Important
As of November 15, 2023, Azure Cognitive Search has been renamed to Azure AI Search.
Welcome to the "Chat with your data" Solution Accelerator repository! The "Chat with your data" Solution Accelerator is a powerful tool that combines the capabilities of Azure AI Search and Large Language Models (LLMs) to create a conversational search experience. This solution accelerator uses an Azure OpenAI GPT model and an Azure AI Search index generated from your data, which is integrated into a web application to provide a natural language interface for search queries.

This repository provides a template for setting up the solution accelerator, along with detailed instructions on how to use and customize it to fit your specific needs.
This repository provides a template for setting up the solution accelerator, along with detailed instructions on how to use and customize it to fit your specific needs. It provides the following features:
- Chat with an Azure OpenAI model using your own data
- Upload and process your documents
- Index public web pages
- Easy prompt configuration
- Multiple chunking strategies
You should use this repo when your scenario customization needs exceed the out-of-the-box experience offered by Azure OpenAI on your data and you don't require to streamline the entire development cycle of your AI application, as you can with Azure Machine Learning prompt flow.
The accelerator presented here provides several options, for example:
- The ability to ground a model using both data and public web pages
- Advanced prompt engineering capabilities
- An admin site for ingesting/inspecting/configuring your dataset on the fly
- Running a Retrieval Augmented Generation (RAG) solution locally, as a Docker container
*Have you seen ChatGPT + Enterprise data with Azure OpenAI and AI Search demo? If you would like to experiment: Play with prompts, understanding RAG pattern different implementation approaches, see how different features interact with the RAG pattern and choose the best options for your RAG deployments, take a look at that repo.
Here is a comparison table with a few features offered by Azure, an available GitHub demo sample and this repo, that can provide guidance when you need to decide which one to use:
| Name | Feature or Sample? | What is it? | When to use? |
|---|---|---|---|
| Azure OpenAI on your data | Azure feature | Azure OpenAI Service offers out-of-the-box, end-to-end RAG implementation that uses a REST API or the web-based interface in the Azure AI Studio to create a solution that connects to your data to enable an enhanced chat experience with Azure OpenAI ChatGPT models and Azure AI Search. | This should be the first option considered for developers that need an end-to-end solution for Azure OpenAI Service with an Azure AI Search retriever. Simply select supported data sources, that ChatGPT model in Azure OpenAI Service , and any other Azure resources needed to configure your enterprise application needs. |
| Azure Machine Learning prompt flow | Azure feature | RAG in Azure Machine Learning is enabled by integration with Azure OpenAI Service for large language models and vectorization. It includes support for Faiss and Azure AI Search as vector stores, as well as support for open-source offerings, tools, and frameworks such as LangChain for data chunking. Azure Machine Learning prompt flow offers the ability to test data generation, automate prompt creation, visualize prompt evaluation metrics, and integrate RAG workflows into MLOps using pipelines. | When Developers need more control over processes involved in the development cycle of LLM-based AI applications, they should use Azure Machine Learning prompt flow to create executable flows and evaluate performance through large-scale testing. |
| "Chat with your data" Solution Accelerator - (This repo) | Azure sample | End-to-end baseline RAG pattern sample that uses Azure AI Search as a retriever. | This sample should be used by Developers when the RAG pattern implementations provided by Azure are not able to satisfy business requirements. This sample provides a means to customize the solution. Developers must add their own code to meet requirements, and adapt with best practices according to individual company policies. |
| ChatGPT + Enterprise data with Azure OpenAI and AI Search demo | Azure sample | RAG pattern demo that uses Azure AI Search as a retriever. | Developers who would like to use or present an end-to-end demonstration of the RAG pattern should use this sample. This includes the ability to deploy and test different retrieval modes, and prompts to support business use cases. |
Out-of-the-box, you can upload the following file types:
- JPEG
- JPG
- PNG
- TXT
- HTML
- MD (Markdown)
- DOCX
-
Azure subscription - Create one for free with contributor access.
-
An Azure OpenAI resource and a deployment for one of the following Chat model and an embedding model:
- Chat Models
- GPT-3.5
- GPT-4
- Embedding Model
- text-embedding-ada-002
NOTE: The deployment template defaults to gpt-35-turbo and text-embedding-ada-002. If your deployment names are different, update them in the deployment process.
- Chat Models
-
Click the following deployment button to create the required resources for this accelerator directly in your Azure Subscription.
