A tool for running large language models on-premises using non-public data
OnPrem.LLM is a simple Python package that makes it easier to run large language models (LLMs) on your own machines using non-public data (possibly behind corporate firewalls). Inspired largely by the privateGPT GitHub repo, OnPrem.LLM is intended to help integrate local LLMs into practical applications.
The full documentation is here.
A Google Colab demo of installing and using OnPrem.LLM is here.
Latest News 🔥
-
[2024/10] v0.3.0 released and now includes support for concept-focused summarization
-
[2024/09] v0.2.0 released and now includes PDF OCR support and better PDF table handling.
-
[2024/06] v0.1.0 of OnPrem.LLM has been released. Lots of new updates!
- Ability to use with any OpenAI-compatible API (e.g., vLLM, Ollama, OpenLLM, etc.).
- Pipeline for information extraction from raw documents.
- Pipeline for few-shot text classification (i.e., training a classifier on a tiny number of labeled examples) along with the ability to explain few-shot predictions.
- Default model changed to Mistral-7B-Instruct-v0.2
- API augmentations and bug fixes
Once you have installed PyTorch, you can install OnPrem.LLM with the following steps:
-
Install llama-cpp-python by visiting this site and following instructions for your operating system and machine. For CPU-based installations (i.e., no GPU acceleration), you can simply do:
pip install llama-cpp-python. -
Install OnPrem.LLM:
pip install onprem
For fast GPU-accelerated inference, see additional instructions below. See the FAQ, if you experience issues with llama-cpp-python installation.
Note: If using OnPrem.LLM with an LLM being served through an
external REST
API
(e.g., vLLM, OpenLLM, Ollama), installation of llama-cpp-python is
optional. You will only be asked to install it if attempting to use a
locally installed model directly.
from onprem import LLM
llm = LLM()By default, a 7B-parameter model (Mistral-7B-Instruct-v0.2) is
downloaded and used. If use_zephyr=True is supplied, a
Zephyr-7B-beta model is automatically used (which is useful if the
default Mistral model struggles with a particular task). Of course, you
can also easily supply the URL to an LLM of your choosing to
LLM (see the code
generation section
below for an
example or the FAQ). Any extra
parameters supplied to
LLM are forwarded
directly to llama-cpp-python.
This is an example of few-shot prompting, where we provide an example of what we want the LLM to do.
prompt = """Extract the names of people in the supplied sentences. Here is an example:
Sentence: James Gandolfini and Paul Newman were great actors.
People:
James Gandolfini, Paul Newman
Sentence:
I like Cillian Murphy's acting. Florence Pugh is great, too.
People:"""
saved_output = llm.prompt(prompt) Cillian Murphy, Florence Pugh.
Additional prompt examples are shown here.
Answers are generated from the content of your documents (i.e., retrieval augmented generation or RAG). Here, we will use GPU offloading to speed up answer generation using the default model. However, the Zephyr-7B model may perform even better, responds faster, and is used in our example notebook.
from onprem import LLM
llm = LLM(n_gpu_layers=-1)llm.ingest("./sample_data")Creating new vectorstore at /home/amaiya/onprem_data/vectordb
Loading documents from ./sample_data
Loaded 12 new documents from ./sample_data
Split into 153 chunks of text (max. 500 chars each)
Creating embeddings. May take some minutes...
Ingestion complete! You can now query your documents using the LLM.ask or LLM.chat methods
Loading new documents: 100%|██████████████████████| 3/3 [00:00<00:00, 13.71it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:02<00:00, 2.49s/it]
question = """What is ktrain?"""
result = llm.ask(question) Ktrain is a low-code machine learning library designed to facilitate the full machine learning workflow from curating and preprocessing inputs to training, tuning, troubleshooting, and applying models. Ktrain is well-suited for domain experts who may have less experience with machine learning and software coding.
The sources used by the model to generate the answer are stored in
result['source_documents']:
print("\nSources:\n")
for i, document in enumerate(result["source_documents"]):
print(f"\n{i+1}.> " + document.metadata["source"] + ":")
print(document.page_content)Sources:
1.> /home/amaiya/projects/ghub/onprem/nbs/sample_data/1/ktrain_paper.pdf:
lection (He et al., 2019). By contrast, ktrain places less emphasis on this aspect of au-
tomation and instead focuses on either partially or fully automating other aspects of the
machine learning (ML) workflow. For these reasons, ktrain is less of a traditional Au-
2
2.> /home/amaiya/projects/ghub/onprem/nbs/sample_data/1/ktrain_paper.pdf:
possible, ktrain automates (either algorithmically or through setting well-performing de-
faults), but also allows users to make choices that best fit their unique application require-
ments. In this way, ktrain uses automation to augment and complement human engineers
rather than attempting to entirely replace them. In doing so, the strengths of both are
better exploited. Following inspiration from a blog post1 by Rachel Thomas of fast.ai
3.> /home/amaiya/projects/ghub/onprem/nbs/sample_data/1/ktrain_paper.pdf:
with custom models and data formats, as well.
