传送门:项目ppt
相关依赖安装(若本地环境已有docker和docker-compose可忽略)
pip install -r requirements.txt启动项目
bash startup.sh若出现报错,说明集群未启动完全,可再次运行上述命令
停止项目
docker-compose down注意:
- 若在服务器中运行,需将127.0.0.1或localhost替换为服务器网址才能在主机中访问相关服务。
- 项目启动后需要等待一小段时间才能访问数据分析看板。
访问 http://127.0.0.1:8000/ 进入企业招聘平台。若成功运行,可实现下述服务:
-
可视化数据看板 查看利用当前数据统计分析信息制作的可视化数据看板。
-
基于评论文本情感分类的公司评分
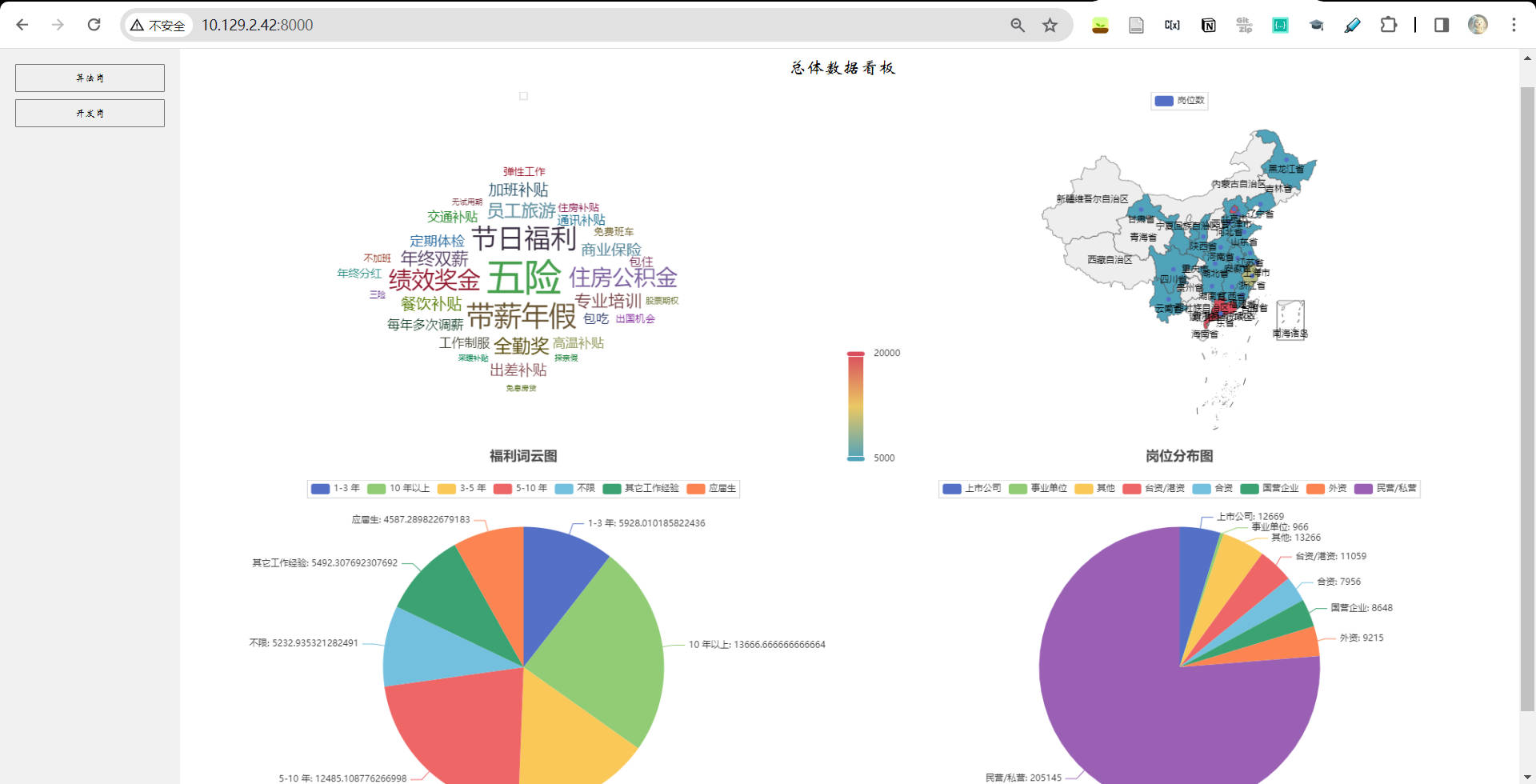
- 点击主页可视化数据看板左上角
算法岗、开发岗选择指定的岗位。 - 右下角图为实时的基于评论文本情感分类的六大公司评分结果。根据实时数据读取方式,待启动服务十天后,每五分钟读取一次最新评论,更新公司得分。

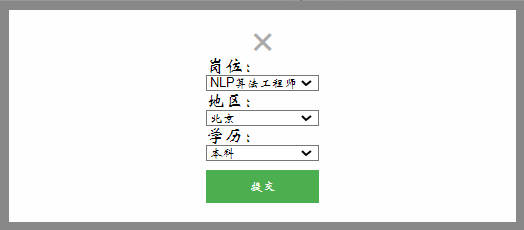
- 薪资预测服务
- 在选定特定岗位后,点击左上角
预测薪资,进入薪资预测服务。 - 选定待预测的岗位、地区、学历信息,页面返回薪资预测结果。
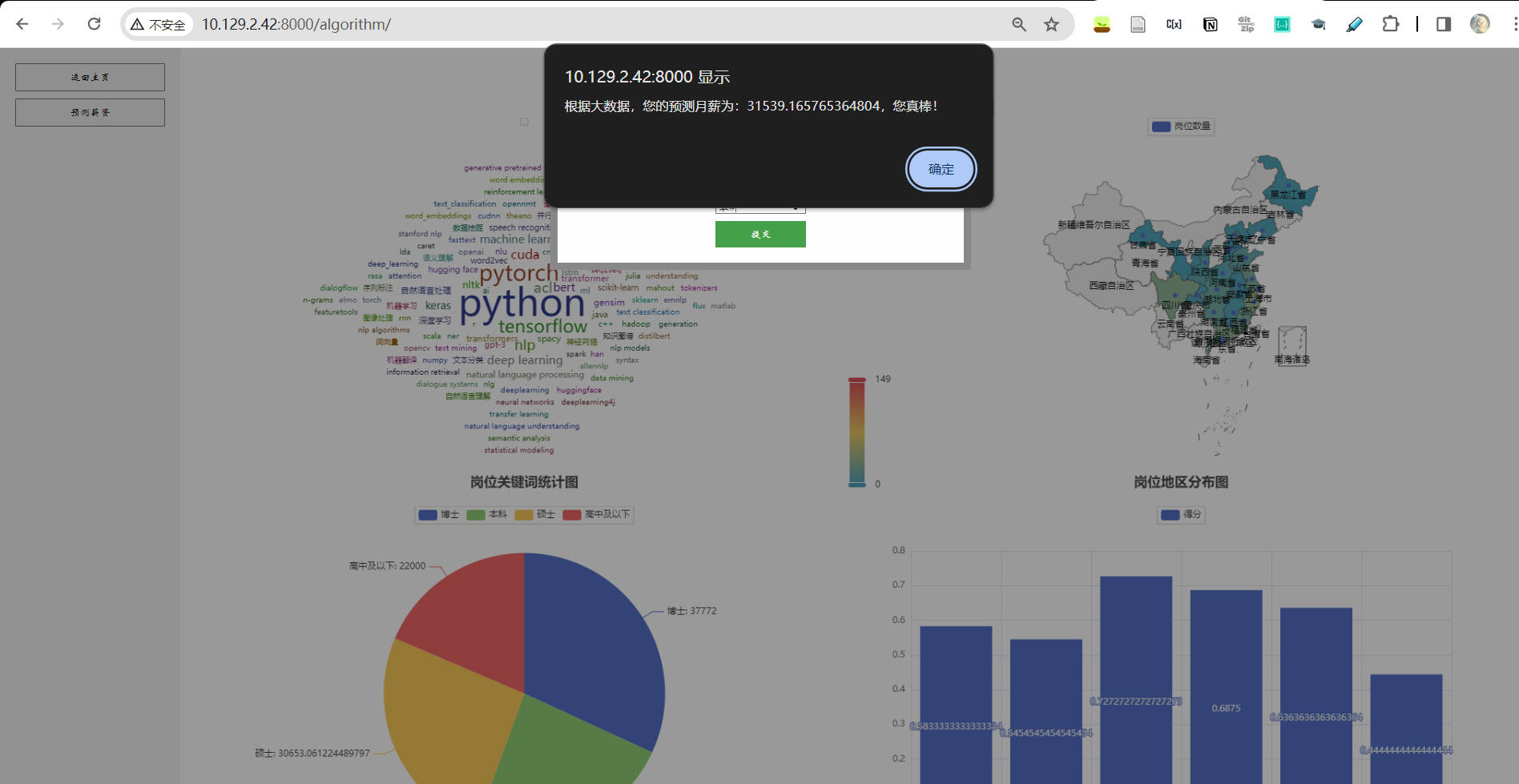
成功运行本项目后,可通过下述对应网址查看大数据生态系统下的相关组件:
- Namenode (HDFS) : http://localhost:9870/dfshealth.html#tab-overview Hadoop 分布式文件系统 (HDFS) 的管理节点,维护文件系统的元数据和目录树的结构
- Datanode (HDFS) : http://localhost:9864/ HDFS工作节点,负责存储实际的数据块
- Spark Master : http://localhost:8080/ Apache Spark 的主节点,负责资源分配和任务调度
- Spark Worker : http://localhost:8081/ Spark 的工作节点,执行由 Spark Master 分配的任务
