- Introduce web scraping and its usages.
- Learn how to use Nokogiri to scrape data from an HTML document.
Web scraping is the act of parsing a web page's HTML and pulling, or "scraping" pertinent data from that HTML. In this reading, we'll take a brief look at what scraping is and how to accomplish it.
A more thorough code-along is coming up next, but if you would like to follow
along, lib/scraper.lib is provided for you.
As we established above, scraping is a technique used to grab data out of the HTML that makes up a web page. Scraping can be difficult to accomplish––in order to get the data we want, we need to closely examine the HTML and identify exactly which elements contain the information we're interested in. It requires a high degree of precision.
So, if scraping is so tricky, why do we use it? Well, not all of the data we might be interested in using to program is available to use through APIs. For example, let's say we're creating an app that catalogs popular musicians and searches the web for their upcoming concerts. A quick Google search will reveal that, unfortunately for us, there isn't a "Popular Musician" API out there just waiting to be used. There is, however, a very comprehensive list of musicians on the Billboard website. In such a scenario, you may want to programmatically grab every musician's name from the Billboard list and store those artists in your own database.
Here's another example: let's say you're creating an app that allows a user to subscribe to a news feed. You anticipate that your users are super-tech savvy and might be interested in subscribing to some lesser-known tech news sites. Such sites may not have an API that makes their articles available to you. Instead, you would have to scrape those sites for their latest news articles and send those newest articles to your users.
These are just a few examples of situations in which scraping might come in handy. Now that we have a few use-cases that illustrate the utility of scraping, let's talk about how to scrape.
Open-URI is a module in Ruby that allows us to programmatically make HTTP
requests. It gives us a bunch of useful methods to make different types of
requests, but for this guide, we're interested in only one: open. This method
takes one argument, a URL, and will return to us the HTML content of that URL.
In other words, running:
html = open('http://www.google.com')stores the HTML of Google into a variable, html. (More specifically, it
actually stores the HTML in a temporary file that we can then call read on to
get the raw HTML. We won't worry about that here though.)
Nokogiri is a Ruby gem that helps us to parse HTML and collect data from it. It allows us to treat a huge string of HTML as if it were a series of nested objects that you can use to extract the desired information using provided methods. Put simply, Nokogiri takes in HTML and spits out a collection of objects we can get information from.

The HTML that would normally be rendered as a webpage can be scraped with Nokogiri into a many small pieces. Nokogiri makes the level of precision required to extract the necessary data much easier to attain. It works like a fine-toothed saw to scrape only the necessary data. In fact, that's what "nokogiri" means: a fine-toothed saw.

Let's get Nokogiri up and running and look at a very basic example of its usage. Then, we'll move on to the next lesson, where you'll try it out for yourself.
Installing Nokogiri is as easy as gem install nokogiri. If you run into any
issues with this, check out the following documentation:
Nokogiri Installation Guide.
Let's say we have a file, scraper.rb which is responsible for (you guessed it)
scraping. We need to require Nokogiri and open-uri:
require 'nokogiri'
require 'open-uri'
# more code coming soon!We can use the following line to grab the HTML that makes up the Flatiron School's landing page at flatironschool.com:
html = open("https://flatironschool.com/")Next, we'll use the Nokogiri::HTML method to take the string of HTML returned
by open-uri's open method and convert it into a NodeSet (aka, a bunch of
nested "nodes") that we can easily play around with.
