VQ-GANs were introduced in the paper ""Taming Transformers for High-Resolution Image Synthesis""
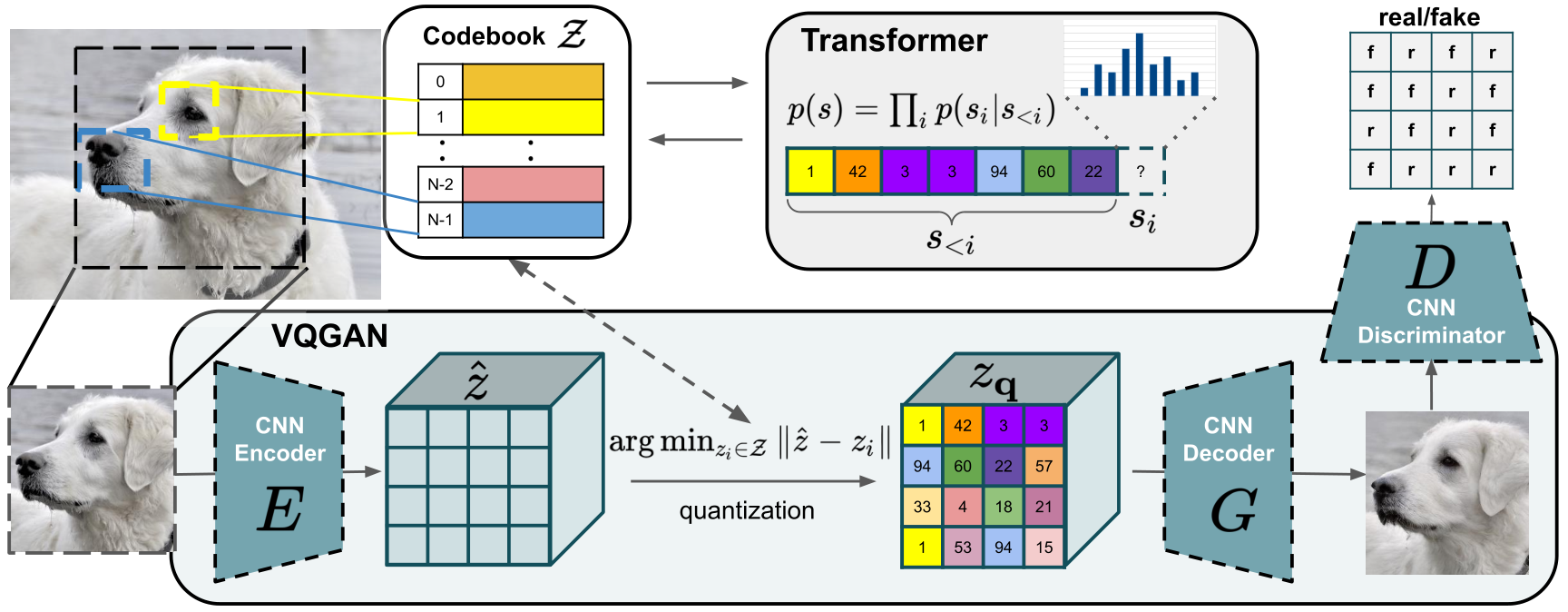
The authors have used VQ-GAN, which is a variant of the original VQ-VAE that uses a discriminator and perpetual loss to keep good perceptual quality at an increased compression rate. It was in a two-step manner by firstly, training the VQ-GAN and learning the quantized codebook then training the autoregressive transformer using the quantized codebook as sequential input to the transformer.
Access the colab file at: VQ-GANS.ipynb
VQGAN was proposed, as a variant of the original VQVAE.
VQ-VAE consists of an encoder that maps observations/images onto a sequence of discrete latent variables, and a decoder that reconstructs the observations from these discrete variables. They use a shared codebook.
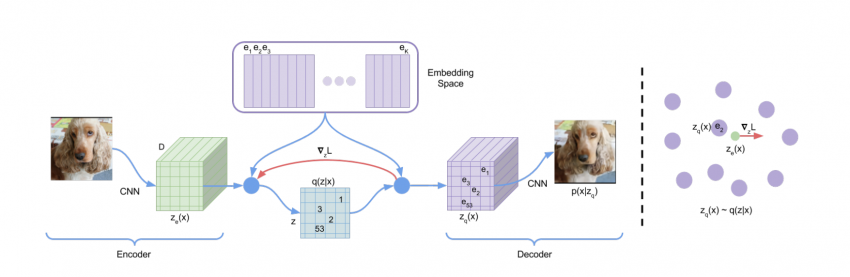
The encoder creates a “latent space” which is simply a space of compressed image data in which similar data points are closer together. This is then quantized based on its distance to the code vectors such that each vector is replaced by the index of the nearest code vector in the codebook. The same is used by the decoder for reconstruction.
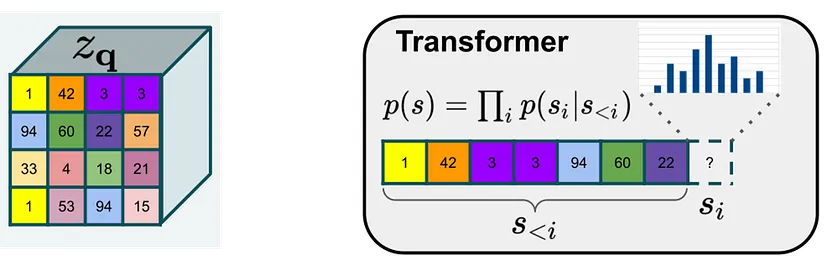
The Transformer part learns which code book vectors could make sense together and which not and after that it can generate new possible code book vectors which it thinks could go along together. We are using a transformer because our code book vectors representing an image is just a sequence and transformers are really good at sequence tasks.