Inspired by other low-code (and no-
code) open-source ML libraries such as fastai (Howard and Gugger, 2020) and ludwig
(Molino et al., 2019), ktrain is intended to help further democratize machine learning by
enabling beginners and domain experts with minimal programming or data science experi-
4. http://archive.ics.uci.edu/ml/datasets/Twenty+Newsgroups
6
4.> /home/amaiya/projects/ghub/onprem/nbs/sample_data/1/ktrain_paper.pdf:
ktrain: A Low-Code Library for Augmented Machine Learning
toML platform and more of what might be called a “low-code” ML platform. Through
automation or semi-automation, ktrain facilitates the full machine learning workflow from
curating and preprocessing inputs (i.e., ground-truth-labeled training data) to training,
tuning, troubleshooting, and applying models. In this way, ktrain is well-suited for domain
experts who may have less experience with machine learning and software coding. Where
Summarize your raw documents (e.g., PDFs, MS Word) with an LLM.
Summarize each chunk in a document and then generate a single summary from the individual summaries.
from onprem import LLM
llm = LLM(n_gpu_layers=-1, verbose=False, mute_stream=True) # disabling viewing of intermediate summarization prompts/inferencesfrom onprem.pipelines import Summarizer
summ = Summarizer(llm)
resp = summ.summarize('sample_data/1/ktrain_paper.pdf', max_chunks_to_use=5) # omit max_chunks_to_use parameter to consider entire document
print(resp['output_text']) Ktrain is an open-source machine learning library that offers a unified interface for various machine learning tasks. The library supports both supervised and non-supervised machine learning, and includes methods for training models, evaluating models, making predictions on new data, and providing explanations for model decisions. Additionally, the library integrates with various explainable AI libraries such as shap, eli5 with lime, and others to provide more interpretable models.
Summarize a large document with respect to a particular concept of interest.
from onprem import LLM
from onprem.pipelines import Summarizerllm = LLM(use_zephyr=True, n_gpu_layers=-1, verbose=False)
summ = Summarizer(llm)
summary, sources = summ.summarize_by_concept('sample_data/1/ktrain_paper.pdf', concept_description="question answering")The context provided describes the implementation of an open-domain question-answering system using ktrain, a low-code library for augmented machine learning. The system follows three main steps: indexing documents into a search engine, locating documents containing words in the question, and extracting candidate answers from those documents using a BERT model pretrained on the SQuAD dataset. Confidence scores are used to sort and prune candidate answers before returning results. The entire workflow can be implemented with only three lines of code using ktrain's SimpleQA module. This system allows for the submission of natural language questions and receives exact answers, as demonstrated in the provided example. Overall, the context highlights the ease and accessibility of building sophisticated machine learning models, including open-domain question-answering systems, through ktrain's low-code interface.
Extract information from raw documents (e.g., PDFs, MS Word documents) with an LLM.
from onprem import LLM
from onprem.pipelines import Extractor
# Notice that we're using a cloud-based, off-premises model here! See "OpenAI" section below.
llm = LLM(model_url='openai://gpt-3.5-turbo', verbose=False, mute_stream=True, temperature=0)
extractor = Extractor(llm)
prompt = """Extract the names of research institutions (e.g., universities, research labs, corporations, etc.)
from the following sentence delimited by three backticks. If there are no organizations, return NA.
If there are multiple organizations, separate them with commas.
```{text}```
"""
df = extractor.apply(prompt, fpath='sample_data/1/ktrain_paper.pdf', pdf_pages=[1], stop=['\n'])
df.loc[df['Extractions'] != 'NA'].Extractions[0]/home/amaiya/projects/ghub/onprem/onprem/core.py:159: UserWarning: The model you supplied is gpt-3.5-turbo, an external service (i.e., not on-premises). Use with caution, as your data and prompts will be sent externally.
warnings.warn(f'The model you supplied is {self.model_name}, an external service (i.e., not on-premises). '+\
'Institute for Defense Analyses'
Make accurate text classification predictions using only a tiny number of labeled examples.