Nokogiri::HTML(html)Let's save the HTML document in a variable, doc that we can then operate on:
doc = Nokogiri::HTML(html)If we were to puts out doc right now, we'd see something like this in our
terminal:
<!DOCTYPE html>
<html lang="en" class="gr__flatironschool_com" data-react-helmet="lang">
<head>
<meta charset="utf-8">
<meta http-equiv="x-ua-compatible" content="ie=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta name="google-site-verification" content="X--Dsxcv97NzPomhlz80wswUgUOF8iMxYhmaY-qNHFY">
<link rel="preload" href="https://fonts.gstatic.com/s/roboto/v18/KFOlCnqEu92Fr1MmWUlfBBc4AMP6lQ.woff2" as="font" type="font/woff2" crossorigin="anonymous">
<link rel="preload" href="https://fonts.gstatic.com/s/roboto/v18/KFOlCnqEu92Fr1MmSU5fBBc4AMP6lQ.woff2" as="font" type="font/woff2" crossorigin="anonymous">
<link rel="preload" href="https://fonts.gstatic.com/s/roboto/v18/KFOmCnqEu92Fr1Mu4mxKKTU1Kg.woff2" as="font" type="font/woff2" crossorigin="anonymous">
<link rel="preload" href="https://fonts.gstatic.com/s/roboto/v18/KFOlCnqEu92Fr1MmEU9fBBc4AMP6lQ.woff2" as="font" type="font/woff2" crossorigin="anonymous">
<link rel="preload" href="https://fonts.gstatic.com/s/roboto/v18/KFOkCnqEu92Fr1Mu51xIIzIXKMny.woff2" as="font" type="font/woff2" crossorigin="anonymous">
<script type="text/javascript" async="" src="https://widget.intercom.io/widget/j4d6dyie"></script>
<script src="https://connect.facebook.net/signals/plugins/inferredEvents.js?v=2.9.4" async=""></script>
<script src="https://connect.facebook.net/signals/config/1706055166302798?v=2.9.4&r=stable" async=""></script>
<script async="" src="https://connect.facebook.net/en_US/fbevents.js"></script>
<script type="text/javascript" async="" src="https://www.google-analytics.com/analytics.js"></script>
<script type="text/javascript" async="" src="https://www.google-analytics.com/plugins/ua/linkid.js"></script>
<script src="//js.hs-analytics.net/analytics/1568493600000/69751.js" type="text/javascript" id="hs-analytics"></script>
<script src="https://js.hsadspixel.net/fb.js" type="text/javascript" id="hs-ads-pixel-69751" data-ads-portal-id="69751" data-ads-env="prod" data-loader="hs-scriptloader" data-hsjs-portal="69751" data-hsjs-env="prod"></script>
...If you look through further, you can find the body with lots of content.
<body data-gr-c-s-loaded="true">
<div id="pull-down" class="hb-50 hellobar hb-bottom-right se-714205 inverted" style="background-color: rgb(255, 255, 255);">
<div class="hellobar-arrow">
<svg xmlns="http://www.w3.org/2000/svg" width="11px" height="11px" viewBox="43.6 92.5 315 315"><path d="M49.6 92.5c-3.3 0-6 2.7-6 6v303c0 3.3 2.7 6 6 6h303c3.3 0 6-2.7 6-6v-303c0-3.3-2.7-6-6-6H49.6zM229.6 254.3c-3.3 0-6 2.7-6 6V360c0 3.3-2.7 6-6 6h-33c-3.3 0-6-2.7-6-6v-99.7c0-3.3-2.7-6-6-6H99.2c-3.3 0-4.2-2-2-4.5l99.9-111.4c2.2-2.5 5.8-2.5 8 0l99.9 111.4c2.2 2.5 1.3 4.5-2 4.5H229.6z"></path></svg>
</div>
</div>
<iframe src="about:blank" id="o8689c8c25e49f24d1d4bd1d49101d50041f42abc-container" class="HB-Slider hb-animated azuki hb-bottom-right" name="o8689c8c25e49f24d1d4bd1d49101d50041f42abc-container-0" style="display: none;"></iframe>
<noscript>
<iframe src="https://www.googletagmanager.com/ns.html?id=GTM-KZZ9JB" height="0" width="0" style="display: none; visibility: hidden"></iframe>
</noscript>
<noscript id="gatsby-noscript">This app works best with JavaScript enabled.</noscript>
<div id="___gatsby">
<div style="outline:none" tabindex="-1" role="group" id="gatsby-focus-wrapper">
<header class="siteHeader-2Zios8 blue-2siWYz normal-1mR2Ud" name="site-header">
<picture>
<source type="image/webp" media="(min-width: 1920px)" srcset="https://images.ctfassets.net/hkpf2qd2vxgx/6uCU1D03JXktRj8kwW7Nip/a2572151bf67c3552d88139ee0299ef2/homepage-hero.jpg?fm=webp&q=85&w=1920,
https://images.ctfassets.net/hkpf2qd2vxgx/6uCU1D03JXktRj8kwW7Nip/a2572151bf67c3552d88139ee0299ef2/homepage-hero.jpg?fm=webp&q=40&w=3840 2x">
<source type="image/jpeg" media="(min-width: 1920px)" srcset="https://images.ctfassets.net/hkpf2qd2vxgx/6uCU1D03JXktRj8kwW7Nip/a2572151bf67c3552d88139ee0299ef2/homepage-hero.jpg?fl=progressive&fm=jpg&q=85&w=1920,
https://images.ctfassets.net/hkpf2qd2vxgx/6uCU1D03JXktRj8kwW7Nip/a2572151bf67c3552d88139ee0299ef2/homepage-hero.jpg?fl=progressive&fm=jpg&q=40&w=3840 2x">
<source type="image/webp" media="(min-width: 1280px)" srcset="https://images.ctfassets.net/hkpf2qd2vxgx/6uCU1D03JXktRj8kwW7Nip/a2572151bf67c3552d88139ee0299ef2/homepage-hero.jpg?fm=webp&q=85&w=1280,
https://images.ctfassets.net/hkpf2qd2vxgx/6uCU1D03JXktRj8kwW7Nip/a2572151bf67c3552d88139ee0299ef2/homepage-hero.jpg?fm=webp&q=40&w=2560 2x">
...On and on. It is a lot to go through, and it can also look pretty messy and difficult to read. But don't worry! Nokogiri will help us parse this. What we're looking at here is all of the HTML that makes up the web page found at www.flatironschool.com. The massive lines above are actually a snapshot of that HTML converted into a structure of nested nodes by Nokogiri.
