There is a car which is present on a racetrack.
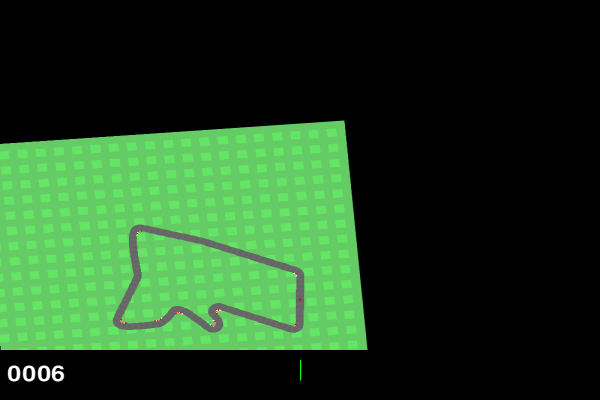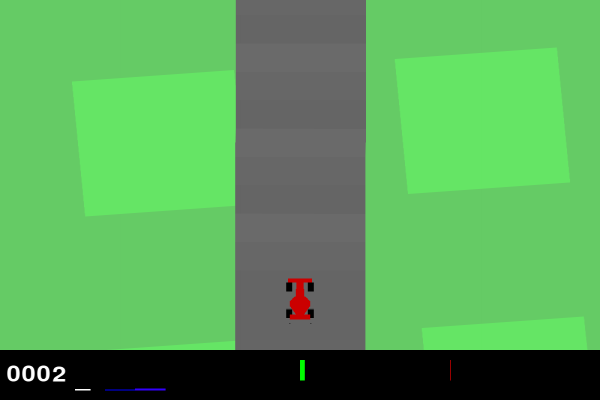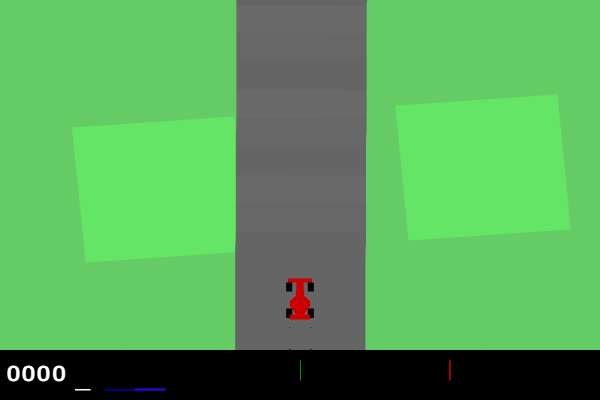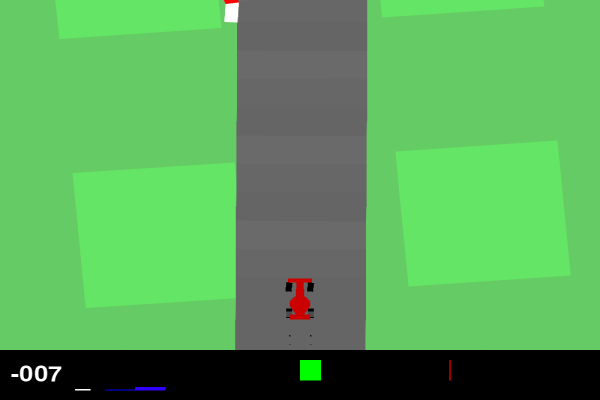
An RL agent needs to be trained for the car to be on racetrack and complete the race.
There are 3 actions that can be performed in each state as stated below:
- Accelerate
- Brake
- Steer
Car starts from the racetrack
To prevent car from going out of racetrack. To complete the race within minimum number of steps.
Reward is:
- -0.1 for every frame
- +1000/N for every track tile visited
where,
N = Total number of tiles visited in the track
For example, if agent has finished in 732 frames, reward is
1000 - (0.1 * 732) = 926.8 points
Episode ends when
- All tiles are visited
OR - Car goes outside the play field - that is, far off the track (in which case it will receive -100 reward and die)
- Image (96 X 96 X 3)
- Accelerate
- Range: 0.0 to 1.0
- Minimum Value: 0.0 (For No Acceleration)
- Maximum Value: 1.0 (For Full Acceleration)
- Brake
- Range: 0.0 to 1.0
- Minimum Value: 0.0 (For No Braking)
- Maximum Value: 1.0 (For Full Braking)
- Steer
- Range: -1.0 to 1.0
- Minimum Value: -1.0 (For Full Left Turn)
- Maximum Value: +1.0 (For Full Right Turn)
Size of the memory be 200,000.
This means that you can store 200,000 experiences in memory.
There are 27648 values in each state. Each value in this state corresponds to each pixel in the image.
Thus input to model is as follows
stateis a vector of length 27648, such as [0.1, 2.4, 2.2, 1.0]
Output from the model is as follows:
Q-Valueis a vector of length X. Where X depends on possible action states.