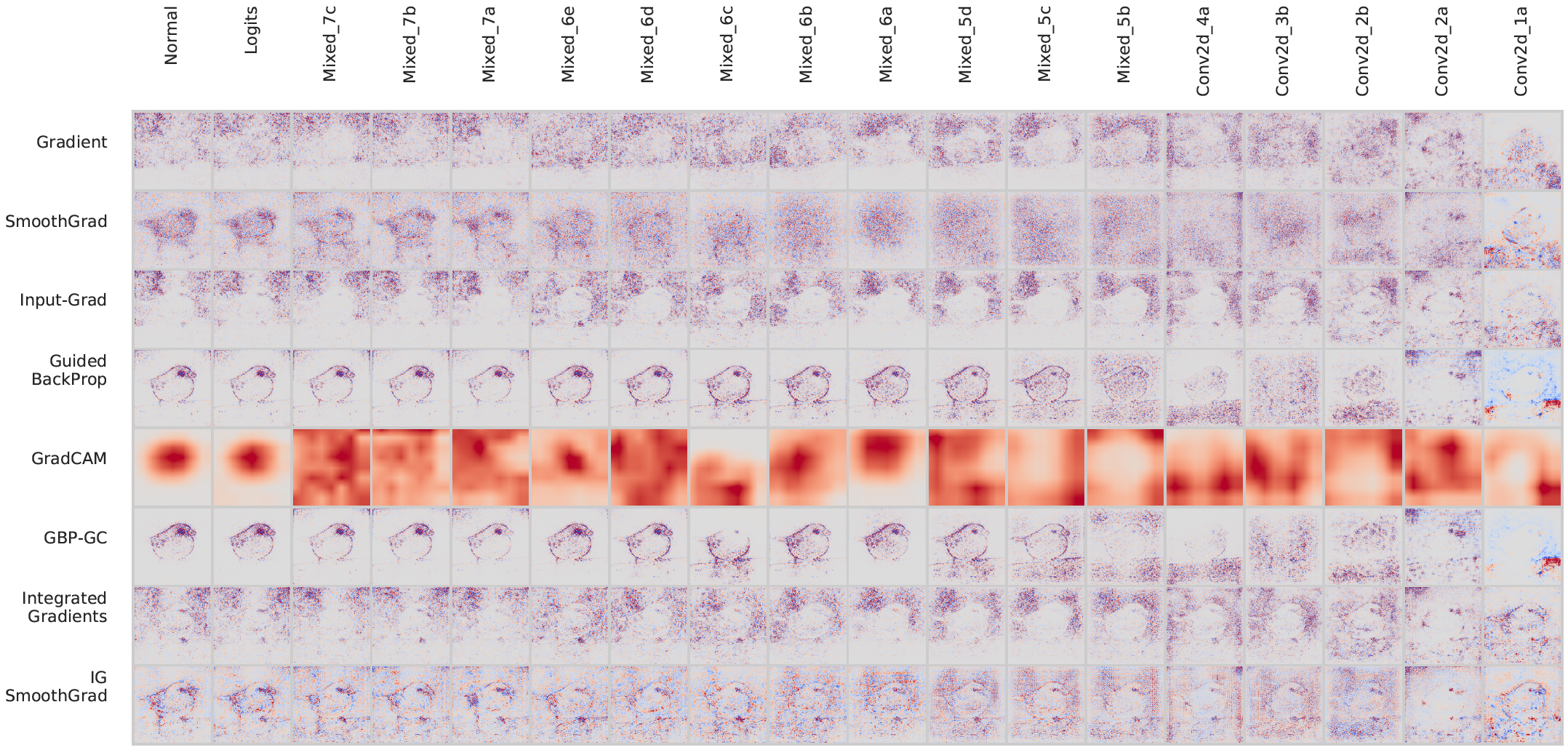
For the model randomization test, we randomize the weights of a model starting from the top layer, successively, all the way to the bottom layer. This procedure destroys the learned weights from the top layers to the bottom ones. We compare the resulting explanation from a network with random weights to the one obtained with the model’s original weights. Below we show the evolution of saliency masks from different methods for a demo image from the ImageNet dataset and the Inception v3 model.