Nested nodes refers to any tree of elements in which parent elements branch off
to contain children elements. In fact, we've seen similarly nested structures
before when we dealt with nested data structures like hashes. By creating a
nested structure, Nokogiri allows us to do things like iterate over a collection
of elements from the HTML document and use brackets,[], and dot notation to
access elements within the nested structure.
Note: For this reading, we'll be using the Flatiron School website. However, how you scrape a page is very specific to the content of the page you are trying to scrape. That means that if the webpage you wrote certain scraping code for ever changes, your scraping code will likely no longer work correctly. So, the Flatiron School website that this reading refers to may have changed! Some of the examples here may specific to an earlier version of the site and won't work look or work exactly as shown when you try them out on your own. That's okay though. Just follow along with the reading and, if you want to try it out, feel free to use the examples provided to guide you in scraping content that is present on the page.
Visit this Flatiron School link and use your browser's developer tools to inspect the page. (You can just right-click anywhere on the page and select "inspect element".)
You should see something like this:
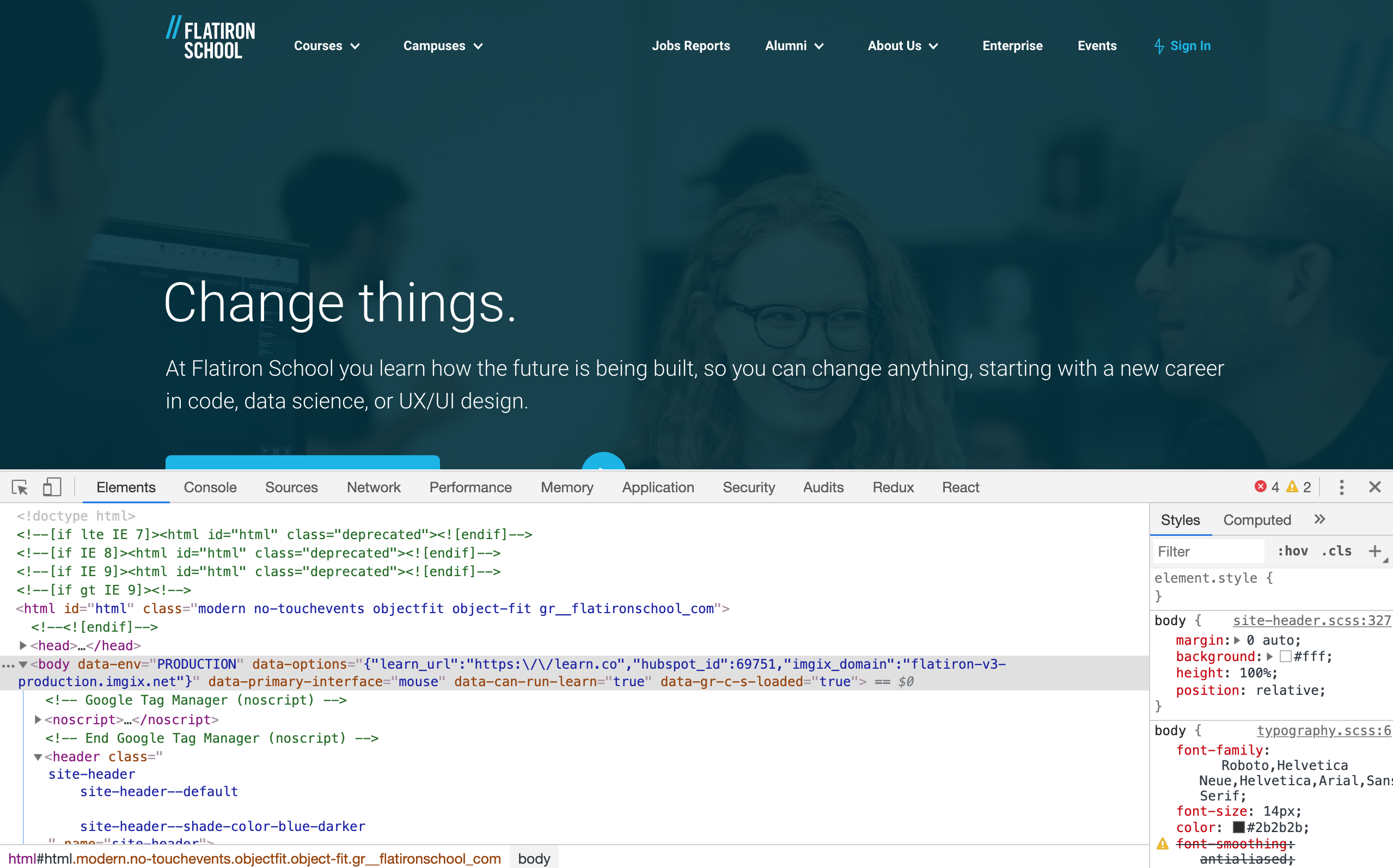
The element inspector view on the bottom half of the page is revealing all of
the page's HTML to us! In fact, the HTML it is showing us is exactly the same
as the HTML put out to our terminal with the help of Nokogiri and open-uri.