-
Add the following fields:
Field Description Resource group The resource group that will contain the resources for this accelerator. You can select Create new to create a new group. Resource prefix A text string that will be appended to each resource that gets created, and used as the website name for the web app. This name cannot contain spaces or special characters. Azure OpenAI resource The name of your Azure OpenAI resource. This resource must have already been created previously. Azure OpenAI key The access key associated with your Azure OpenAI resource. Orchestration strategy Use Azure OpenAI Functions (openai_functions) or LangChain (langchain) for messages orchestration. If you are using a new model version 0613 select "openai_functions" (or "langchain"), if you are using a 0314 model version select "langchain" You can find the ARM template used, along with a Bicep file for deploying this accelerator in the
/infrastructuredirectory.NOTE: By default, the deployment name in the application settings is equal to the model name (gpt-35-turbo and text-embedding-ada-002). If you named the deployment in a different way, you should update the application settings to match your deployment names.
-
Navigate to the admin site, where you can upload documents. It will be located at:
https://{MY_RESOURCE_PREFIX}-website-admin.azurewebsites.net/Where
{MY_RESOURCE_PREFIX}is replaced with the resource prefix you used during deployment. Then select Ingest Data and add your data. You can find sample data in the/datadirectory.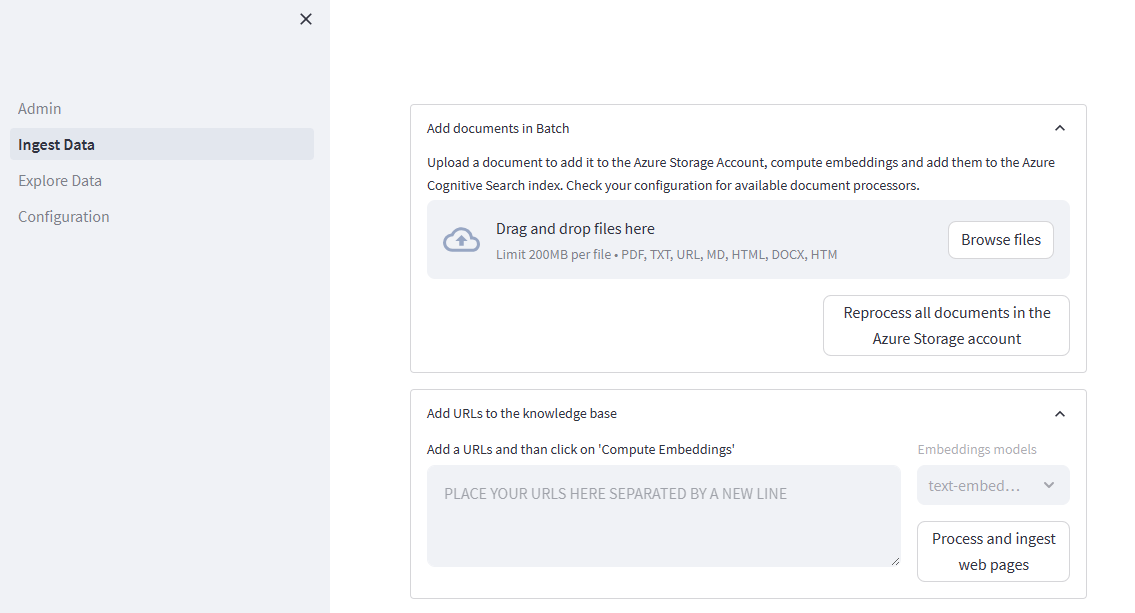
-
Navigate to the web app to start chatting on top of your data. The web app can be found at:
https://{MY_RESOURCE_PREFIX}-website.azurewebsites.net/Where
{MY_RESOURCE_PREFIX}is replaced with the resource prefix you used during deployment.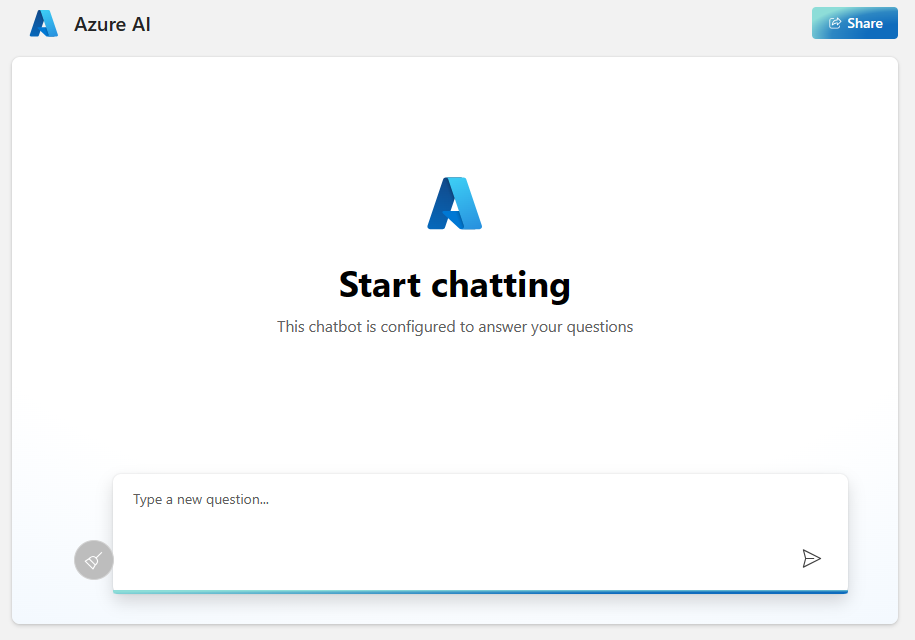


To customize the accelerator or run it locally, first, copy the .env.sample file to your development environment's .env file, and edit it according to environment variable values table below.
