"Oh l'ami" - French for "Hi friend!"
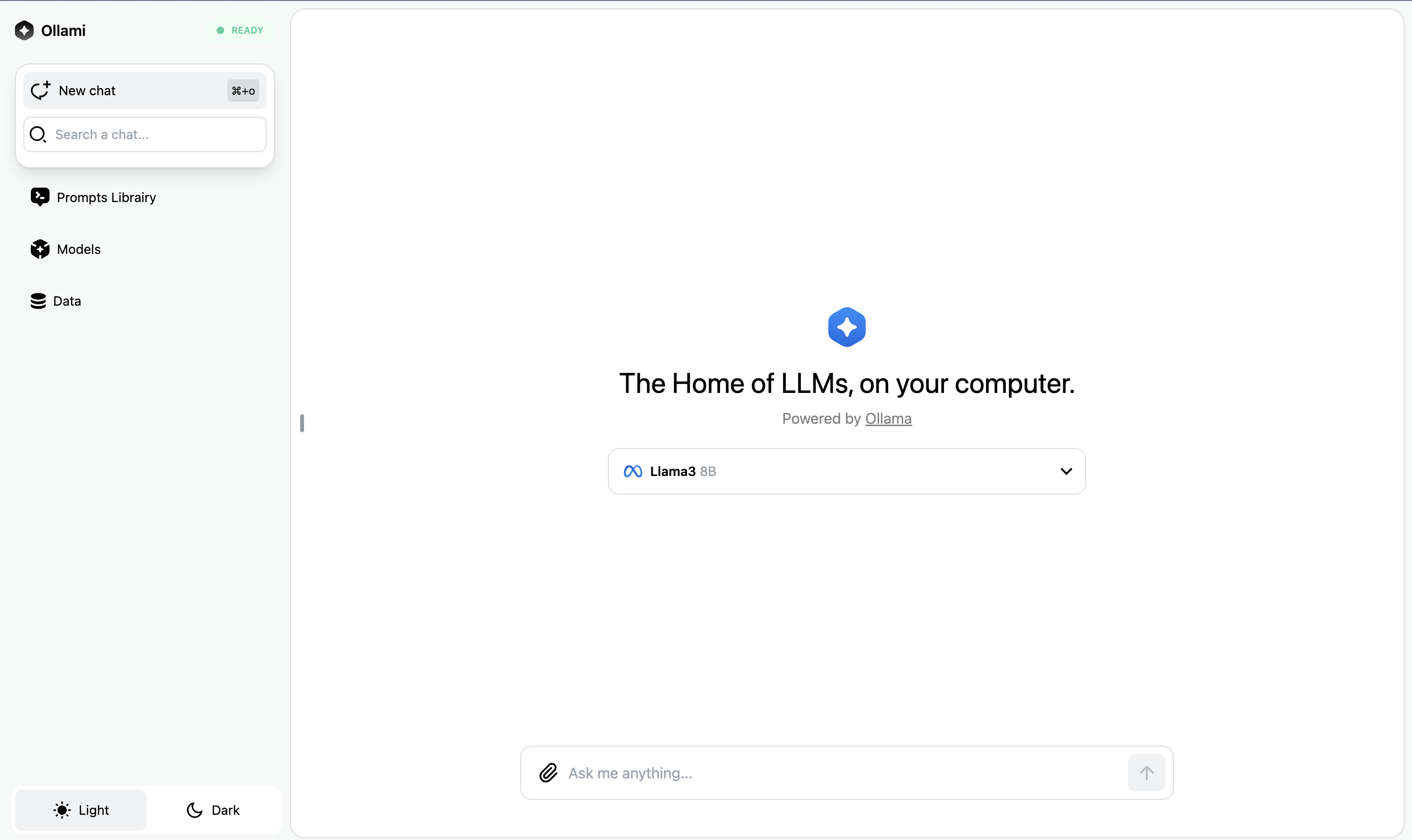
Ollami is a frontend application designed to interact with local Ollama models for text generation, reasoning, chat and more.
Why Use Ollami? 💡
- Save time and resources by running your favorite models directly on your machine.
- Quickly access and interact with a wide range of models, available directly in the interface.
- Seamlessly test and evaluate local model performance in a real-world application context.
Get up and running with large language models locally: Ollama Website.
curl -fsSL https://ollama.com/install.sh | shOpen your favorite terminal, and run the following commands:
ollama run llama3:latestThat's it! Your first model is up and running!
Note
This guide assumes that you have Docker Desktop installed locally. If not please install Docker
Clone the repository with git to your local machine development folder using the following command:
git clone https://github.com/aetaix/ollami.git ollami
cd ollamiMake sure Docker Desktop is open, then run the following command:
docker compose up -dGo to localhost:5050 to access Ollami!
Note
This guide assumes that you have installed the latest version of Node.js and npm. If not : Download Node.js (Node.js + npm)
Clone the repository to your local machine development folder using the following command:
git clone https://github.com/aetaix/ollami.git ollami
cd ollamiInstall packages and start the app:
npm installLaunch the app:
npm run devTip
No need to add .env variable, the app will use the default Ollama server locally started while using the ollama run command. By default the server is running on http://127.0.0.1:11434
Ollami have a built in library of available models that can be downloaded and run locally.

Of course, take the time to explore the different models available and choose the one that best suits your needs.
Here are some example models that can be downloaded:
| Model | Parameters | Size | Download |
|---|---|---|---|
| Llama 3 | 7B | 3.8GB | ollama run llama3 |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Phi-3 | 3.8B | 2.3GB | ollama run phi3 |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b |
| Orca Mini | 3B | 1.9GB | ollama run orca-mini |
| Vicuna | 7B | 3.8GB | ollama run vicuna |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Gemma | 2B | 1.4GB | ollama run gemma:2b |
| Gemma | 7B | 4.8GB | ollama run gemma:7b |
Tip
You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.