Now that we understand what Nokogiri is and have seen how it opens the HTML that makes up a web page, let's look at how we use it to actually scrape information.
Nokogiri allows you to use CSS selectors in order to retrieve specific pieces of information out of an HTML document.
In the following code:
<div id="my-div">
<p class="my-paragraph"></p>
</div>The id and class attributes of the HTML elements are the CSS selectors. You
would refer to the div with this selector: #my-div (using the # to indicate
id), and the paragraph with this selector: .my-paragraph (using the . to
indicate class).
Nokogiri's .css method can be called on the doc variable that we set equal
to that giant string of HTML that Nokogiri retrieved for us. The .css method
takes in an argument of the CSS selector you want to retrieve. Let's take a
look.
How do we determine which selector to use to retrieve the desired information? Remember that the HTML document that Nokogiri retrieved for us to operate on is exactly the same HTML that makes up the web page. Let's go back to "www.flatironschool.com" and use the element inspector to find the selector of a certain piece of our HTML. In this case, we'll look the element containing the text 'Change things':
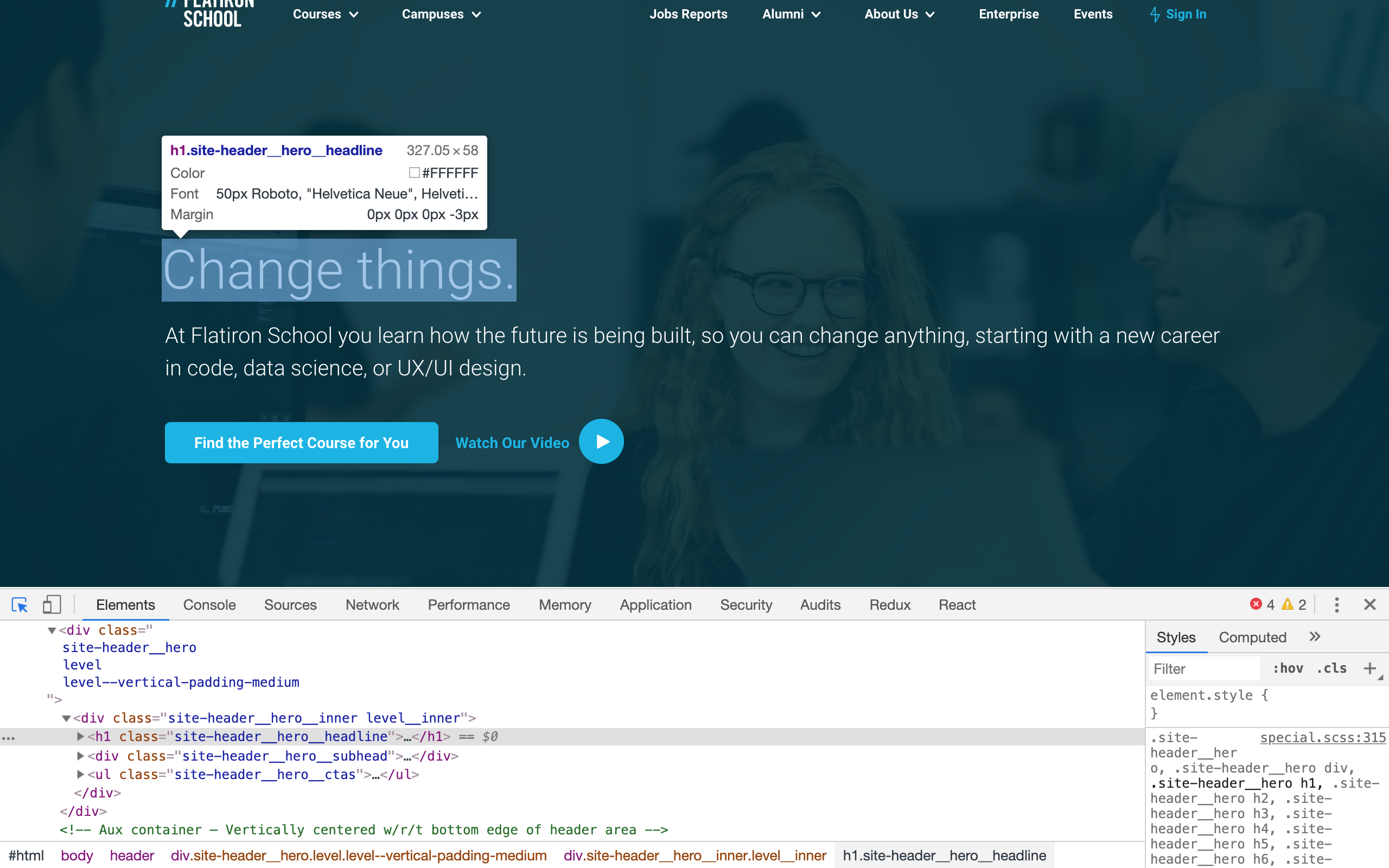
In order to identify the CSS selector, click the button in the upper left corner of the console pane that looks like a mouse icon partially in a box.
Once activated, hover over the 'Change things' text. This will highlight its HTML element for us. Notice that:
<h1 class="headline-26OIBN">...</h1>is highlighted in the above image. If you click on the carrot at the left end of that line, it will open up to show you what that element contains (with lots of spacing around it):