You can run the full solution locally with the following commands - this will spin up 3 different Docker containers:
| Container | Description |
|---|---|
| webapp | A container for the chat app, enabling you to chat on top of your data. |
| admin webapp | A container for the "admin" site where you can upload and explore your data. |
| batch processing functions | A container helping with processing requests. |
Run the following docker compose command.
cd docker
docker compose upFor faster development, you can run the frontend Typescript React UI app and the Python Flask app in development mode. This allows the app to "hot reload" meaning your changes will automatically be reflected in the app without having to refresh or restart the local servers.
To run the app locally with hot refresh, first follow the instructions to update your .env file with the needed values.
Open a terminal and enter the following commands
cd code
python -m pip install -r requirements.txt
cd app
python -m flask --app ./app.py --debug runOpen a new separate terminal and enter the following commands:
cd code
cd frontend
npm install
npm run devThe local vite server will return a url that you can use to access the chat interface locally, such as http://localhost:5174/.
docker build -f docker\WebApp.Dockerfile -t YOUR_DOCKER_REGISTRY/YOUR_DOCKER_IMAGE .
docker run --env-file .env -p 8080:80 YOUR_DOCKER_REGISTRY/YOUR_DOCKER_IMAGE
docker push YOUR_DOCKER_REGISTRY/YOUR_DOCKER_IMAGEIf you want to develop and run the backend container locally, use the following commands.
cd code
cd admin
python -m pip install -r requirements.txt
streamlit run Admin.pyThen access http://localhost:8501/ for getting to the admin interface.
docker build -f docker\AdminWebApp.Dockerfile -t YOUR_DOCKER_REGISTRY/YOUR_DOCKER_IMAGE .
docker run --env-file .env -p 8081:80 YOUR_DOCKER_REGISTRY/YOUR_DOCKER_IMAGE
docker push YOUR_DOCKER_REGISTRY/YOUR_DOCKER_IMAGENOTE: If you are using Linux, make sure to go to https://github.com/Azure-Samples/chat-with-your-data-solution-accelerator/blob/main/docker/docker-compose.yml#L9 and modify the docker-compose.yml to use forward slash /. The backslash version just works with Windows.
If you want to develop and run the batch processing functions container locally, use the following commands.
First, install Azure Functions Core Tools.
cd code
cd batch
func startOr use the Azure Functions VS Code extension.
docker build -f docker\Backend.Dockerfile -t YOUR_DOCKER_REGISTRY/YOUR_DOCKER_IMAGE .
