This is a set of scripts for downloading your posts and likes from Tumblr.
The scripts try to download as much as possible, including:
- Every post and like
- All the metadata about a post that's available through the Tumblr API
- Any media files attached to a post (e.g. photos, videos)
I've had these for private use for a while, and in the wake of Tumblr going on a deletion spree, I'm trying to make them usable by other people.
If you're having problems, the easiest way to get my attention is by opening an issue. If you don't have a GitHub account, there are alternative contact details on my website.

Pictured: a group of Tumblr users fleeing the new content moderation policies. Image credit: Wellcome Collection, CC BY.
These scripts are only for personal use. Please don't use them to download posts and then make them publicly accessible without consent. Your own blog is yours to do what you want with; your likes and other people's posts are not.
Some of what's on Tumblr is deeply personal content, and is either private or requires a login. Don't put it somewhere where the original creator can't control how it's presented or whether it's visible.
-
Install Python 3.6 or later. Instructions on the Python website.
-
Check you have pip installed by running the following command at a command prompt:
$ pip3 --version pip 18.1 (python 3.6)
If you don't have it installed or the command errors, follow the pip installation instructions
-
Clone this repository:
$ git clone https://github.com/alexwlchan/backup_tumblr.git $ cd backup_tumblr
-
Install the Python dependencies:
$ pip3 install -r requirements.txt -
Get yourself a Tumblr API key by registering an app at https://www.tumblr.com/oauth/apps.
If you haven't done it before, start by clicking the Register application button:

Then fill in the details for your app. Here's an example of what you could use (but put your own email address!):
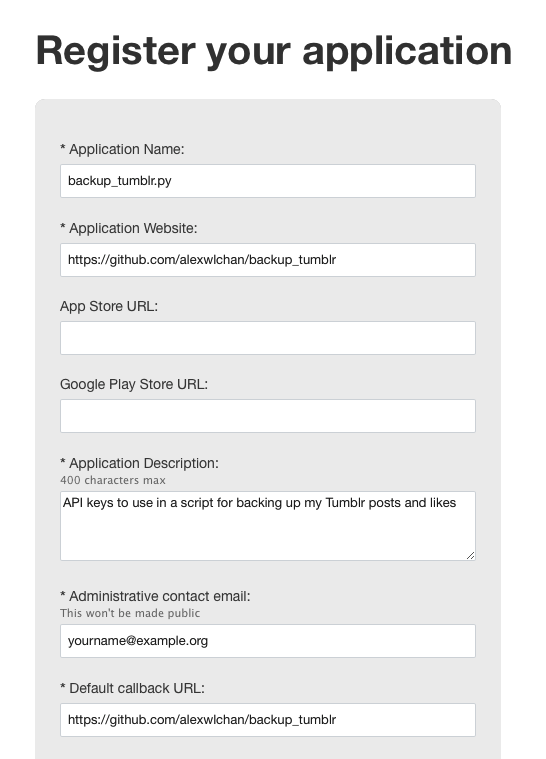
You can leave everything else blank. Then scroll down and hit the "Register" button.
Note: unless you have a lot of posts (20k or more), you shouldn't need to ask for a rate limit removal.
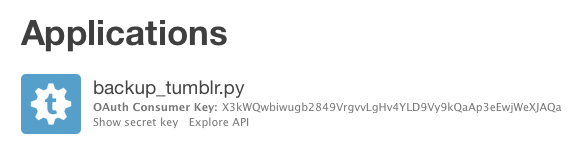
Once you've registered, you'll have a new entry in the list of applications. You need the OAuth Consumer Key:
-
If you're saving your likes, make your likes public by visiting
https://www.tumblr.com/settings/blog/BLOGNAME, and turning on the "Share posts you like" setting:
Otherwise the script can't see them!





There are three scripts in this repo:
save_posts_metadata.pysaves metadata about all the posts on your blog.save_likes_metadata.pysaves metadata about all the posts you've liked.save_media_files.pysaves all the media (images, videos, etc.) from those posts.
They're split into separate scripts because saving metadata is much faster than media files.
You should run (1) and/or (2), then run (3). Something like:
$ python3 save_posts_metadata.py
$ python3 save_likes_metadata.py
$ python3 save_media_files.pyIf you know what command-line flags are: you can pass arguments (e.g. API key) as flags.
Use --help to see the available flags.
If that sentence meant nothing: don't worry, the scripts will ask you for any information they need.
-
I have no idea how Tumblr's content blocks interact with the API, or if blocked posts are visible through the API.
-
I've seen mixed reports saying that ordering in the dashboard has been broken for the last few days. Again, no idea how this interacts with the API.
-
Media files can get big. I have ~12k likes which are taking ~9GB of disk space. The scripts will merrily fill up your disk, so make sure you have plenty of space before you start!
-
These scripts are provided "as is". File an issue if you have a problem, but I don't have much time for maintenance right now.
-
Sometimes the Tumblr API claims to have more posts than it actually returns, and the effect is that the script appears to stop early, e.g. at 96%.
I'm reading the
total_postsparameter from the API responses, and paginating through it as expected -- I have no idea what causes the discrepancy.
These scripts only save the raw API responses and media files.
It doesn't create a pretty index, or interface, or make it especially searchable. I like saving the complete response because it gives me as much flexibility as possible, but it means you need more work to do something useful later.
If you're looking for a more full-featured, well-documented project, I've heard good things about bbolli/tumblr-utils.
Hat tip to @cesy for nudging me to post it, and providing useful feedback on the initial version.
MIT.