"Change things."We found it! That text lives in a span whose class is "headline-26OIBN". Now we're
ready to use the .css method to grab the text we want:
In our scraper.rb file, we had the following code:
require 'nokogiri'
require 'open-uri'
doc = Nokogiri::HTML(open("https://flatironschool.com/"))Let's call .css on doc and give it the argument of our CSS selector:
require 'nokogiri'
require 'open-uri'
doc = Nokogiri::HTML(open("https://flatironschool.com/"))
doc.css(".headline-26OIBN")If we were to copy and paste the above code into IRB, the last line would return something like:
[#<Nokogiri::XML::Element:0x3fdb39ac8380 name="h1" attributes=[#<Nokogiri::XML::Attr:0x3fdb39ac86dc name="class" value="headline-26OIBN">] children=[#<Nokogiri::XML::Text:0x3fdb39ac5d60 "Change things.">]>]
Although dense, it is possible to figure some things out. First of all,
doc.css(".headline-26OIBN") returned what looks like an Array
containing one Nokogiri object. In actuality, this 'Array' is also a special
Nokogiri object, but works very much like an Array. If you look closely at the
object contained within it, you'll see that it has the 'Change things' text towards the end! To
get it out, we can call .text:
doc.css(".headline-26OIBN").textUsing .text allows us to access text content inside an element scraped by Nokogiri. Run in IRB, we'd see something like this returned:
=> "Change things."Aside: In general adding
.stripto the end will allow us to clean up the extra whitespace and simply return the text contained inside the element.
