![]()
Welcome to the official GitHub repository for LIBRA (Long Input Benchmark for Russian Analysis). This repository contains the codebase and documentation for evaluating the capabilities of large language models (LLMs) in understanding and processing long texts in Russian.
In order to add your own model, create a config file using configs/template.ini for it (e.g., longchat32k.ini) and specify the necessary parameters in it.
First, you need to generate answers for each task, to do this, use the following command:
python predict.py -c path_to_configThe predictions will be saved in "predictions/" or wherever you choose in your config.
After the generated predictions are saved, you need to run the command to evaluate:
python eval.py -p path_to_predictionsThe results will be saved in "results/".
LIBRA includes 21 datasets adapted for different tasks and complexities. The datasets are divided into four complexity groups and allow evaluation across various context lengths ranging from 4k to 128k tokens.
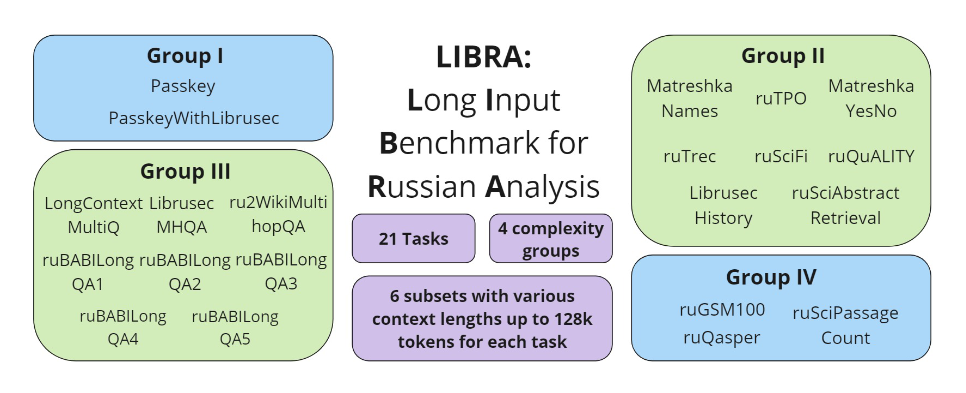
- Passkey: Extract a relevant piece of code number from a long text fragment. Based on the original PassKey test from the m LongLLaMA’s GitHub repo.
- PasskeyWithLibrusec: Similar to Passkey but with added noise from Librusec texts.
- MatreshkaNames: Identify the person in dialogues based on the discussed topic. We used Matreshka dataset and Russian Names dataset to create this and the next task.
- MatreshkaYesNo: Indicate whether a specific topic was mentioned in the dialog.
- LibrusecHistory: Answer questions based on historical texts. Ideologically similiar to the PassageRetrieval dataset from LongBench.
- ruTREC: Few-shot in-context learning for topic classification. Created by translating the TREC dataset from LongBench.
- ruSciFi: Answer true/false based on context and general world knowledge. Translation of SciFi dataset from L-Eval which originally was based on SF-Gram.
- ruSciAbstractRetrieval: Retrieve relevant paragraphs from scientific abstracts.
- ruTPO: Multiple-choice questions similar to TOEFL exams. Translation of the TPO dataset from L-Eval.
- ruQuALITY: Multiple-choice QA tasks based on detailed texts. Created by translating the QuALITY dataset from L-Eval.
- ruBABILongQA: 5 long-context reasoning tasks for QA using facts hidden among irrelevant information.
- LongContextMultiQ: Multi-hop QA based on Wikidata and Wikipedia.
- LibrusecMHQA: Multi-hop QA requiring information distributed across several text parts.
- ru2WikiMultihopQA: Translation of the 2WikiMultihopQA dataset from LongBench.
- ruSciPassageCount: Count unique paragraphs in a long text. Uses the basic idea of the original PassageCount dataset from LongBench.
- ruQasper: Question Answering over academic research papers. Created by translating the Qasper dataset from LongBench.
- ruGSM100: Solve math problems using Chain-of-Thought reasoning. Created by translating the GSM100 dataset from L-Eval.
@misc{churin2024longinputbenchmarkrussian,
title={Long Input Benchmark for Russian Analysis},
author={Igor Churin and Murat Apishev and Maria Tikhonova and Denis Shevelev and Aydar Bulatov and Yuri Kuratov and Sergei Averkiev and Alena Fenogenova},
year={2024},
eprint={2408.02439},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2408.02439},
}