Implemented a Bidirectional Attention Flow neural network as a baseline, improving Chris Chute's model implementation, adding word-character inputs as described in the original paper and improving GauthierDmns' code.
You can reproduce the work following the Set-Up section, and potentially (recommended!) train the model on a single GPU setting the cuda variable in config.py to True.
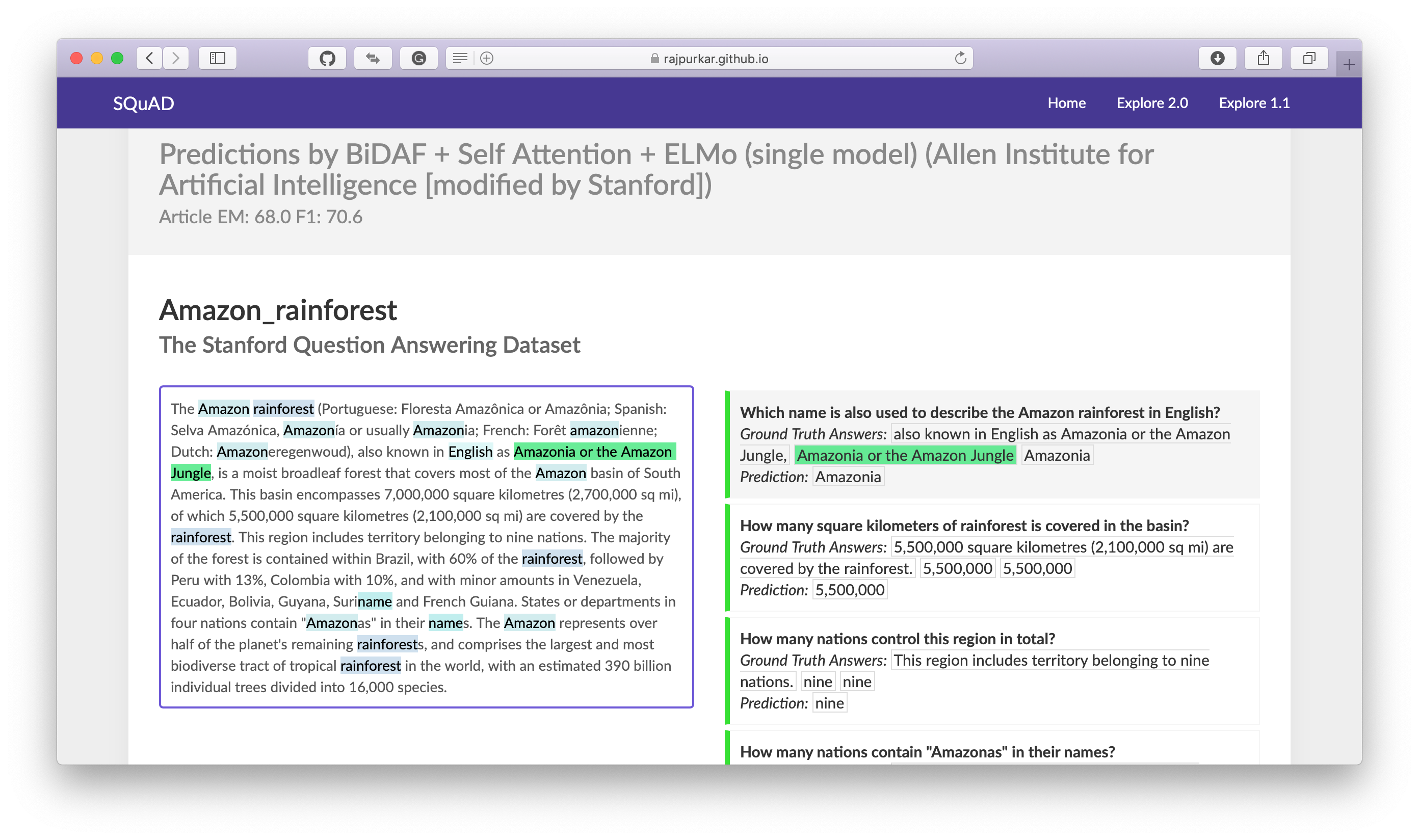
Question-answer pairs for a sample passage in the SQuAD dataset. Each of the answers is a segment of text from the passage.