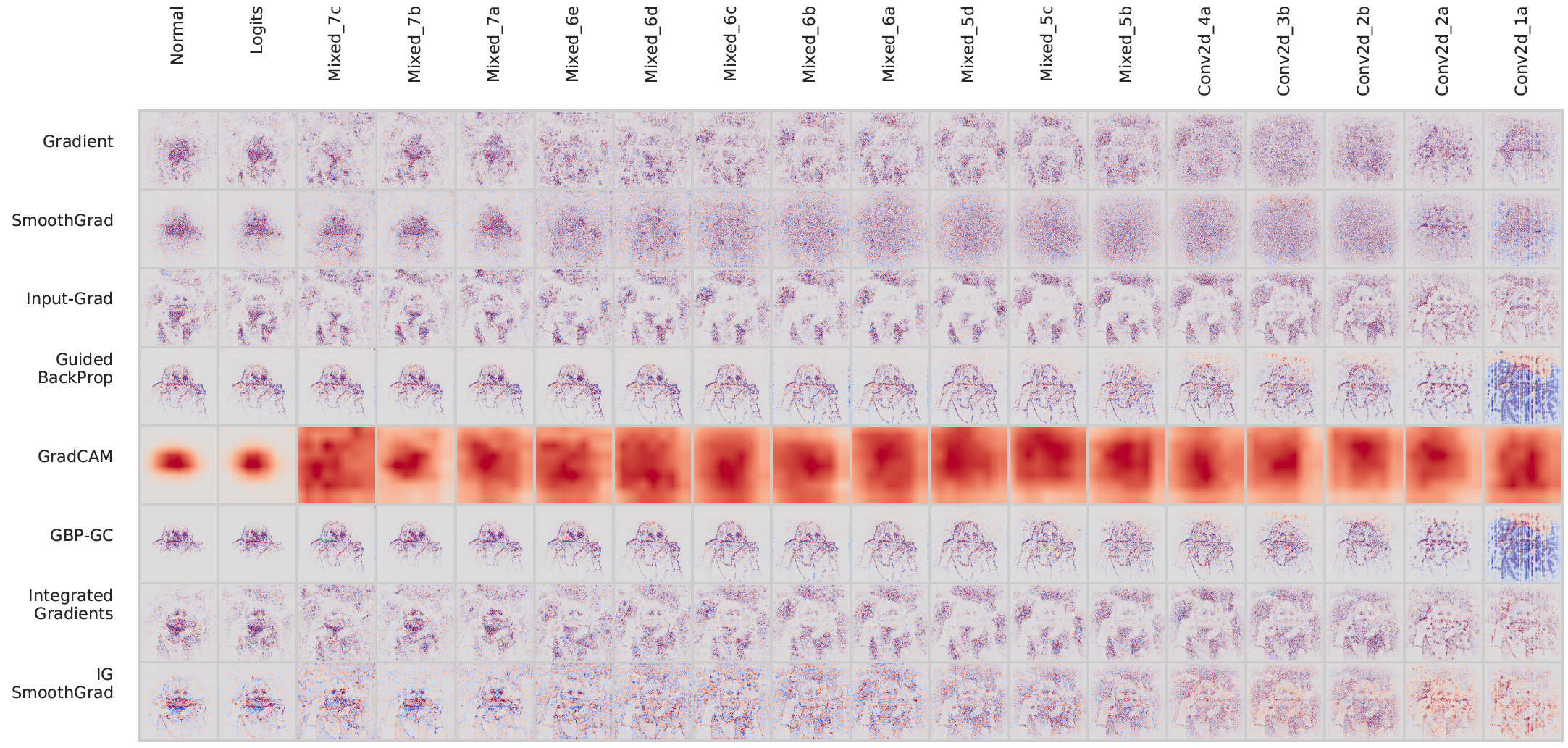
Here we show the results of randomizing each 'layer/block' at a time while keeping the other weights set at the pre-trained (original) values.
In our data randomization test, we permute the training labels and train a model on the randomized training data. A model achieving high training accuracy on the randomized training data is forced to memorize the randomized labels without being able to exploit the original structure in the data. We now compare saliency masks for a model trained on random labels and one trained true labels. We present examples below on MNIST and Fashion MNIST.
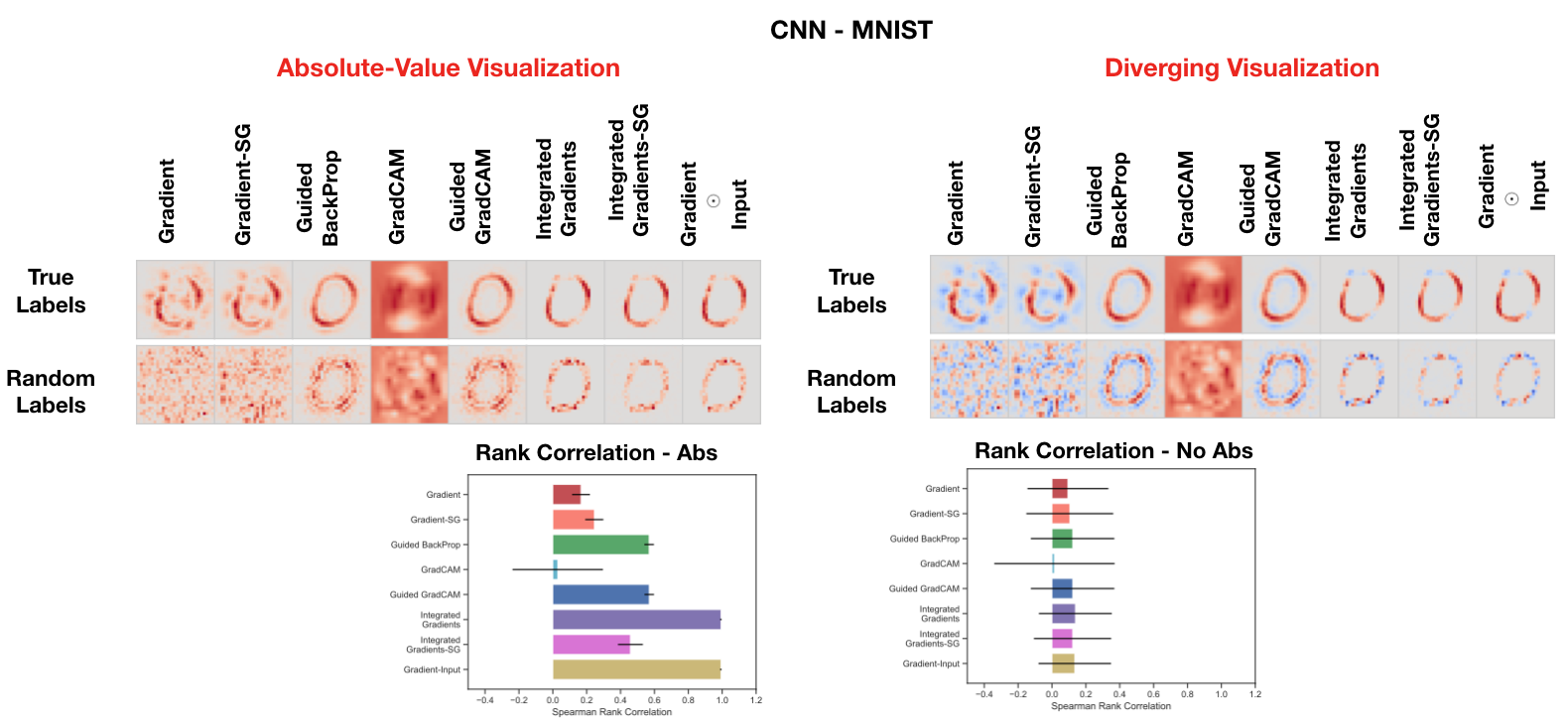
See the paper and appendix for additional figures and results on the data randomization test.
A previous version of the paper said that Guided Backprop was completely invariant to model randomization (weight re-initialization); however, this is not the case. Guided Backprop is still invariant to higher layer weights of a DNN, but it is not completely invariant. As we show in the figure below, when the lower layers are randomized, there is indeed a distortion to the mask. However, we still observe that there is high visual similarity between the mask derived from a completely reinitialized model and the input. Overall, the findings in the paper remain unchanged. We have recently updated the arxiv version as well. See the inceptionv3_guidedbackprop_demo.ipynb in the notebook folder for replication.

See /doc/data/ for the demo images and the ImageNet image ids used in this work.
We have added scripts for training simple MLPs and CNNs on MNIST. To run any of the MNIST notebooks, use these scripts to quickly train either an MLP on MNIST (or Fashion MNIST) or a CNN on MNIST (or Fashion MNIST). The scripts are relatively straight forward. To run the inception v3 notebooks, you will also need to grab pre-trained weights and put them models folder as described in the instructions below.