An interesting thing to note: If you're coding along in the provided
lib/scraper.rb file, using puts or print on doc.css will cause the HTML
elements to print out.
puts doc.css(".headline-26OIBN")Will print out:
<h1 class="headline-26OIBN">Change things.</h1>However, just as before, we can just add .text (and .strip) and get only the
text contained inside the element that we want. Alternatively, using p will
produce the array-like object we saw from before.
We did it! We used Nokogiri to get the HTML of a web page. We used the element
inspector in the browser to ID the CSS selector of the data we wanted to scrape.
We used the .css Nokogiri method, along with that CSS selector, to grab the
element that contains our desired data. Finally, we used the .text method to
retrieve the desired text.
Sometimes we want to get a collection of the same elements, so we can iterate over them. For instance, a little further down the page are some of the courses offered by Flatiron School. We can practice iterating by trying to scrape the titles of all courses from these elements.

This time, if we hover over one of the elements containing a course, we'll see
there are two classes assigned, inlineMobileLeft-2Yo002, and imageTextBlockGrid3-2XAK6G. Since CSS classes are often shared, we'll use all two to
try and get only the content we need:
require 'nokogiri'
require 'open-uri'
html = open("https://flatironschool.com/")
doc = Nokogiri::HTML(html)
doc.css(".inlineMobileLeft-2Yo002.imageTextBlockGrid3-2XAK6G")Notice that each class is listed without spaces! To make sure we only select the three courses in this section and not also other elements that might share the same class name, we will increase the
specificityof our CSS selector. In order to make our selector morestrict, we'll target the correct section first and then the elements containing a course.
This section has the id 2a778efd-1685-5ec6-9e5a-0843d6a88b7b, and adding that to the final selector will produce: .css("#2a778efd-1685-5ec6-9e5a-0843d6a88b7b .inlineMobileLeft-2Yo002.imageTextBlockGrid3-2XAK6G").
Even though the Nokogiri gem returns a Nokogiri::XML::NodeSet (which looks like an Array in Ruby), we can use Ruby methods, such as .each and .collect,
to iterate over it.
[#<Nokogiri::XML::Element:0x3fdf31ee8eb4 name="h2" attributes=[#<Nokogiri::XML::Attr:0x3fdf31ee8e28 name="class" value="inlineMobileLeft-2Yo002 imageTextBlockGrid3-2XAK6G">] children=[#<Nokogiri::XML::Text:0x3fdf31ee8900 "\n $1M in Scholarships for Women\n ">]>, #<Nokogiri::XML::Element:0x3fdf31ee8748 name="h2" attributes=[#<Nokogiri::XML::Attr:0x3fdf31ee86e4 name="class" value="tout__label heading heading--level-4">] children=[#<Nokogiri::XML::Text:0x3fdf31ee8270 "\n What Kind of Coding Program is Right for You?\n ">]>, #<Nokogiri::XML::Element:0x3fdf31ee807c name="h2" attributes=[#<Nokogiri::XML::Attr:0x3fdf31eedfcc name="class" value="tout__label heading heading--level-4">] children=[#<Nokogiri::XML::Text:0x3fdf31eeda90 "\n Attend an Online Info Session\n ">]>, #<Nokogiri::XML::Element:0x3fdf31eed8d8 name="h2" attributes=[#<Nokogiri::XML::Attr:0x3fdf31eed860 name="class" value="tout__label heading heading--level-4">] children=[#<Nokogiri::XML::Text:0x3fdf31eed43c "\n Coding Bootcamp Prep\n ">]>, #<Nokogiri::XML::Element:0x3fdf31eed284 name="h2" attributes=[#<Nokogiri::XML::Attr:0x3fdf31eed220 name="class" value="tout__label heading heading--level-4">] children=[#<Nokogiri::XML::Text:0x3fdf31eecdc0 "\n Online Software Engineering\n ">]>, #<Nokogiri::XML::Element:0x3fdf31eecc1c name="h2" attributes=[#<Nokogiri::XML::Attr:0x3fdf31eecba4 name="class" value="tout__label heading heading--level-4">] children=[#<Nokogiri::XML::Text:0x3fdf31eec744 "\n Data Science Bootcamp Prep\n ">]>, #<Nokogiri::XML::Element:0x3fdf31eec5a0 name="h2" attributes=[#<Nokogiri::XML::Attr:0x3fdf31eec53c name="class" value="tout__label heading heading--level-4">] children=[#<Nokogiri::XML::Text:0x3fdf31ef3fbc "\n Online Data Science\n ">]>]Instead of just outputting the results of doc.css, if we assign them
to a variable, we can then iterate over that variable with .each and puts out each course:
courses = doc.css("#2a778efd-1685-5ec6-9e5a-0843d6a88b7b .inlineMobileLeft-2Yo002.imageTextBlockGrid3-2XAK6G")
courses.each do |course|
puts course.text.strip
endWe'd see something like this:
Software EngineeringLaunch your career as a full-stack web developer ...