- Sample from SQuAD 2.0

 Source: BiDAF paper
Source: BiDAF paper
Python 3.6
├── config.py <- Configuration file with data directories and hyperparamters to train the model
├── data_loader.py <- Define an iterator who collects batches of data to train the model
├── eval.py <- Evaluate the model on a new pair of (context, question)
├── layers.py <- Define the various layers to be used by the main BiDAF model
├── make_dataset.py <- Download the SquAD dataset and pre-process the data for training
├── model.py. <- Define the BiDAF model architecture
├── requirements.txt <- Required Python libraries to build the project
├── test.py <- Test the performance of a trained model on the DEV dataset
├── train.py <- Train a model using the TRAIN dataset only
├── utils.py <- Group a bunch of useful functions to process the data

Exact-Match and F1 Score on Validation set after training:
| EM | F1 |
|---|---|
| 0.64 | 0.75 |
- Clone the repository
- Create a directory for your experiments, logs and model weights:
mkdir output - Download GloVE word vectors: https://nlp.stanford.edu/projects/glove/
- Modify the
config.pyfile to set up the paths where your GloVE, SquAD and models will be located - Create a Python virtual environment, source to it:
mkvirualenv qa-env ; workon qa-envif you use virtualenvwrapper - Install the dependencies:
pip install -r requirements.txt ; python -m spacy download en - Run
python make_dataset.pyto download SquAD dataset and pre-process the data - Run
python train.pyto train the model with hyper-parameters found inconfig.py - Run
python test.pyto test the model EM and F1 scores on Dev examples - Play with
eval.pyto answer your own questions! :)
- set up a variable to choose between training the model with word only VS word + characters
- collect the moving average of the weights during training and use them during testing
- add the ability to train the model on multiple GPUs, and offer half-precision training to speed-up the training
- improve this baseline using pre-training encoding such as BERT, and/or set-up a multi-task learning pipeline to jointly learn to answer questions together with another closely related NLP task.
- SQuAD:
- BiDAF: https://arxiv.org/pdf/1611.01603.pdf
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
- GloVe: Global Vectors for Word Representation
- SQuAD 2.0: https://rajpurkar.github.io/SQuAD-explorer/
- Bi-Directional Attention Flow for Machine Comprehension
- Authors' TensorFlow implementation: https://allenai.github.io/bi-att-flow/
- BiDAF baseline model: https://github.com/chrischute/squad
- PyTorch pretrained BERT: https://github.com/huggingface/pytorch-pretrained-BERT
- GloVE: https://nlp.stanford.edu/projects/glove/
- Papers With Code
- SQuAD: 100,000+ Questions for Machine Comprehension of Text: https://paperswithcode.com/paper/squad-100000-questions-for-machine
- Bidirectional Attention Flow for Machine Comprehension : https://paperswithcode.com/paper/bidirectional-attention-flow-for-machine
- Understanding LSTM Networks: http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- A Brief Overview of Attention Mechanism: https://medium.com/syncedreview/a-brief-overview-of-attention-mechanism-13c578ba9129
- Understanding Encoder-Decoder Sequence to Sequence Model: https://towardsdatascience.com/understanding-encoder-decoder-sequence-to-sequence-model-679e04af4346
- Semantic Word Embeddings: https://www.offconvex.org/2015/12/12/word-embeddings-1/
- Question Answering in Natural Language Processing [Part-I]: https://medium.com/lingvo-masino/question-and-answering-in-natural-language-processing-part-i-168f00291856
- Building a Question-Answering System from Scratch— Part 1: https://towardsdatascience.com/building-a-question-answering-system-part-1-9388aadff507
- NLP — Building a Question Answering model: https://towardsdatascience.com/nlp-building-a-question-answering-model-ed0529a68c54
- F1 score: https://en.wikipedia.org/wiki/F1_score