- ResourceManager (YARN) : http://localhost:8088/cluster 在 YARN中,负责整个集群的资源管理和任务调度
- NodeManager (YARN) : http://localhost:8042/node YARN 的每个节点上的组件,负责管理容器和监控资源使用
- HistoryServer : http://localhost:8188/applicationhistory 存储完成的 Spark 作业的历史信息
- HiveServer2 : http://localhost:10002/ Apache Hive 的服务组件,提供JDBC 接口及其他服务执行 Hive 查询
- Spark Job WebUI : http://localhost:4040/ (当 Spark 任务在 spark-master 运行时才可访问) 当 Spark 任务运行时,用于监控和调试 Spark 作业的 Web 用户界面。
- Hue : http://localhost:8890/
调用前端预测功能后,请稍等片刻,spark集群运行模型需要一定的时间

为了前端内容的顺畅显示,前期我们将数据一次性从hive中导出为csv,而不需每次启动前端调用spark集群。
以导出“公司常见福利词”为例,从hive中导出hql命令如下:
set hive.exec.mode.local.auto=true;
set hive.exec.mode.local.auto.inputbytes.max=52428800;
set hive.exec.mode.local.auto.input.files.max=10;
INSERT OVERWRITE DIRECTORY 'welfare.csv'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
SELECT fl, count(1)
FROM (
SELECT b.fl
FROM job
LATERAL VIEW explode(split(welfare, '、')) b AS fl
) AS a
WHERE fl <> '其他'
GROUP BY fl;