Text clustering is an unsupervised learning technique which is used to group similar documents into a cluster. There are a variety of applications of text clustering such as chatbots, media monitoring, recommender systems, information retrieval, customer feedback analysis and organization of documents such as the news articles, identifying similar products, etc. In this project I will be using the The 20 Newsgroups Dataset which contains about 18000 news articles. So the goal of this project is to design a text classification model which can detect hidden relationships in the text data and can assign them to the most relevant groups. I will be using the Rand Index scores to compare the results of the clustering algorithms.
It is very important to understand and explore the data before modelling the data. Therefore I have created visualizations to understand the distribution of classes to which the news articles belong and have also analyzed individual articles. The following was discovered in the EDA process:
- The dataset has news articles and the classes to which they belong.
- The class attribute is numerical.
- There news articles are text data.
- The text data has noise such as special characters, numbers, stop words, etc.
Let us look at the distribution of classes in the dataset
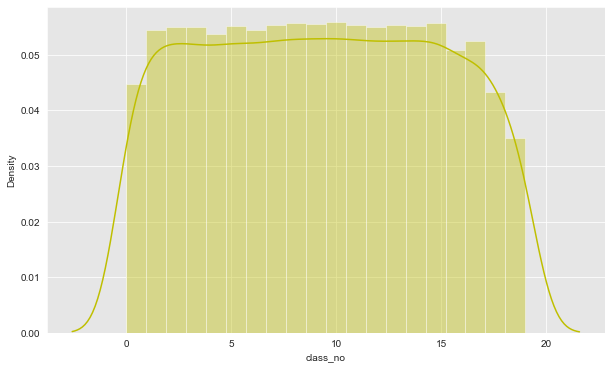
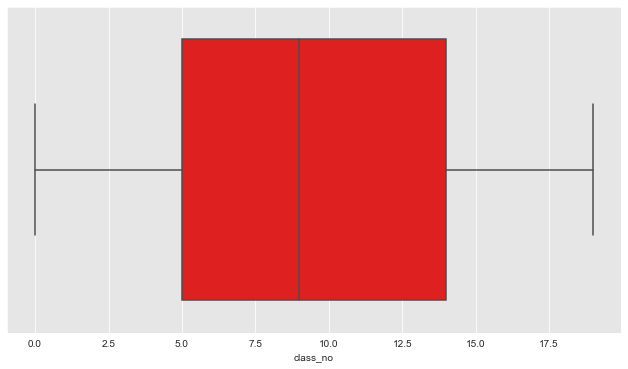
From the above plots we can infer that the target variable - news category has a uniform distribution.
Now that we have gained the understanding about the dataset through the EDA, we can move ahead and try various Machine Learning Algorithms to design a system to cluster similar news articles.
For the data cleaning and preprocessing I implemented the following steps:
- The news articles were tokenized.
- The special characters and numbers were removed.
- The news articles were lemmatized.
- The stop words were removed.
- Bigrams and trigrams were discovered.
I have tried various different methodologies to perform clustering on this dataset. I have evaluated the performance of these models based on the Rand Index scores between the clustering approaches and the ground truth. The following methodologies were used:
- I performed LDA (Latent Dirichlet allocation) topic modelling for n number of clusters and compared the results with the true class labels.
- I generated 20, 50, 100 dimensional paragraph embeddings (Doc2Vec) for each news article and performed hierarchical clustering for n number of clusters in each of the n-dimensional embedded space using the Euclidean and cosine similarities. And I compared this approach to the true classes using the Rand Index scores.
The RI scores for best of each of the approaches are:
| Approach | Rand Index Score |
|---|---|
| LDA topic modelling | 0.872104 |
| Clustering in the embedded space | 0.864050 |
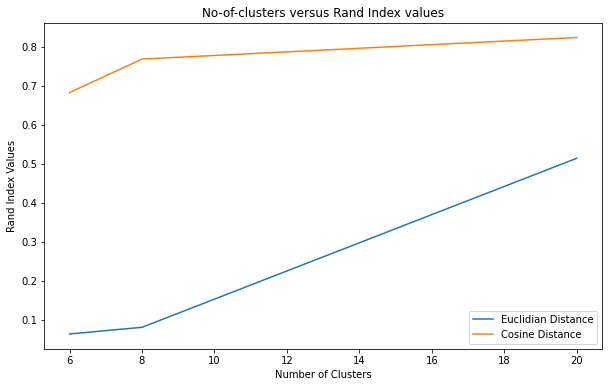
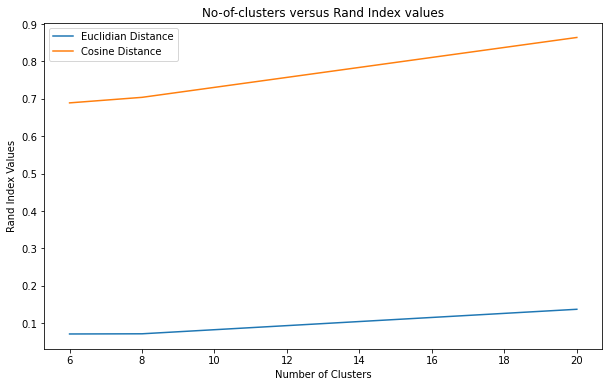
Let us take a look at the visualization to better understand the performance of each approach.
- LDA topic modelling

- Clustering in the embedded space
- 20 dimensional embedded space
- 50 dimensional embedded space
- 100 dimensional embedded space
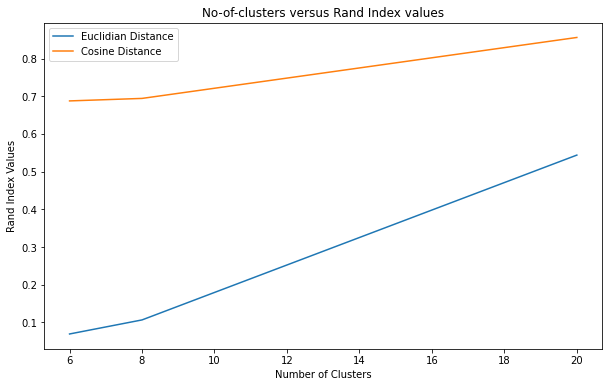
From the above plots and the Rand Index accuracy scores I can conclude that the LDA topic modelling is working the best . We can also infer that cosine similarity performs better than the Euclidean similarity in the embedded space. Hence I will fine tune the LDA model for clustering the news articles.
I have trained a LDA model that can cluster the news articles into their respective groups. The model can perform the clustering of text data with a Rand Index score of 0.872104.
- The model predictions are saved into a csv file.
In this project I have performed an EDA on the 20 Newsgroups dataset, performed data cleaning using various NLP techniques, model testing, parameter tuning and model building for clustering the news articles. I have demonstrated the results using the rand index scores and meaningful visualizations to better understand the data and results.
In the future I would like to extend this model to be able to provide recommendations of similar news articles to the user and I would also like to try various different approaches for text clustering.