# create classifier
from onprem.pipelines import FewShotClassifier
clf = FewShotClassifier(use_smaller=True)
# Fetching data
from sklearn.datasets import fetch_20newsgroups
import pandas as pd
import numpy as np
classes = ["soc.religion.christian", "sci.space"]
newsgroups = fetch_20newsgroups(subset="all", categories=classes)
corpus, group_labels = np.array(newsgroups.data), np.array(newsgroups.target_names)[newsgroups.target]
# Wrangling data into a dataframe and selecting training examples
data = pd.DataFrame({"text": corpus, "label": group_labels})
train_df = data.groupby("label").sample(5)
test_df = data.drop(index=train_df.index)
# X_sample only contains 5 examples of each class!
X_sample, y_sample = train_df['text'].values, train_df['label'].values
# test set
X_test, y_test = test_df['text'].values, test_df['label'].values
# train
clf.train(X_sample, y_sample, max_steps=20)
# evaluate
print(clf.evaluate(X_test, y_test)['accuracy'])
#output: 0.98
# make predictions
clf.predict(['Elon Musk likes launching satellites.']).tolist()[0]
#output: sci.spaceWe’ll use the CodeUp LLM by supplying the URL and employing the particular prompt format this model expects.
from onprem import LLM
url = "https://huggingface.co/TheBloke/CodeUp-Llama-2-13B-Chat-HF-GGUF/resolve/main/codeup-llama-2-13b-chat-hf.Q4_K_M.gguf"
llm = LLM(url, n_gpu_layers=-1) # see below for GPU informationSetup the prompt based on what this model expects (this is important):
template = """
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:"""You can supply the prompte_template to either the
LLM constructor
(above) or the
LLM.prompt
method. We will do the latter here:
answer = llm.prompt(
"Write Python code to validate an email address.", prompt_template=template
)Here is an example of Python code that can be used to validate an email address:
```
import re
def validate_email(email):
# Use a regular expression to check if the email address is in the correct format
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'
if re.match(pattern, email):
return True
else:
return False
# Test the validate_email function with different inputs
print("Email address is valid:", validate_email("example@example.com")) # Should print "True"
print("Email address is invalid:", validate_email("example@")) # Should print "False"
print("Email address is invalid:", validate_email("example.com")) # Should print "False"
```
The code defines a function `validate_email` that takes an email address as input and uses a regular expression to check if the email address is in the correct format. The regular expression checks for an email address that consists of one or more letters, numbers, periods, hyphens, or underscores followed by the `@` symbol, followed by one or more letters, periods, hyphens, or underscores followed by a `.` and two to three letters.
The function returns `True` if the email address is valid, and `False` otherwise. The code also includes some test examples to demonstrate how to use the function.
Let’s try out the code generated above.
import re
def validate_email(email):
# Use a regular expression to check if the email address is in the correct format
pattern = r"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$"
if re.match(pattern, email):
return True
else:
return False
print(validate_email("sam@@openai.com")) # bad email address
print(validate_email("sam@openai")) # bad email address
print(validate_email("sam@openai.com")) # good email addressFalse
False
True
The generated code may sometimes need editing, but this one worked out-of-the-box.
OnPrem.LLM can be used with LLMs being served through any OpenAI-compatible REST API. This means you can easily use OnPrem.LLM with tools like vLLM, OpenLLM, Ollama, and the llama.cpp server.
For instance, using vLLM, you can serve a LLaMA 3 model as follows:
python -m vllm.entrypoints.openai.api_server --model NousResearch/Meta-Llama-3-8B-Instruct --dtype auto --api-key token-abc123You can then connect OnPrem.LLM to the LLM by supplying the URL of the server you just started:
from onprem import LLM
llm = LLM(model_url='http://localhost:8000/v1', api_key='token-abc123')
# Note: The API key can either be supplied directly or stored in the OPENAI_API_KEY environment variable.
# If the server does not require an API key, `api_key` should still be supplied with a dummy value like 'na'.That’s it! Solve problems with OnPrem.LLM as you normally would (e.g., RAG question-answering, summarization, few-shot prompting, code generation, etc.).
