Image Captioning
Requeriments
- anaconda/anaconda-natigator
- 3D video card (i.e. GeForce GTX 1060 or higher)
Used datasets & world embeddings
- Datasets
- Flickr 8k
- Flickr 30k
- Word embedings
- Glove word embedding
- glove.6B
- glove.840B.300d
- Elmo embedding
- Glove word embedding
Setup environment
Step 1: Create project environment.
$ conda env create --file environment.ymlStep 2: Activate environment.
$ conda activate image-captioningPrepare dataset
Step 1: Download & prepare word embeddings to use:
$ ./setup_word_embedingsStep 2: Download Flickr8K dataset .torrent from this.
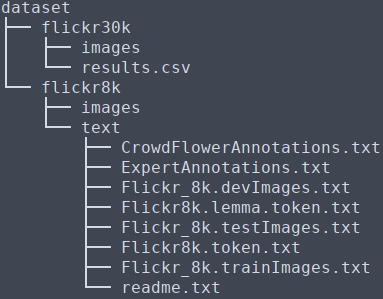
Step 3: Once downloaded the Flickr directory, make dataset directory under project path and copy downloaded directory to this.
$ mkdir -p dataset
$ cp -rf ~/Downloads/Flickr8k ~/project/dataset/flickr8kStep 4: Login an download Flickr30k dataset from kaggle.
Step 5: Copy downloaded file to project/dataset path and unzip this.
$ cp -rf ~/Downloads/flickr30k_images.zip ~/project/dataset/
$ cd ~/project/dataset
$ unzip flickr30k_images.zipStep 6: Finally change dataset directory structure like this.
Train/Test model
You can train, test and adjust model from Image captioning notebook.
Word embeddings
Word embedding use examples: word_embedding_examples.