val sparkVersion = "2.4.3"
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core",
"org.apache.spark" %% "spark-sql"
).map(_ % sparkVersion)- Get Sample Dataset
git clone https://github.com/stream-processing-with-spark/datasets.gitcd datasets/NASA-weblogstar -xvf nasa_dataset_july_1995.tgzmv nasa_dataset_july_1995 /tmp
Clean up Sample Dataset:
rm -rf /tmp/nasa_dataset_july_1995
- run tcp server that delivers logs:
sbt 'runMain chapter7.TcpServerRunner' - run spark job:
sbt 'runMain chapter7.NasaDatasetStreamed'
- configured in `projectRoot/metrics.properties`
- run docker-compose:
cd dockerdocker-compose up
Graphite: http://locahost
Grafana
- Set up Graphite as a datasource
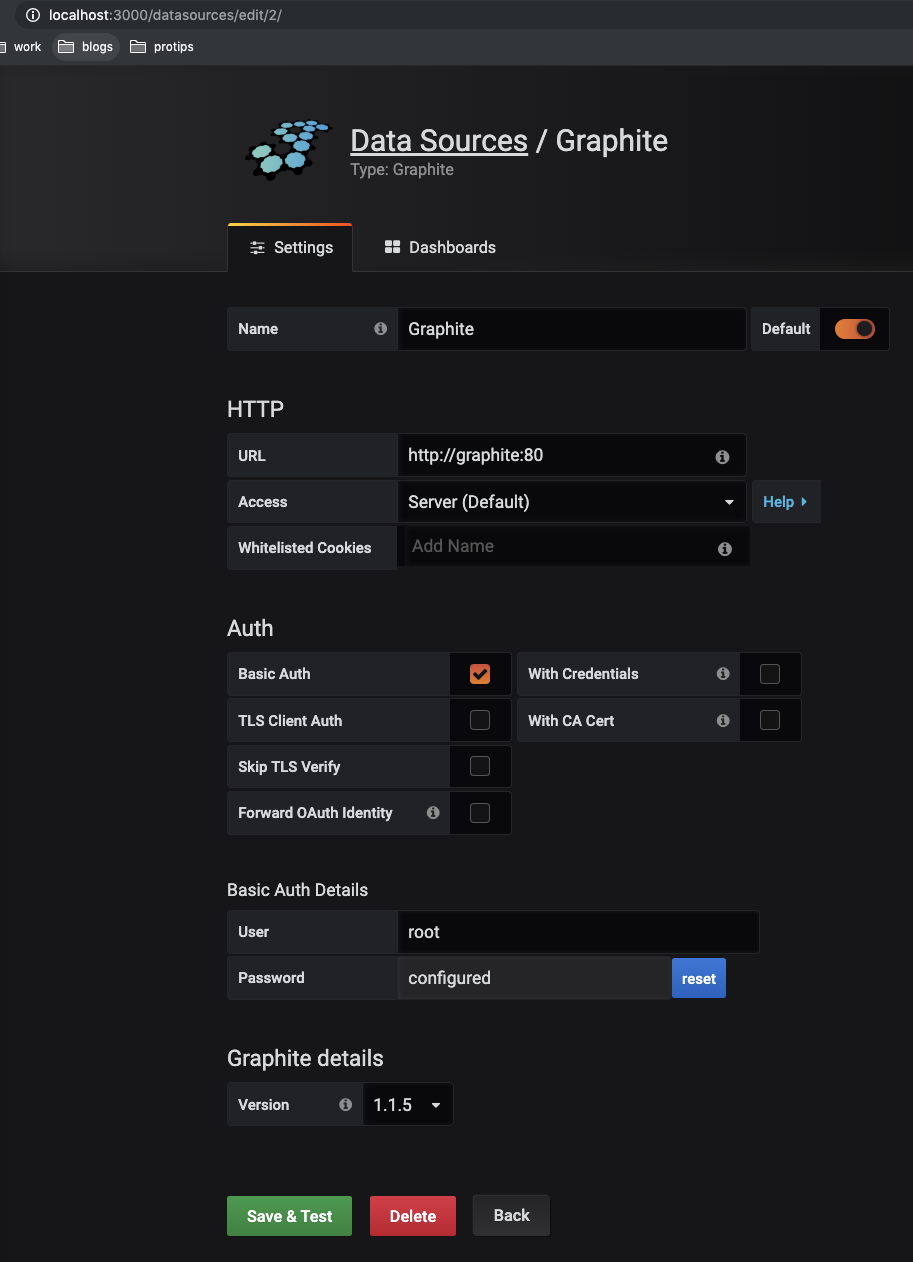
http://locahost:3000http://localhost:3000/datasources- Select 'Graphite'
- config:
- url: http://graphite:80
- Access: Server (default)
- Select Basic Auth - Creds: root/root
- version: 1.1.x