docker run --env-file .env -p 7071:80 YOUR_DOCKER_REGISTRY/YOUR_DOCKER_IMAGE
docker push YOUR_DOCKER_REGISTRY/YOUR_DOCKER_IMAGE| App Setting | Value | Note |
|---|---|---|
| AZURE_SEARCH_SERVICE | The URL of your Azure AI Search resource. e.g. https://.search.windows.net | |
| AZURE_SEARCH_INDEX | The name of your Azure AI Search Index | |
| AZURE_SEARCH_KEY | An admin key for your Azure AI Search resource | |
| AZURE_SEARCH_USE_SEMANTIC_SEARCH | False | Whether or not to use semantic search |
| AZURE_SEARCH_SEMANTIC_SEARCH_CONFIG | The name of the semantic search configuration to use if using semantic search. | |
| AZURE_SEARCH_TOP_K | 5 | The number of documents to retrieve from Azure AI Search. |
| AZURE_SEARCH_ENABLE_IN_DOMAIN | True | Limits responses to only queries relating to your data. |
| AZURE_SEARCH_CONTENT_COLUMNS | List of fields in your Azure AI Search index that contains the text content of your documents to use when formulating a bot response. Represent these as a string joined with " | |
| AZURE_SEARCH_CONTENT_VECTOR_COLUMNS | Field from your Azure AI Search index for storing the content's Vector embeddings | |
| AZURE_SEARCH_DIMENSIONS | 1536 | Azure OpenAI Embeddings dimensions. 1536 for text-embedding-ada-002 |
| AZURE_SEARCH_FIELDS_ID | id | AZURE_SEARCH_FIELDS_ID: Field from your Azure AI Search index that gives a unique idenitfier of the document chunk. id if you don't have a specific requirement. |
| AZURE_SEARCH_FILENAME_COLUMN | AZURE_SEARCH_FILENAME_COLUMN: Field from your Azure AI Search index that gives a unique idenitfier of the source of your data to display in the UI. |
|
| AZURE_SEARCH_TITLE_COLUMN | Field from your Azure AI Search index that gives a relevant title or header for your data content to display in the UI. | |
| AZURE_SEARCH_URL_COLUMN | Field from your Azure AI Search index that contains a URL for the document, e.g. an Azure Blob Storage URI. This value is not currently used. | |
| AZURE_SEARCH_FIELDS_TAG | tag | Field from your Azure AI Search index that contains tags for the document. tag if you don't have a specific requirement. |
| AZURE_SEARCH_FIELDS_METADATA | metadata | Field from your Azure AI Search index that contains metadata for the document. metadata if you don't have a specific requirement. |
| AZURE_OPENAI_RESOURCE | the name of your Azure OpenAI resource | |
| AZURE_OPENAI_MODEL | The name of your model deployment | |
| AZURE_OPENAI_MODEL_NAME | gpt-35-turbo | The name of the model |
| AZURE_OPENAI_KEY | One of the API keys of your Azure OpenAI resource | |
| AZURE_OPENAI_EMBEDDING_MODEL | text-embedding-ada-002 | The name of you Azure OpenAI embeddings model deployment |
| AZURE_OPENAI_TEMPERATURE | 0 | What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. A value of 0 is recommended when using your data. |
| AZURE_OPENAI_TOP_P | 1.0 | An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. We recommend setting this to 1.0 when using your data. |
| AZURE_OPENAI_MAX_TOKENS | 1000 | The maximum number of tokens allowed for the generated answer. |
| AZURE_OPENAI_STOP_SEQUENCE | Up to 4 sequences where the API will stop generating further tokens. Represent these as a string joined with " | |
| AZURE_OPENAI_SYSTEM_MESSAGE | You are an AI assistant that helps people find information. | A brief description of the role and tone the model should use |
| AZURE_OPENAI_API_VERSION | 2023-06-01-preview | API version when using Azure OpenAI on your data |
| AzureWebJobsStorage | The connection string to the Azure Blob Storage for the Azure Functions Batch processing | |
| BACKEND_URL | The URL for the Backend Batch Azure Function. Use http://localhost:7071 for local execution and http://backend for docker compose | |
| DOCUMENT_PROCESSING_QUEUE_NAME | doc-processing | The name of the Azure Queue to handle the Batch processing |
| AZURE_BLOB_ACCOUNT_NAME | The name of the Azure Blob Storage for storing the original documents to be processed | |
| AZURE_BLOB_ACCOUNT_KEY | The key of the Azure Blob Storage for storing the original documents to be processed | |
| AZURE_BLOB_CONTAINER_NAME | The name of the Container in the Azure Blob Storage for storing the original documents to be processed | |
| AZURE_FORM_RECOGNIZER_ENDPOINT | The name of the Azure Form Recognizer for extracting the text from the documents | |
| AZURE_FORM_RECOGNIZER_KEY | The key of the Azure Form Recognizer for extracting the text from the documents | |
| APPINSIGHTS_CONNECTION_STRING | The Application Insights connection string to store the application logs | |
| ORCHESTRATION_STRATEGY | openai_functions | Orchestration strategy. Use Azure OpenAI Functions (openai_functions) or LangChain (langchain) for messages orchestration. If you are using a new model version 0613 select "openai_functions" (or "langchain"), if you are using a 0314 model version select "langchain" |
| AZURE_CONTENT_SAFETY_ENDPOINT | The endpoint of the Azure AI Content Safety service | |
| AZURE_CONTENT_SAFETY_KEY | The key of the Azure AI Content Safety service |
This solution accelerator deploys the following resources. It's crucial to comprehend the functionality of each. Below are the links to their respective documentation:
- Azure OpenAI Service Documentation
- Azure AI Search Documentation
- Azure Blob Storage Documentation
- Azure Functions Documentation
- Azure AI Document Intelligence Documentation
- Azure App Service Documentation
This solution accelerator deploys multiple resources. Evaluate the cost of each component prior to deployment.