We use the saliency python package to obtain saliency masks. Please see that package for a quick overview. Overall, this replication is mostly for illustration purposes. There are now other packages in PyTorch that provide similar capabilities.
You can use the instructions below to setup an environment with the right dependencies.
python3.5 -m venv pathtovirtualvenv
source pathtovirtualvenv/bin/activate
pip install -r requirements.txt
You can train a CNN on MNIST using src/train_cnn_models.py as follows:
python train_cnn_models.py --data mnist --savemodelpath ../models/ --reg --log
You can toggle the data with the --data option. You can also train MLPs with an analogous command:
python train_mlp_models.py --data mnist --savemodelpath ../models/ --reg --log
To run the CNN and MLP on MNIST notebooks, you will need to train quick models with the commands above.
To run any of the incetion_v3 notebooks, you will need inception pretrained weights. These are available from tensorflow. Alternatively, the weights can be obtained and decompressed as follows:
wget http://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz
tar -xvzf inception_v3_2016_08_28.tar.gz
At the end of this, you should have the file inception_v3.ckpt in the folder models/inceptionv3. With this, you can run the inception notebooks.
In the notebook folder, you will find replication of the key experiments in the paper. Here is a quick summary of the notebooks provided:
-
cnn_mnist_cascading_randomization.ipynb: shows the cascading randomization on a CNN trained on MNIST.
-
cnn_mnist_independent_randomization.ipynb: shows the independent randomization on a CNN trained on MNIST.
-
inceptionv3_cascading_randomization.ipynb: shows the cascading randomization on an Inception v3 model trained on ImageNet for a single bird image. We also show how to compute similarity metrics. This notebook replicates Figure 2. from the paper.
-
inceptionv3_independent_randomization.ipynb: shows a quick overview of the independent randomization for inception_v3.
-
inception_v3_guidedbackprop_demo.ipynb: deeper dive into guided backprop with cascading randomization.