Data ScienceOur full-time data science program that gives students ...
UX/UI DesignLearn the user experience, client management, technical, ...
Not exactly the course listing as it scraped some other content as well - a great example how tricky scraping can be - but we've still achieved iteration!
Let's take another look at the element returned to us by our call on the .css
method. In the previous example, we had many Nokogiri objects to iterate over.
Looking at just the first one:
p doc.css("#2a778efd-1685-5ec6-9e5a-0843d6a88b7b .inlineMobileLeft-2Yo002.imageTextBlockGrid3-2XAK6G")[0]We get the following:
#<Nokogiri::XML::Element:0x3fc3494ba054 name="div" attributes=[#<Nokogiri::XML::Attr:0x3fc3494ba298 name="class" value="inlineMobileLeft-2Yo002 imageTextBlockGrid3-2XAK6G">] children=[#<Nokogiri::XML::Element:0x3fc3494abd88 name="div" attributes=[#<Nokogiri::XML::Attr:0x3fc3494abd24 name="class" value="media-3NKI6- horizontalImageContainer-1a2NpA">]...
This is an XML element. XML stands for Extensible Markup Language. Just like HTML, it is a set of rules for encoding and displaying data on the web.
When we use Nokogiri methods, we get XML elements in return. Looking at the
output object, we can see it has a name, "h2". We can get
this info directly by adding these to the end of our doc.css call:
p doc.css("#2a778efd-1685-5ec6-9e5a-0843d6a88b7b .inlineMobileLeft-2Yo002.imageTextBlockGrid3-2XAK6G")[0].name
# => "div"This is the name of the XML element, not to be confused with the HTML attribute
'name' that can be assigned to elements. Those types of attributes can be
accessed with .attributes. Using .attributes will return ids, names, and
classes, but will also return other useful content like alt and src for
images.
p doc.css("#2a778efd-1685-5ec6-9e5a-0843d6a88b7b .inlineMobileLeft-2Yo002.imageTextBlockGrid3-2XAK6G")[0].attributesSince this example doesn't have any attributes besides the CSS classes, we just get back the classes we already know:
{"class"=>#<Nokogiri::XML::Attr:0x3fd0e50e1b04 name="class" value="inlineMobileLeft-2Yo002 imageTextBlockGrid3-2XAK6G">}
One last but important method to note is children. Adding children will
return any child nodes nested inside this element. In this particular example,
all that is contained is a text node, but this XML element can contain all types
of XML elements, nested as children. On a webpage, an h2 HTML element may be
nested within a div. When scraped, this relationship can be represented by
having an XML object named "div" with a child XML object named "h2".
Nokogiri collects these objects into a hierarchical data structure, much like the nested arrays and hashes we've been building and manipulating for a while now. This structure allows us to iterate over an array of Nokogiri objects and use enumerators to grab the values of attributes and text.
By using Nokogiri, we can get any website's HTML, represented in XML objects,
including any text or data displayed on that site. Using methods like .css, we
can then filter out the specific parts of the website we need and use additional
methods like .text and .attributes to extract the content we want.
As each website is designed differently, scraping tends to require customized code for each site you want to scrape. As sites update their styles and designs, scrapers we've built may no longer work.
However, being able to scrape websites gives us access to information that can be time-consuming or otherwise very difficult to collect. Taking a little time to update a scraper is typically much easier and faster than manually updating data.
Note: One final note about scraping - the content we're getting by scraping
is all technically publicly available, as it all visible on public websites. Be
careful, however, as some content may not be used without permission or
licensing. Images, for instance, often belong to someone and can have a license
attached - something you would probably want to look into before scraping any
image src attributes from a site!
-
Scraping is a big topic, and it takes a lot of practice to get comfortable doing it. The below resource is a great place to learn more about scraping and even get some practice with simple examples. If you felt really confused by this reading, we recommend checking it out before moving on.
View Scraping on Learn.co and start learning to code for free.