The following are links to the pricing details for some of the resources:
- Azure OpenAI service pricing. GPT and embedding models are charged separately.
- Azure AI Search pricing. AI Search core service and semantic search are charged separately.
- Azure Blob Storage pricing
- Azure Functions pricing
- Azure AI Document Intelligence pricing
- Azure Web App Pricing
Azure AI Search, when used as a retriever in the Retrieval-Augmented Generation (RAG) pattern, plays a key role in fetching relevant information from a large corpus of data. The RAG pattern involves two key steps: retrieval of documents and generation of responses. Azure AI Search, in the retrieval phase, filters and ranks the most relevant documents from the dataset based on a given query.
The importance of optimizing data in the index for relevance lies in the fact that the quality of retrieved documents directly impacts the generation phase. The more relevant the retrieved documents are, the more accurate and pertinent the generated responses will be.
Azure AI Search allows for fine-tuning the relevance of search results through features such as scoring profiles, which assign weights to different fields, Lucene's powerful full-text search capabilities, vector search for similarity search, multi-modal search, recommendations, hybrid search and semantic search to use AI from Microsoft to rescore search results and moving results that have more semantic relevance to the top of the list. By leveraging these features, one can ensure that the most relevant documents are retrieved first, thereby improving the overall effectiveness of the RAG pattern.
Moreover, optimizing the data in the index also enhances the efficiency, the speed of the retrieval process and increases relevance which is an integral part of the RAG pattern.
- Consider switching security keys and using RBAC instead for authentication.
- Consider setting up a firewall, private endpoints for inbound connections and shared private links for built-in pull indexers.
- For the best results, prepare your index data and consider analyzers.
- Analyze your resource capacity needs.
- Follow the best practices described in Azure Well-Architected-Framework.
- Understand the Retrieval Augmented Generation (RAG) in Azure AI Search.
- Understand the functionality and configuration that would adapt better to your solution and test with your own data for optimal retrieval.
- Experiment with different options, define the prompts that are optimal for your needs and find ways to implement functionality tailored to your business needs with this demo, so you can then adapt to the accelerator.
- Follow the Responsible AI best practices.
- Understand the levels of access of your users and application.
Chunking is essential for managing large data sets, optimizing relevance, preserving context, integrating workflows, and enhancing the user experience. See How to chunk documents for more information.
These are the chunking strategy options you can choose from:
- Layout: An AI approach to determine a good chunking strategy.
- Page: This strategy involves breaking down long documents into pages.
- Fixed-Size Overlap: This strategy involves defining a fixed size that’s sufficient for semantically meaningful paragraphs (for example, 250 words) and allows for some overlap (for example, 10-25% of the content). This usually helps creating good inputs for embedding vector models. Overlapping a small amount of text between chunks can help preserve the semantic context.
- Paragraph: This strategy allows breaking down a difficult text into more manageable pieces and rewrite these “chunks” with a summarization of all of them.
This repository is licensed under the MIT License.
The data set under the /data folder is licensed under the CDLA-Permissive-2 License.
The data set under the /data folder has been generated with Azure OpenAI GPT and DALL-E 2 models.
This presentation, demonstration, and demonstration model are for informational purposes only and (1) are not subject to SOC 1 and SOC 2 compliance audits, and (2) are not designed, intended or made available as a medical device(s) or as a substitute for professional medical advice, diagnosis, treatment or judgment. Microsoft makes no warranties, express or implied, in this presentation, demonstration, and demonstration model. Nothing in this presentation, demonstration, or demonstration model modifies any of the terms and conditions of Microsoft’s written and signed agreements. This is not an offer and applicable terms and the information provided are subject to revision and may be changed at any time by Microsoft.
This presentation, demonstration, and demonstration model do not give you or your organization any license to any patents, trademarks, copyrights, or other intellectual property covering the subject matter in this presentation, demonstration, and demonstration model.
The information contained in this presentation, demonstration and demonstration model represents the current view of Microsoft on the issues discussed as of the date of presentation and/or demonstration, for the duration of your access to the demonstration model. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of presentation and/or demonstration and for the duration of your access to the demonstration model.
No Microsoft technology, nor any of its component technologies, including the demonstration model, is intended or made available as a substitute for the professional advice, opinion, or judgment of (1) a certified financial services professional, or (2) a certified medical professional. Partners or customers are responsible for ensuring the regulatory compliance of any solution they build using Microsoft technologies.