

More and more data scientists run their Nvidia GPU based inference tasks on Kubernetes. Some of these tasks can be run on the same Nvidia GPU device to increase GPU utilization. So one important challenge is how to share GPUs between the pods. The community is also very interested in this topic.
Now there is a GPU sharing solution on native Kubernetes: it is based on scheduler extenders and device plugin mechanism, so you can reuse this solution easily in your own Kubernetes.
- Kubernetes 1.11+
- golang 1.10+
- NVIDIA drivers ~= 361.93
- Nvidia-docker version > 2.0 (see how to install and it's prerequisites)
- Docker configured with Nvidia as the default runtime.
For more details about the design of this project, please read this Design document.
You can follow this Installation Guide. If you are using Alibaba Cloud Kubernetes, please follow this doc to install with Helm Charts.
You can check this User Guide.
git clone https://github.com/alasdairtran/gpushare-scheduler-extender.git && cd gpushare-scheduler-extender
docker build -t cheyang/gpushare-scheduler-extender .git clone https://github.com/alasdairtran/gpushare-device-plugin.git && cd gpushare-device-plugin
docker build -t cheyang/gpushare-device-plugin .- golang > 1.10
mkdir -p $GOPATH/src/github.com/alasdairtran
cd $GOPATH/src/github.com/alasdairtran
git clone https://github.com/alasdairtran/gpushare-device-plugin.git
cd gpushare-device-plugin
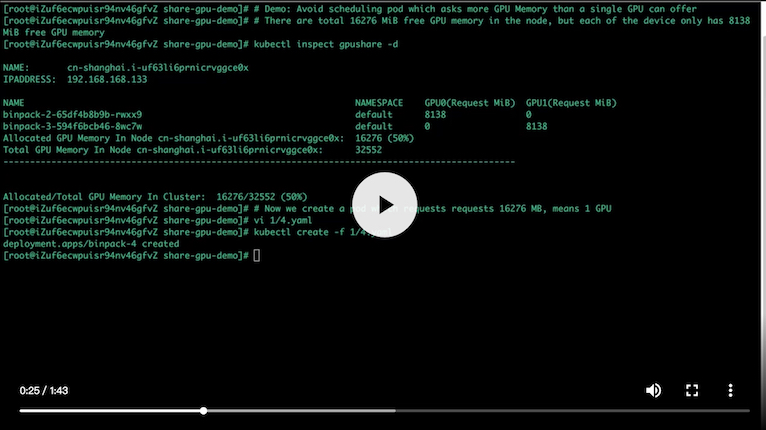
go build -o $GOPATH/bin/kubectl-inspect-gpushare-v2 cmd/inspect/*.go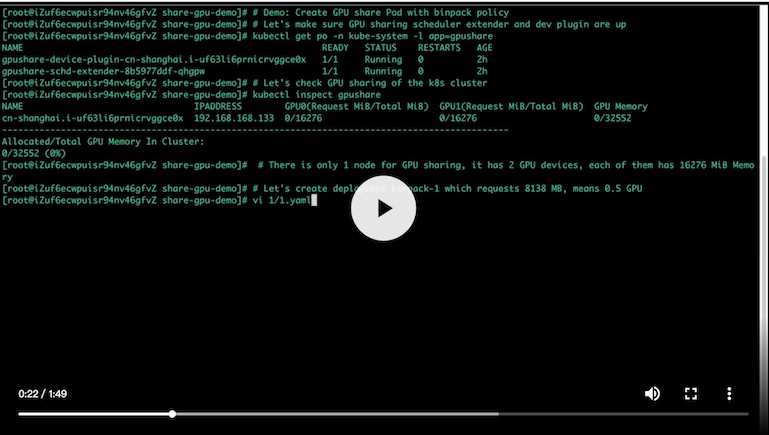
- Integrate Nvidia MPS as the option for isolation
- Automated Deployment for the Kubernetes cluster which is deployed by kubeadm
- Scheduler Extener High Availablity
- Generic Solution for GPU, RDMA and other devices
- GPU sharing solution is based on Nvidia Docker2, and their gpu sharing design is our reference. The Nvidia Community is very supportive and We are very grateful.