Even when using on-premises language models, it can sometimes be useful to have easy access to non-local, cloud-based models (e.g., OpenAI) for testing, producing baselines for comparison, and generating synthetic examples for fine-tuning. For these reasons, in spite of the name, OnPrem.LLM now includes support for OpenAI chat models:
from onprem import LLM
llm = LLM(model_url='openai://gpt-3.5-turbo', temperature=0) # ChatGPT/home/amaiya/projects/ghub/onprem/onprem/core.py:138: UserWarning: The model you supplied is gpt-3.5-turbo, an external service (i.e., not on-premises). Use with caution, as your data and prompts will be sent externally.
warnings.warn(f'The model you supplied is {self.model_name}, an external service (i.e., not on-premises). '+\
saved_result = llm.prompt('List three cute names for a cat and explain why each is cute.')1. Whiskers: Whiskers is a cute name for a cat because it perfectly describes one of the most adorable features of a feline - their long, delicate whiskers. It's a playful and endearing name that captures the essence of a cat's charm.
2. Pudding: Pudding is an incredibly cute name for a cat because it evokes a sense of softness and sweetness. Just like a bowl of creamy pudding, this name brings to mind a cat's cuddly and lovable nature. It's a name that instantly makes you want to snuggle up with your furry friend.
3. Muffin: Muffin is an adorable name for a cat because it conjures up images of something small, round, and irresistibly cute - just like a cat! This name is playful and charming, and it perfectly captures the delightful and lovable nature of our feline companions.
Azure OpenAI
For Azure OpenAI models, use the following URL format:
llm = LLM(model_url='azure://<deployment_name>', ...)
# <deployment_name> is the Azure deployment name and additional Azure-specific parameters
# can be supplied as extra arguments to LLM (or set as environment variables)You can use OnPrem.LLM with the Guidance package to guide the LLM to generate outputs based on your conditions and constraints. We’ll show a couple of examples here, but see our documentation on guided prompts for more information.
from onprem import LLM
llm = LLM(n_gpu_layers=-1, verbose=False)
from onprem.guider import Guider
guider = Guider(llm)With the Guider, you can use use Regular Expressions to control LLM generation:
