Example: single-speech-wordcount.R
library(dplyr)
library(tidytext)
library(ggplot2)
data(stop_words)
Ingest Trump speech
fileText <- scan("trump/speech_0.txt",sep="\n",what="raw")
Place speech text in a dataframe so "tidy" can use it
text_df <- data_frame(text = fileText)
Tokenize text to place 1 token per row and remove common words like "the"
tokenizedText <- text_df %>%
unnest_tokens(word, text) %>%
anti_join(stop_words)
Do a wordcount and organize by most frequent
wordCount <- tokenizedText %>%
count(word, sort = TRUE)
View the table of that wordcount
View(wordCount)
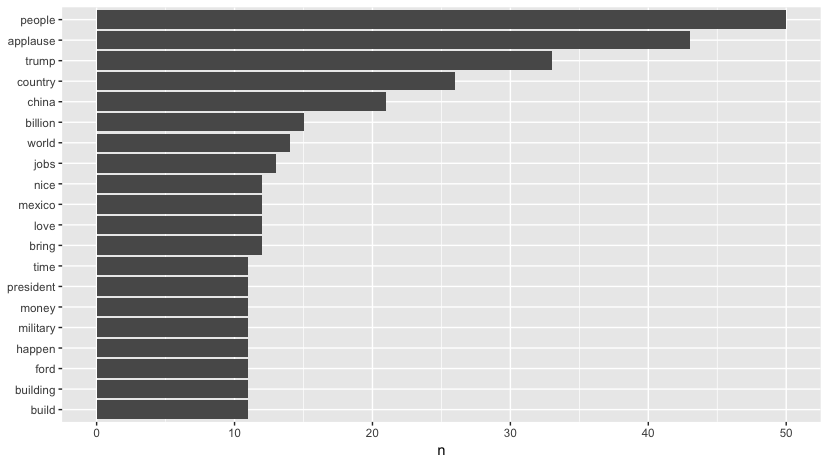
Plot table of most frequently used words (with over 10 mentions)
wordCount %>%
filter(n > 10) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n)) +
geom_col() +
xlab(NULL) +
coord_flip()