prompt = f"""Question: Luke has ten balls. He gives three to his brother. How many balls does he have left?
Answer: """ + gen(name='answer', regex='\d+')
guider.prompt(prompt, echo=False){'answer': '7'}
prompt = '19, 18,' + gen(name='output', max_tokens=50, stop_regex='[^\d]7[^\d]')
guider.prompt(prompt)19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8,
{'output': ' 17, 16, 15, 14, 13, 12, 11, 10, 9, 8,'}
See the documentation for more examples of how to use Guidance with OnPrem.LLM.
OnPrem.LLM includes a built-in Web app to access the LLM. To start it, run the following command after installation:
onprem --port 8000Then, enter localhost:8000 (or <domain_name>:8000 if running on
remote server) in a Web browser to access the application:
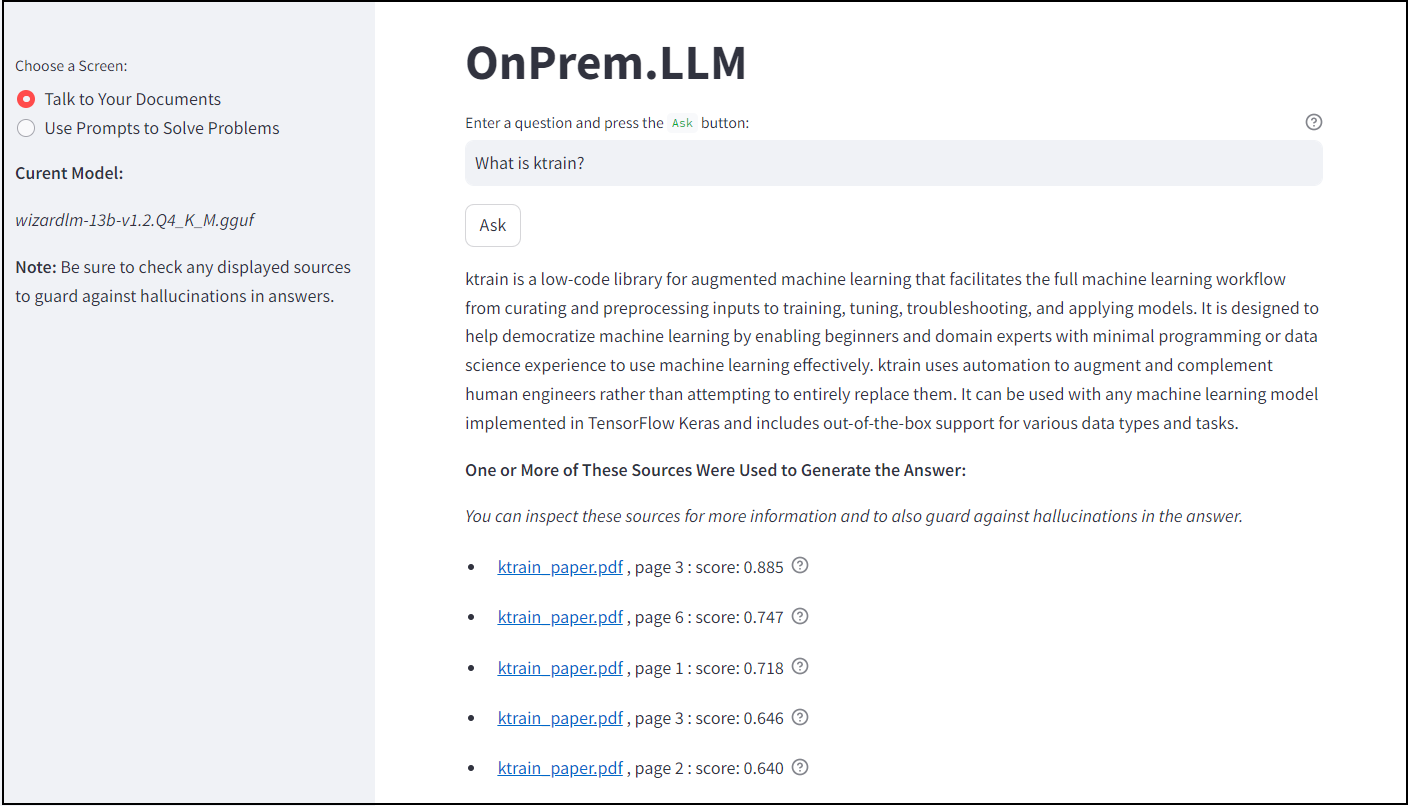
For more information, see the corresponding documentation.
The above example employed the use of a CPU. If you have a GPU (even an
older one with less VRAM), you can speed up responses. See the
LangChain docs on
LLama.cpp
for installing llama-cpp-python with GPU support for your system.
The steps below describe installing and using llama-cpp-python with
cuBLAS support and can be employed for GPU acceleration on systems
with NVIDIA GPUs (e.g., Linux, WSL2, Google Colab).
CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir
# For Mac users replace above with:
# CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dirStep 2: Use the n_gpu_layers argument with LLM
llm = LLM(n_gpu_layers=35)The value for n_gpu_layers depends on your GPU memory and the model
you’re using (e.g., max of 33 for default 7B model). Set
n_gpu_layers=-1 to offload all layers to the GPU (this will offload
all 33 layers to the default model). You can reduce the value if you get
an error (e.g., CUDA error: out-of-memory). For instance, using two
old NVDIDIA TITAN V GPUs each with 12GB of VRAM, 59 out 83 layers in a
quantized Llama-2 70B
model
can be offloaded to the GPUs (i.e., 60 layers or more results in a “CUDA
out of memory” error).
With the steps above, calls to methods like llm.prompt will offload
computation to your GPU and speed up responses from the LLM.
The above assumes that NVIDIA drivers and the CUDA toolkit are already installed. On Ubuntu Linux systems, this can be accomplished with a single command.
-
How do I use other models with OnPrem.LLM?
You can supply the URL to other models to the
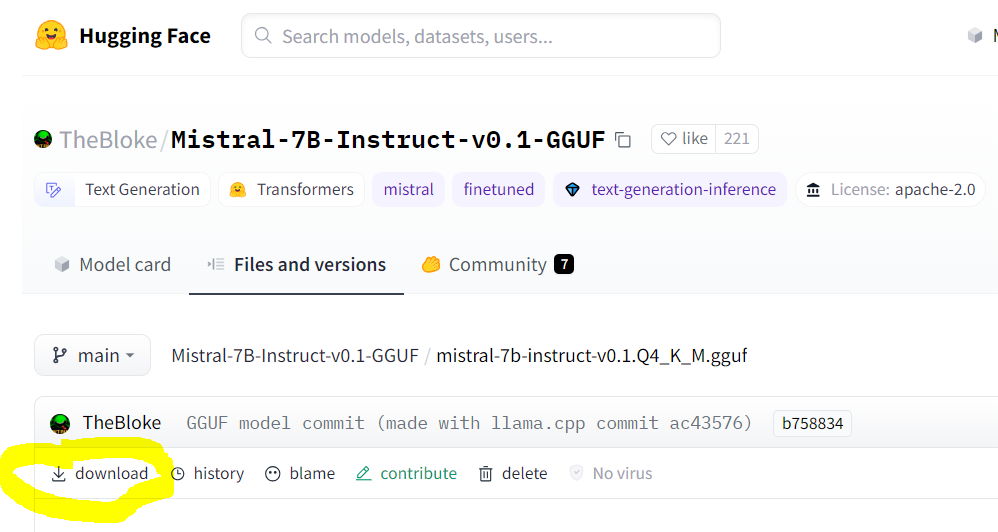
LLMconstructor, as we did above in the code generation example.As of v0.0.20, we support models in GGUF format, which supersedes the older GGML format. You can find llama.cpp-supported models with
GGUFin the file name on huggingface.co.Make sure you are pointing to the URL of the actual GGUF model file, which is the “download” link on the model’s page. An example for Mistral-7B is shown below:
Note that some models have specific prompt formats. For instance, the prompt template required for Zephyr-7B, as described on the model’s page, is:
<|system|>\n</s>\n<|user|>\n{prompt}</s>\n<|assistant|>So, to use the Zephyr-7B model, you must supply the
prompt_templateargument to theLLMconstructor (or specify it in thewebapp.ymlconfiguration for the Web app).# how to use Zephyr-7B with OnPrem.LLM llm = LLM(model_url='https://huggingface.co/TheBloke/zephyr-7B-beta-GGUF/resolve/main/zephyr-7b-beta.Q4_K_M.gguf', prompt_template = "<|system|>\n</s>\n<|user|>\n{prompt}</s>\n<|assistant|>", n_gpu_layers=33) llm.prompt("List three cute names for a cat.")
-
I’m behind a corporate firewall and am receiving an SSL error when trying to download the model?
Try this:
from onprem import LLM LLM.download_model(url, ssl_verify=False)
You can download the embedding model (used by
LLM.ingestandLLM.ask) as follows:wget --no-check-certificate https://public.ukp.informatik.tu-darmstadt.de/reimers/sentence-transformers/v0.2/all-MiniLM-L6-v2.zip
Supply the unzipped folder name as the
embedding_model_nameargument toLLM. -
How do I use this on a machine with no internet access?
Use the
LLM.download_modelmethod to download the model files to<your_home_directory>/onprem_dataand transfer them to the same location on the air-gapped machine.For the
ingestandaskmethods, you will need to also download and transfer the embedding model files:from sentence_transformers import SentenceTransformer model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2') model.save('/some/folder')
Copy the
some/folderfolder to the air-gapped machine and supply the path toLLMvia theembedding_model_nameparameter. -
When installing
onprem, I’m getting errors related tollama-cpp-pythonon Windows/Mac/Linux?See this LangChain documentation on LLama.cpp for help on installing the
llama-cpp-pythonpackage for your system. Additional tips for different operating systems are shown below:For Linux systems like Ubuntu, try this:
sudo apt-get install build-essential g++ clang. Other tips are here.For Windows systems, either use Windows Subsystem for Linux (WSL) or install Microsoft Visual Studio build tools and ensure the selections shown in this post are installed. WSL is recommended.
For Macs, try following these tips.
If you still have problems, there are various other tips for each of the above OSes in this privateGPT repo thread. Of course, you can also easily use OnPrem.LLM on Google Colab.
-
llama-cpp-pythonis failing to load my model from the model path on Google Colab.For reasons that are unclear, newer versions of
llama-cpp-pythonfail to load models on Google Colab unless you supplyverbose=Trueto theLLMconstructor (which is passed directly tollama-cpp-python). If you experience this problem locally, try supplyingverbose=TruetoLLM. -
I’m getting an
“Illegal instruction (core dumped)error when instantiating alangchain.llms.Llamacpporonprem.LLMobject?Your CPU may not support instructions that
cmakeis using for one reason or another (e.g., due to Hyper-V in VirtualBox settings). You can try turning them off when building and installingllama-cpp-python:# example CMAKE_ARGS="-DLLAMA_CUBLAS=ON -DLLAMA_AVX2=OFF -DLLAMA_AVX=OFF -DLLAMA_F16C=OFF -DLLAMA_FMA=OFF" FORCE_CMAKE=1 pip install --force-reinstall llama-cpp-python --no-cache-dir
-
How can I speed up
LLM.ingestusing my GPU?Try using the
embedding_model_kwargsargument:from onprem import LLM llm = LLM(embedding_model_kwargs={'device':'cuda'})